Prototype Pollution In Python
Basic:def merge(src,dic)
原型链的污染的实现需要一个数值合并函数将特定的值污染到类的属性中
标准代码
1 | def merge(src,dst): |
函数解析
hasattr(object,name)
hasattr(object,name)函数用于判断object对象中是否存在name属性;有则True,无则Flase
getattr(object,name)
getattr(object,name)函数用于获取object对象中的name的值
setattr(object,name,value)
setattr(object,name,value)函数用于设置属性的值,且该属性不一定是存在的;如果属性不存在则会创建一个新的属性再对其进行赋值
代码审计
此时我们对上述的标准代码进行一个审计;此时上述代码先自定义了一个函数merge(src,dst)此时的src为源字典,dst为目标字典;然后使用for循环对源字典进行一个遍历键值对;k代表键,v代表值。接下来代码分为三个分支:if hasattr(dst, '__getitem__'):判断目标字典中是否存在__getitem__来判断代码是否为一个可以索引的字典,如果是则在继续进入下一个判断if dst.get(k) and type(v) == dict:,此时进行判断目标字典是否存在键k且值不为None且其值为一个字典;如果是的话则将源字典合并到目标字典中。若不满足if dst.get(k) and type(v) == dict:则直接源字典的值添加到目标字典中。如果不满足if hasattr(dst, '__getitem__')则进入第二个分支判断 elif hasattr(dst, k) and type(v) == dict:此时判断源字典中是否存在与目标字典相同的键k且其值为一个字典,如果满足则递归调用merge()函数将源字典的值加入目标字典。如果上面两个条件都不满足的话直接使用setattr(object,name,value)进行添加
举例分析
此时请看下面这个示例代码
1 | def merge(src,dst): |
所以merge(src.dst)函数的作用就是将源字典中的值继承到了目标字典中;此时若是目标字典中存在与源字典相同的键值都将被源字典替换;而目标字典中没 有存在而源字典中存在的键值都会被补到目标字典之中。
污染示例
污染自定义属性
1 | class father: |
污染过程分析
代码审计层面
第一次递归
此时在执行了merge()之后,因为我们的instance是class类型,并含有__class__默认属性,并且v也为字典格式;所以执行的是
1 | elif hasattr(dst, k) and type(v) == dict: |
所以此时执行第一次递归merge(v,getattr(dsk,k));并且此时的目标通过__class__属性换成了instance对象所属的类son_b
第二次递归
1 | elif hasattr(dst, k) and type(v) == dict: |
在第二次递归之后执行merge(v, getattr(dst, k));此时的目标通过__base__属性转换成了son_b类的所属直接父类
第三次递归
1 | elif hasattr(dst, k) and type(v) == dict: |
污染
在第三次递归时type(v) == dict为Flase;递归结束,此时的v=world不在为字典类型;然后执行语句
1 | else: |
重置father类中的sercrt属性值为Polluted~~~。
断点调试层面
第一次递归
此时我们可以看到我们的payload和instance被当作src和dist传入
1 | dst = <__main__.son_b object at 0x000001EA924A19A0> |
然后进入第一层循环
进入第一层判断;此时已经将payload中的k、v取出
1 | k = '__class__' |
因为此时的v中不存在__getitem所以又转入了下一层的判断
因为此时识别成功判断为True所以进入了递归函数merge()
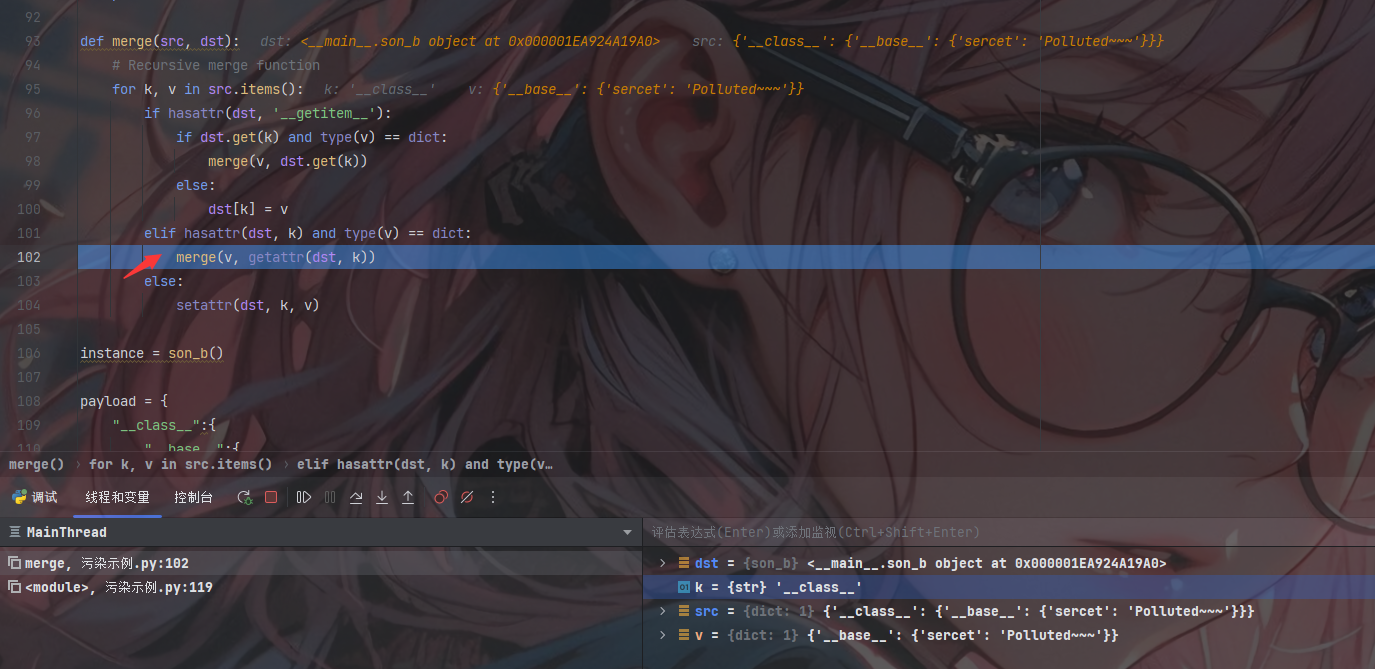
第二次递归
此时将v作为src继续进行
1 | src = {'__base__': {'sercet': 'Polluted~~~'}} |
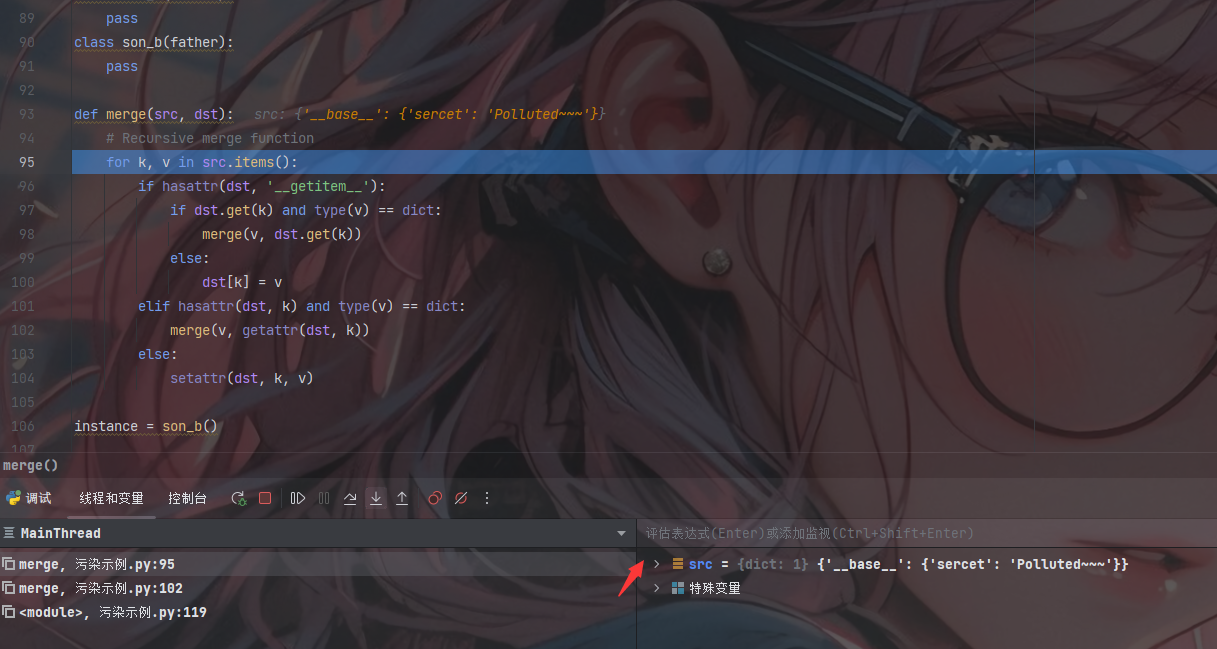
然后此时将k、v的值取出
1 | k = '__base__' |
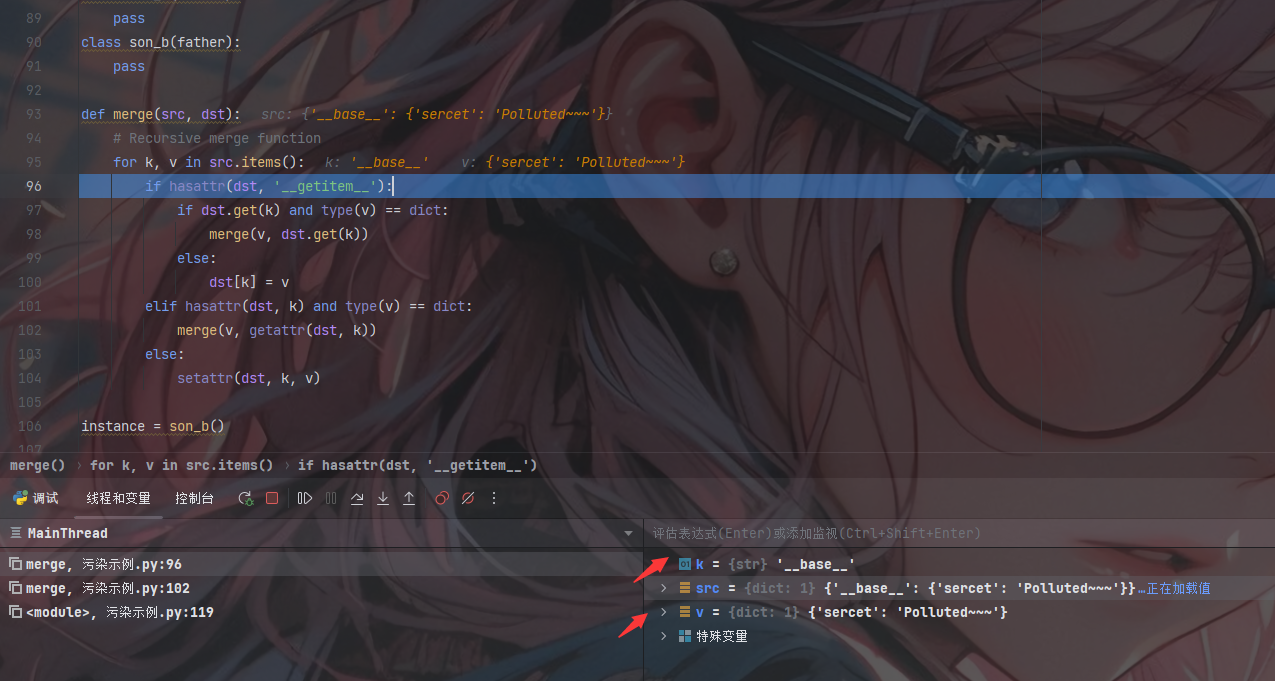
进入第二个判断
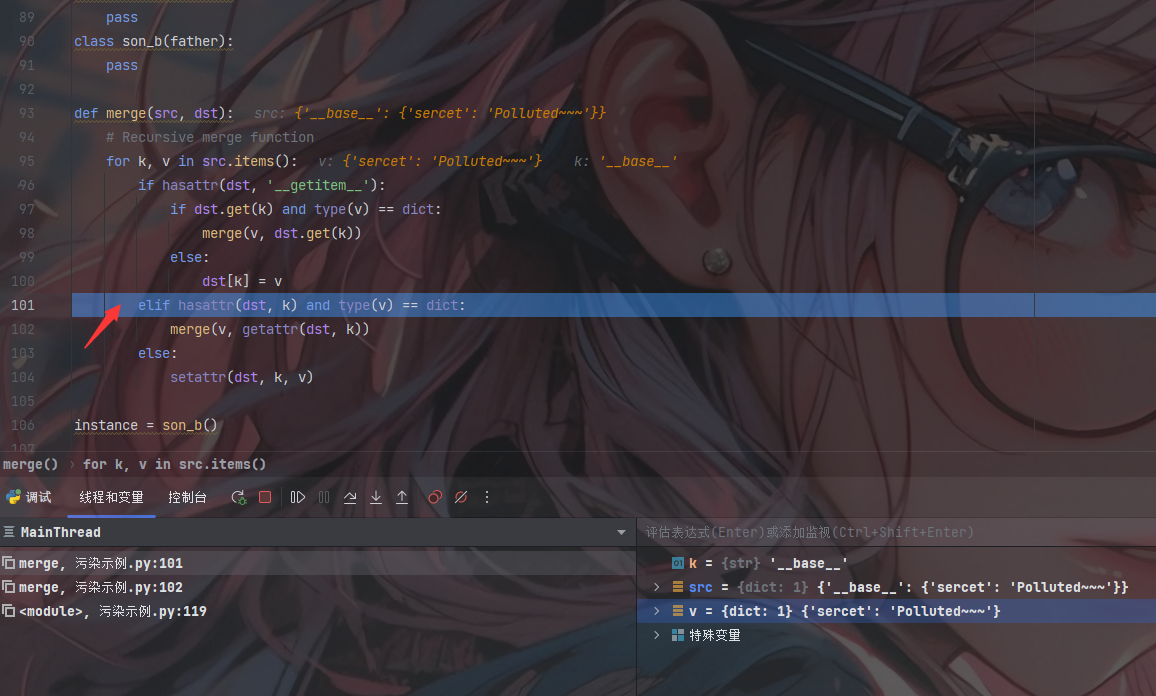
判断成功True;再次进入merge()函数准备第三次的递归
第三次递归
此时将v作为src进行运行
1 | src = {'sercet': 'Polluted~~~'} |
取出k、v的值进入第一次判断
1 | k = 'sercet' |
第一层判断为Flase,进入第二层判断
此时的v已经不在是一个字典了,判断为Flase;转到最后一层的setattr()
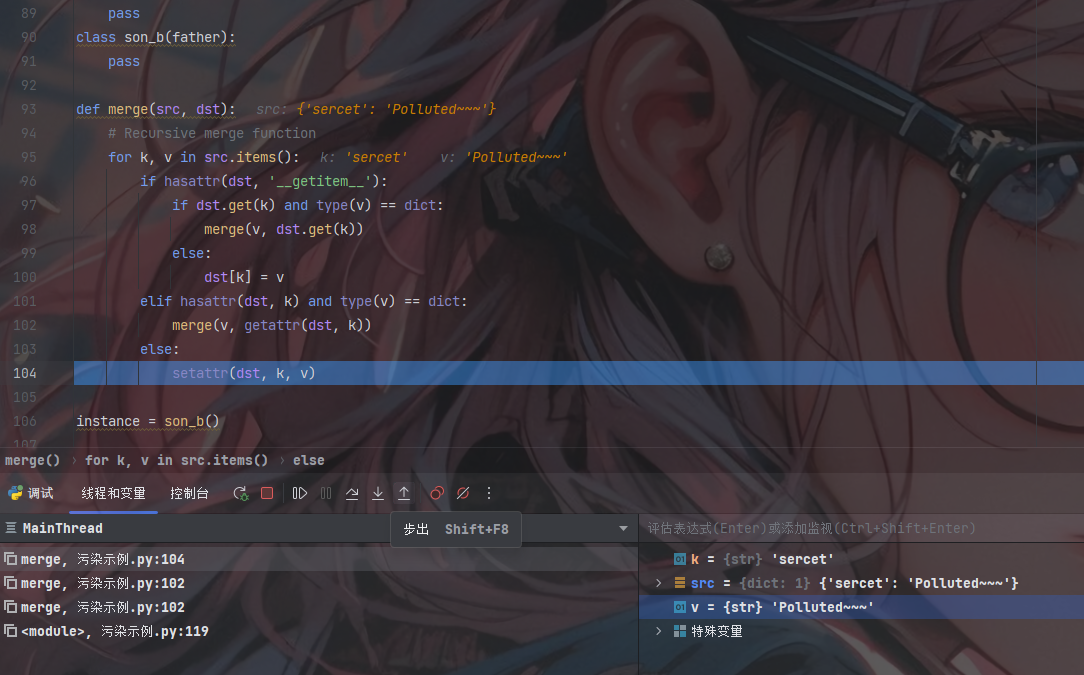
污染
进入了setattr(object,name,value)后成功完成dst.k = v的替换;最终实现了sercet的污染
污染内置属性
1 | class father: |
此时内置属性的污染过程与自定义属性的过程大致,依旧是调用了三次的递归之后进入了最后一个判断;触发了最后的setattr(dst, k, v)函数导致污染
无法污染的Object
正如前面所述,并不是所有的类的属性都可以被污染,如Object的属性就无法被污染,所以需要目标类能够被切入点类或对象可以通过属性值查找获取到
1 | def merge(src, dst): |
更加广泛的利用
此时我们上面的利用都是利用__base__找到要污染属性的父类,但是如果要污染的属性没有存在继承关系时;此时的污染就会变得十分无力
获取全局变量
在Python中 ,函数或者类方法都具有globals属性;该属性将函数或者类中所申明的变量空间的全局变量以字典的形式返回
1 | a = 'hey' |
那么此时我们就可以使用globals来修改无继承关系的属性或者全局变量
1 | secret_var = 1 |
污染过程之断点调试
第一次递归
此时我们可以看到我们的payload和instance被当作src和dist传入
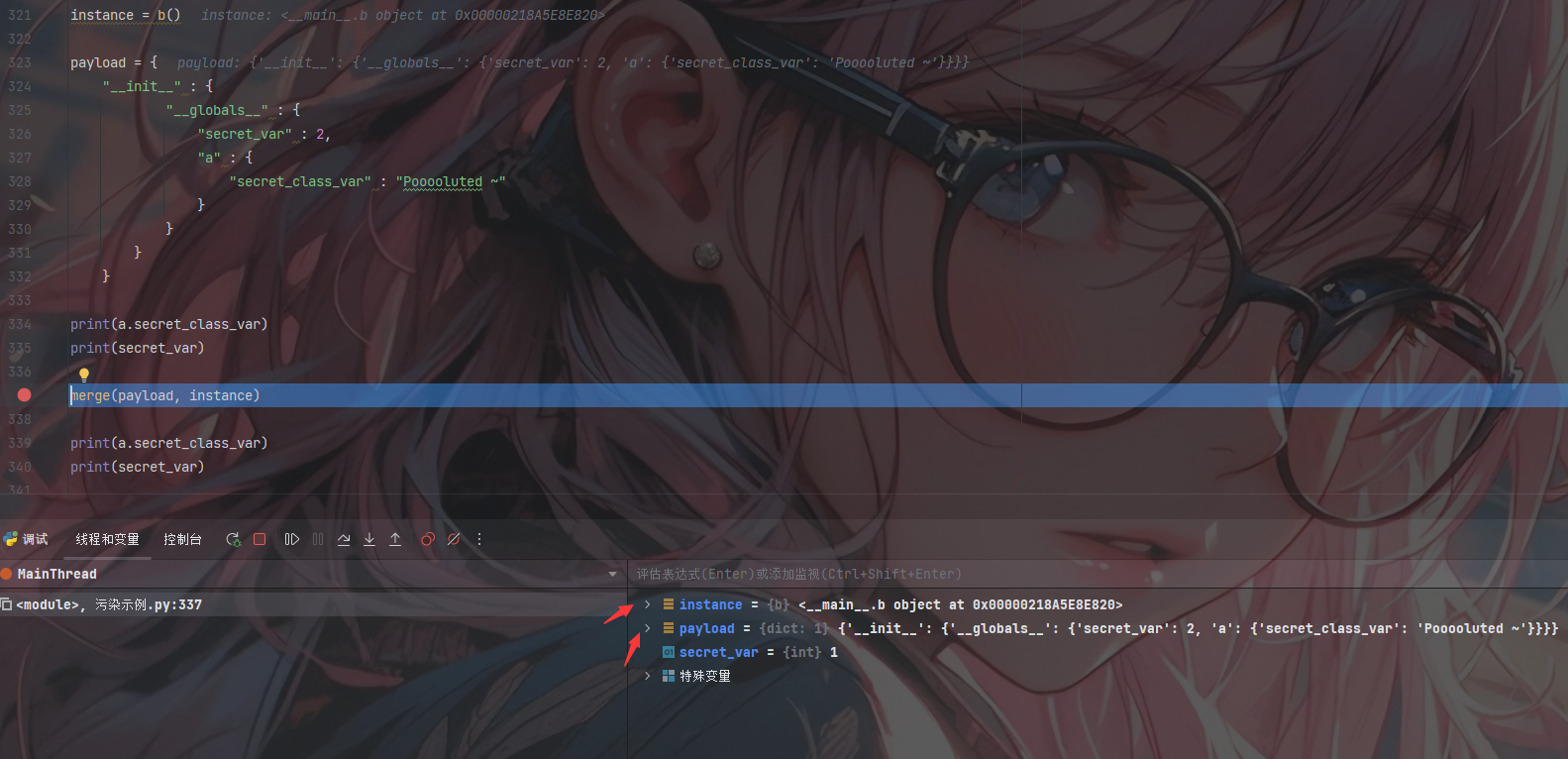
1 | dst = <__main__.b object at 0x00000218A5E8E820> |
此时取出k、v并进入第一层的判断
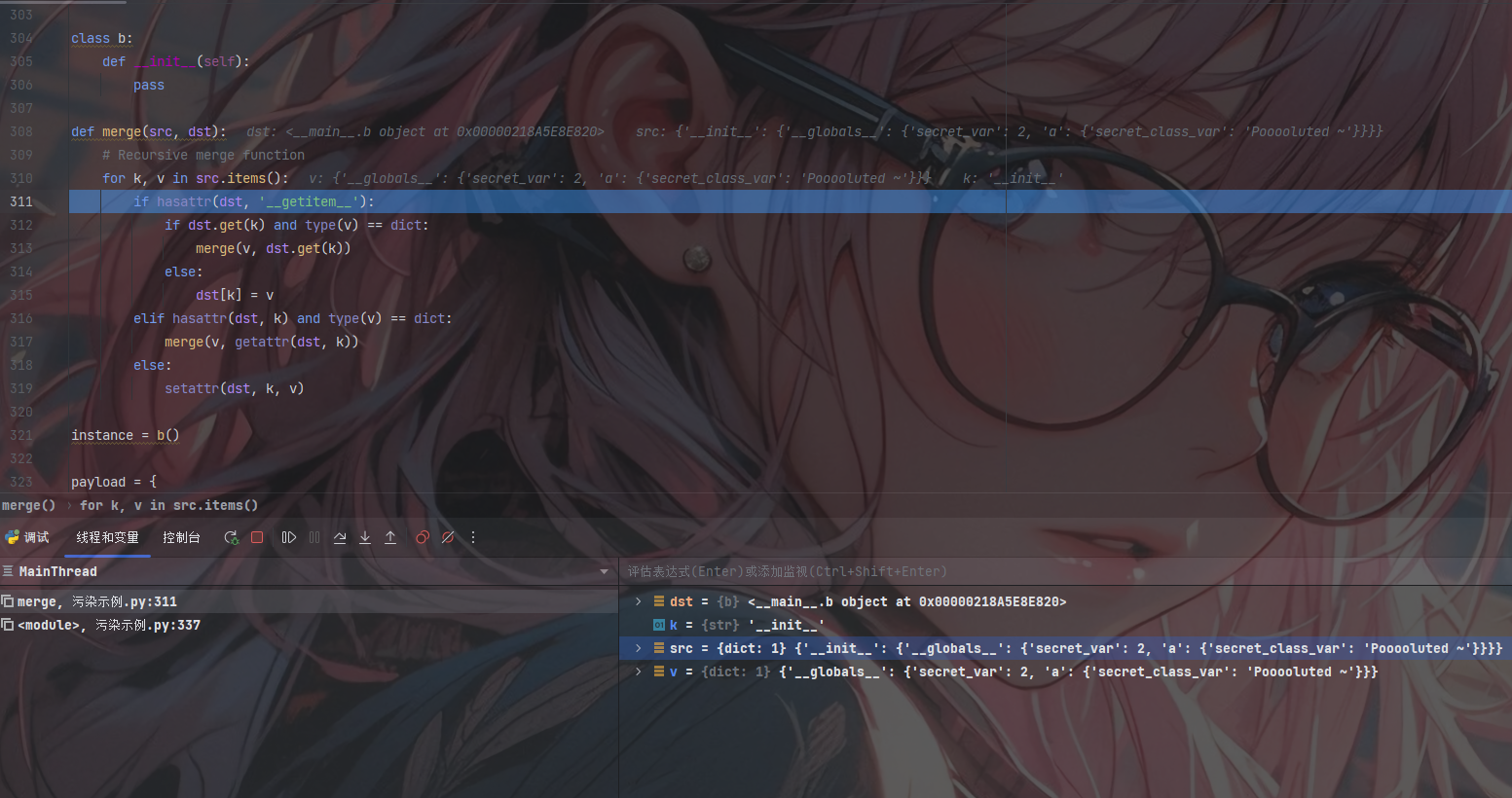
1 | k = '__init__' |
此时的第一层判断为Flase;紧接着进入了第二层的判断
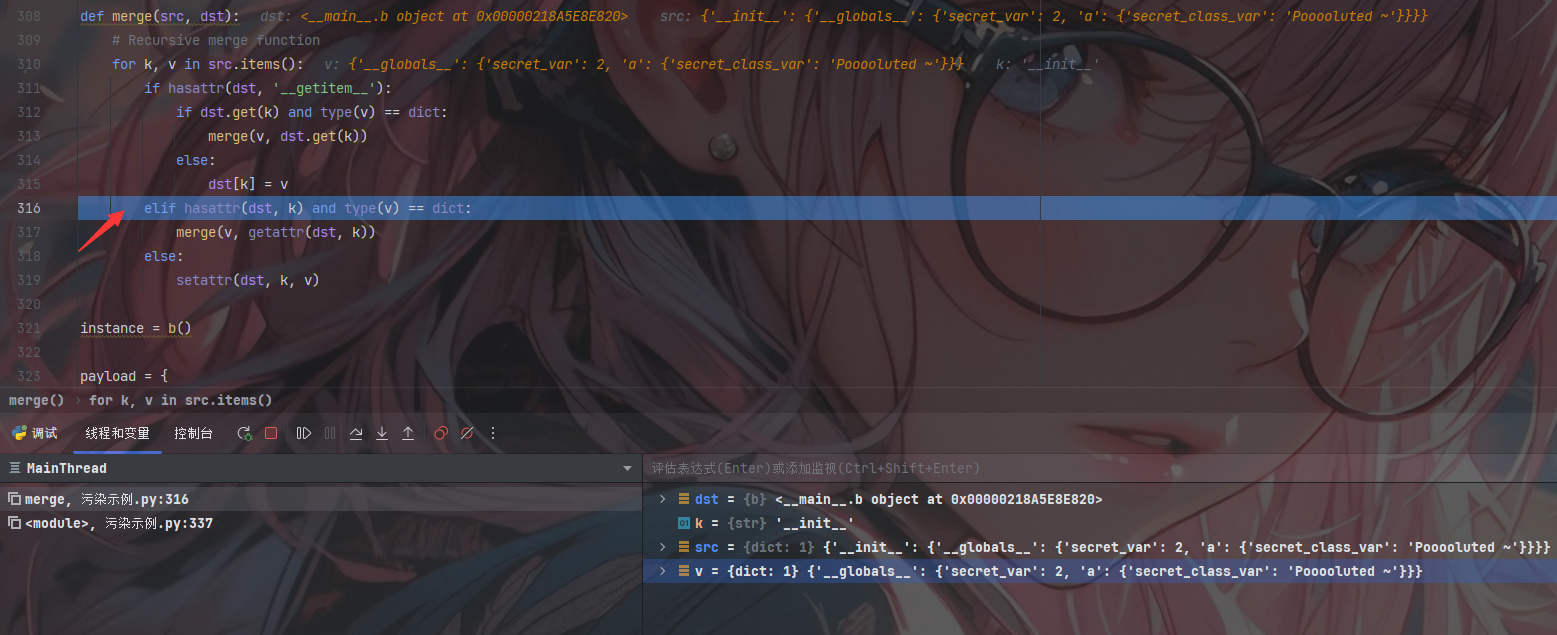
此时判断为True进入函数merge()准备进行第二次递归
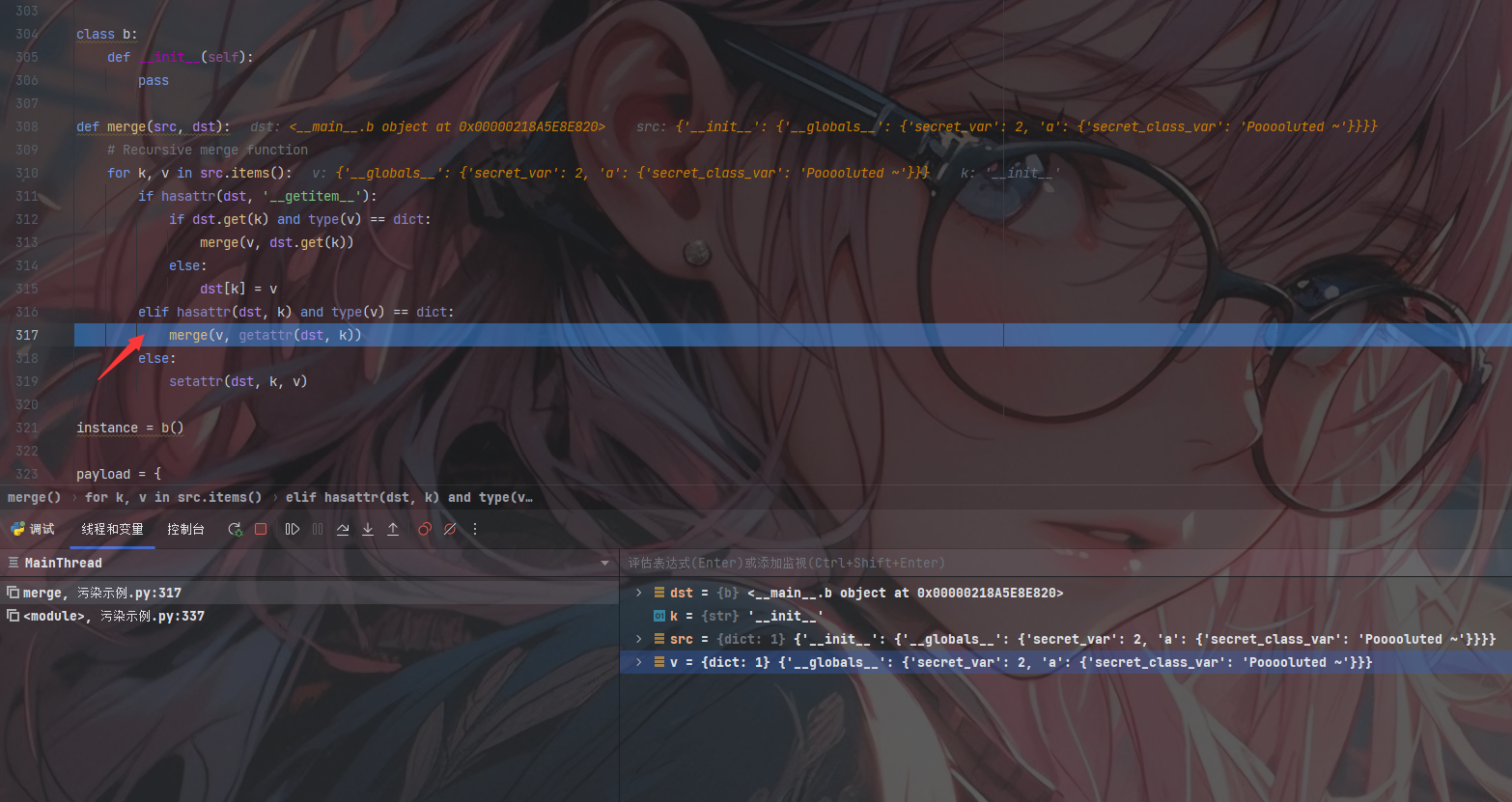
第二次递归
此时经了getattr(dst, k)函数的处理,此时的src和dst均已经发生了变化
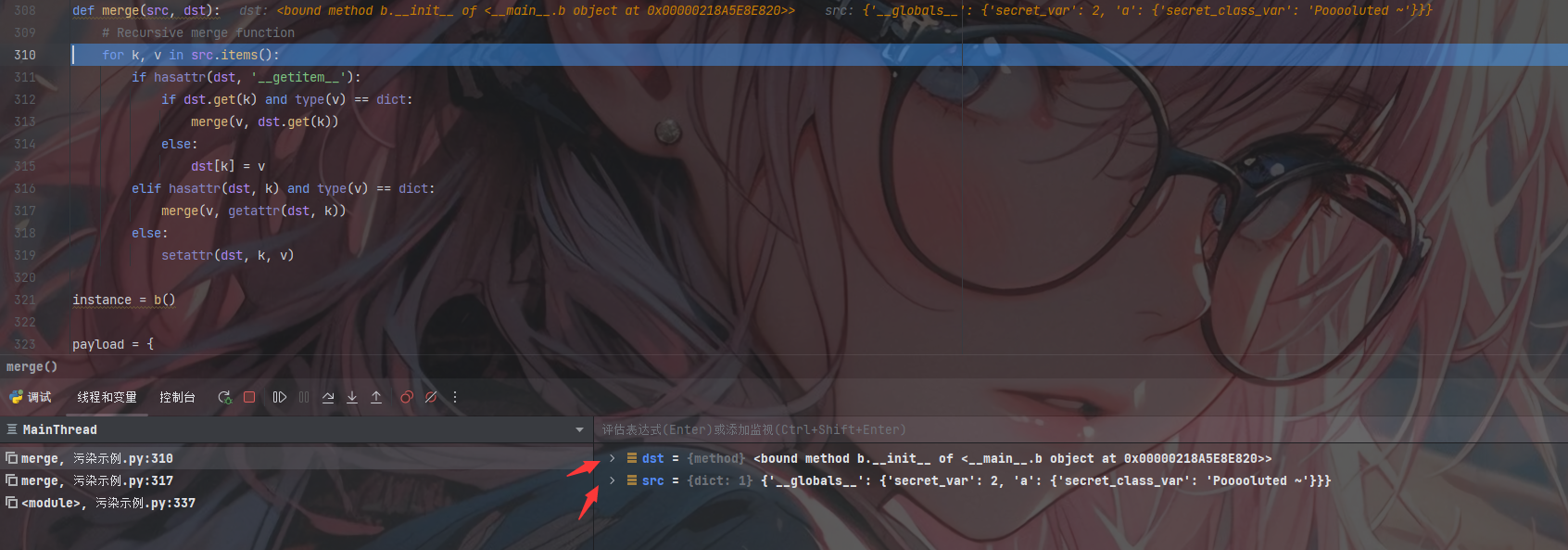
1 | dst = <bound method b.__init__ of <__main__.b object at 0x00000218A5E8E820>> |
紧接着取出k、v的值并进入第一层判断
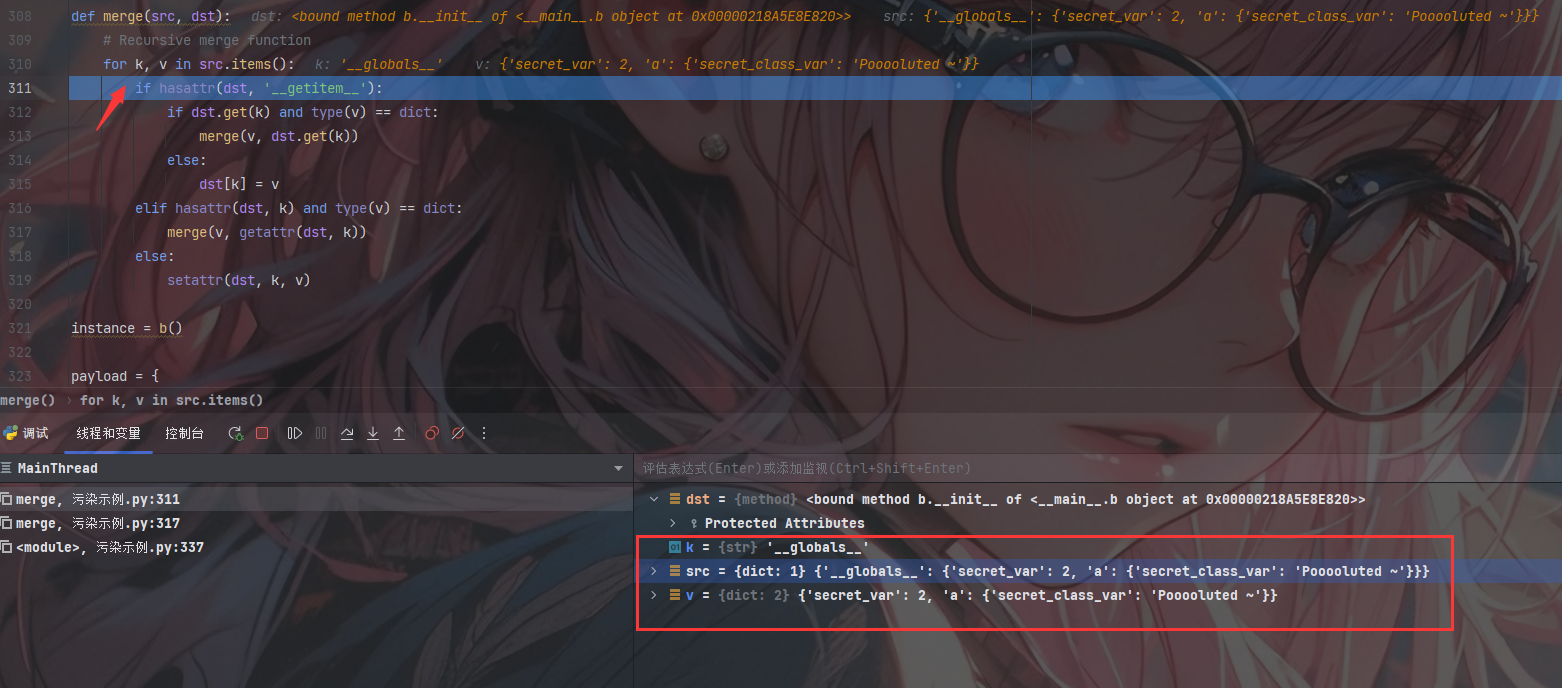
1 | dst = <bound method b.__init__ of <__main__.b object at 0x00000218A5E8E820>> |
第一层判断为Flase进入下一层;下一层判断为True进入merge()准备进行下一次的递归处理
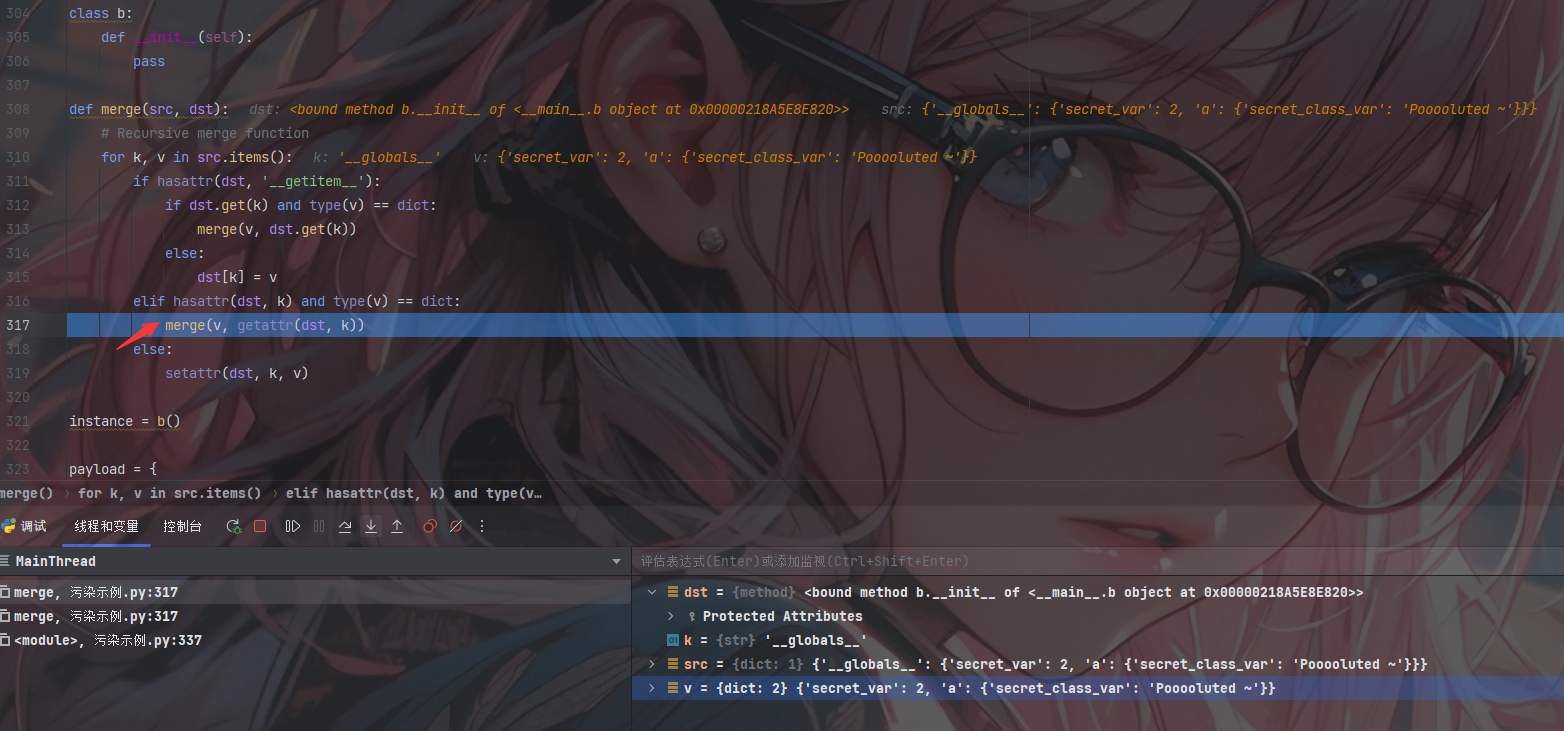
第三次递归
此时要注意的是dst、src又发生了大变化且这是我们使用__globals__的作用;此时已经将全局变量以字典的形式返回给我们:'secret_var': 1
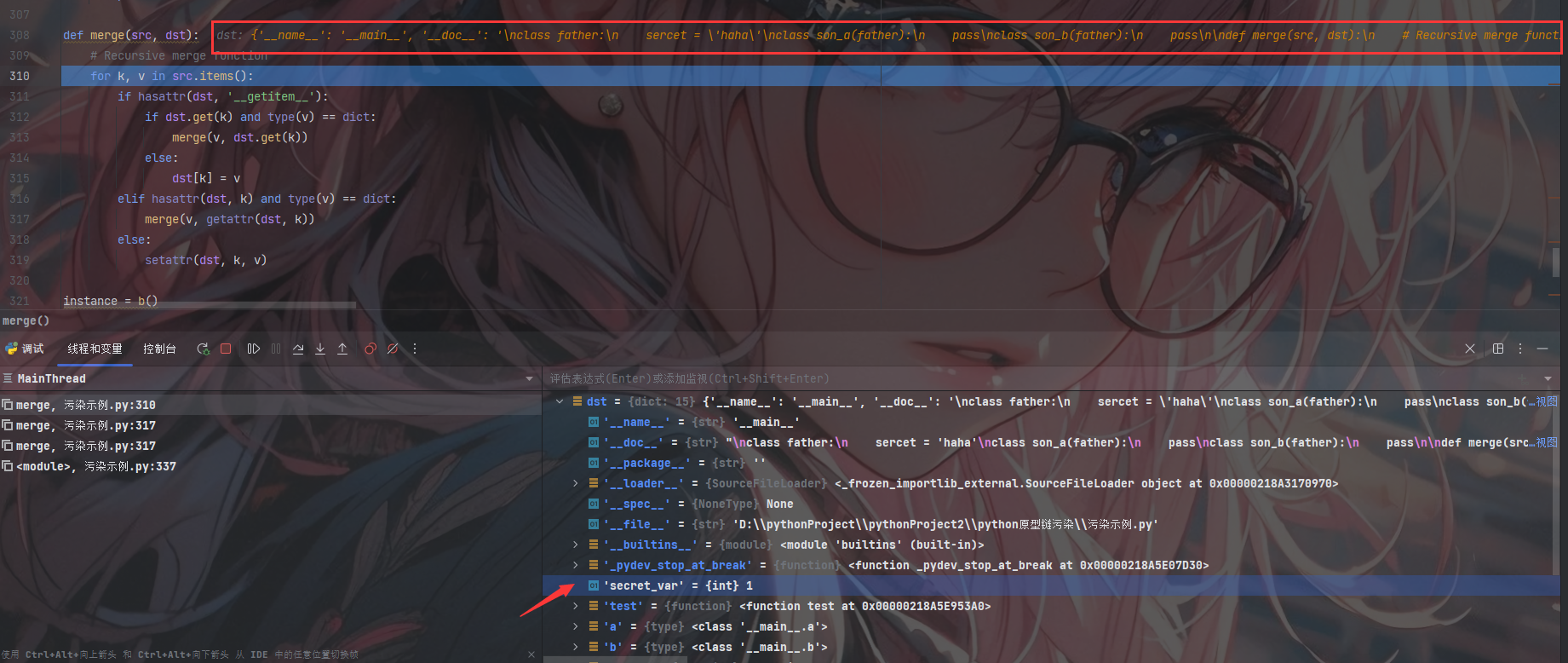
1 | dst = {'__name__': '__main__', '__doc__': None, '__package__': '', '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x0000022C21DC0970>, '__spec__': None, '__file__': 'D:\\pythonProject\\pythonProject2\\python原型链污染\\test.py', '__builtins__': <module 'builtins' (built-in)>, '_pydev_stop_at_break': <function _pydev_stop_at_break at 0x0000022C24A77D30>, 'secret_var': 1, 'test': <function test at 0x0000022C24B063A0>, 'merge': <function merge at 0x0000022C24B068B0>, 'instance': <__main__.b object at 0x0000022C24B00880>, 'payload': {'__init__': {'__globals__': {'secret_var': 2, 'a': {'secret_class_var': 'Pooooluted ~'}}}}} |
此时将k、v取出并进入第一层判断
1 | dst = {'__name__': '__main__', '__doc__': None, '__package__': '', '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x0000022C21DC0970>, '__spec__': None, '__file__': 'D:\\pythonProject\\pythonProject2\\python原型链污染\\test.py', '__builtins__': <module 'builtins' (built-in)>, '_pydev_stop_at_break': <function _pydev_stop_at_break at 0x0000022C24A77D30>, 'secret_var': 1, 'test': <function test at 0x0000022C24B063A0>, 'merge': <function merge at 0x0000022C24B068B0>, 'instance': <__main__.b object at 0x0000022C24B00880>, 'payload': {'__init__': {'__globals__': {'secret_var': 2, 'a': {'secret_class_var': 'Pooooluted ~'}}}}} |
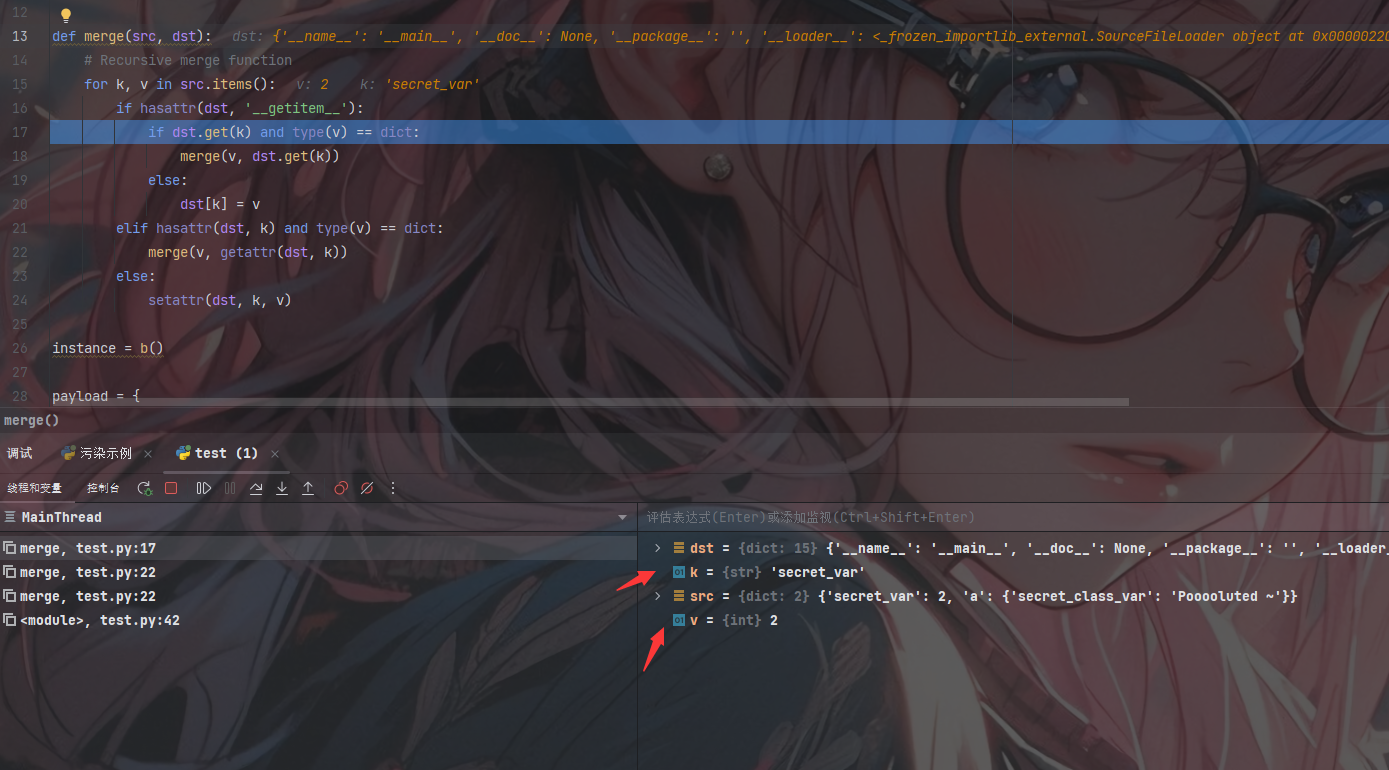
第一层判断为True直接进入dst[k] = v进行添加完成第一次的污染
接着继续取出k、v进入第二次判断
1 | dst = {'__name__': '__main__', '__doc__': None, '__package__': '', '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x0000022C21DC0970>, '__spec__': None, '__file__': 'D:\\pythonProject\\pythonProject2\\python原型链污染\\test.py', '__builtins__': <module 'builtins' (built-in)>, '_pydev_stop_at_break': <function _pydev_stop_at_break at 0x0000022C24A77D30>, 'secret_var': 2, 'test': <function test at 0x0000022C24B063A0>, 'merge': <function merge at 0x0000022C24B068B0>, 'instance': <__main__.b object at 0x0000022C24B00880>, 'payload': {'__init__': {'__globals__': {'secret_var': 2, 'a': {'secret_class_var': 'Pooooluted ~'}}}}} |
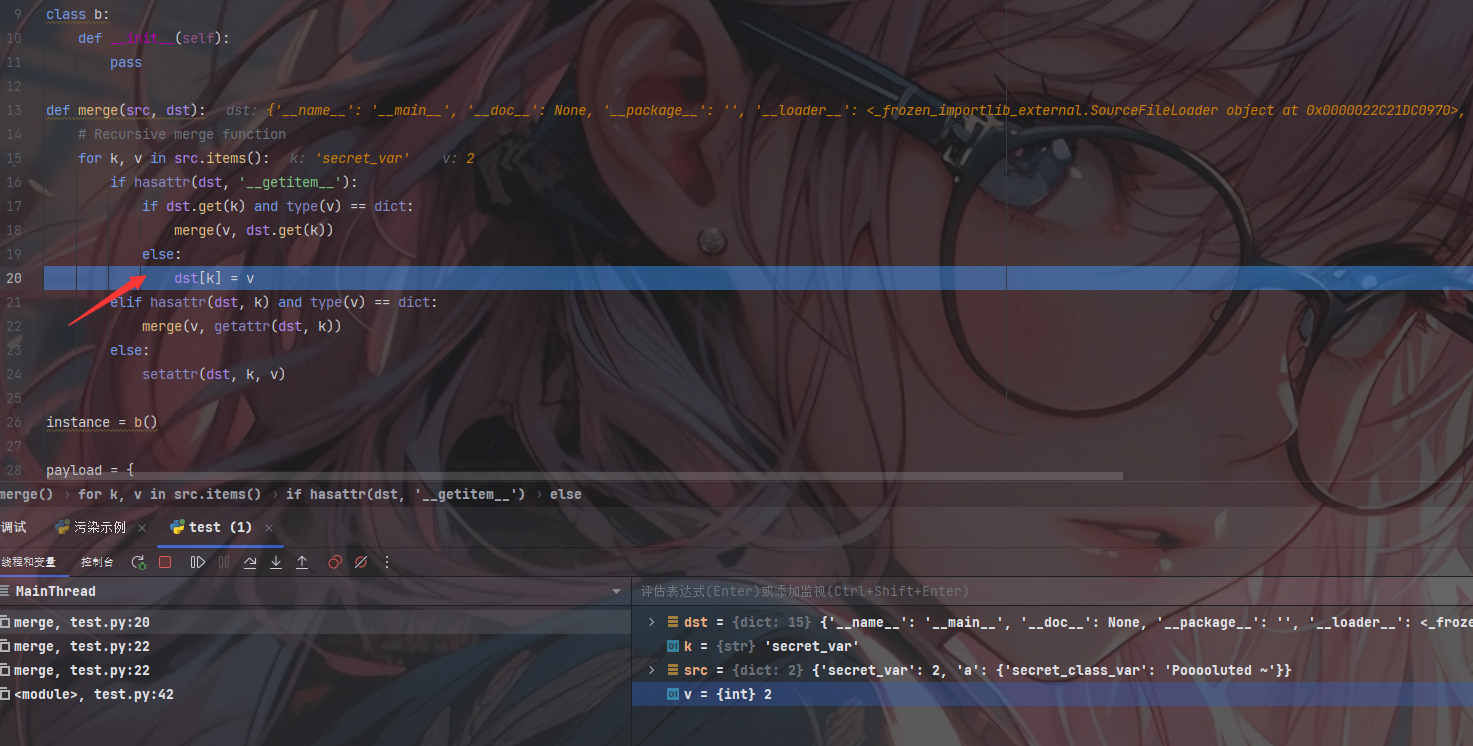
此时的判断为True然后进入merge(v, dst.get(k))准备再次递归
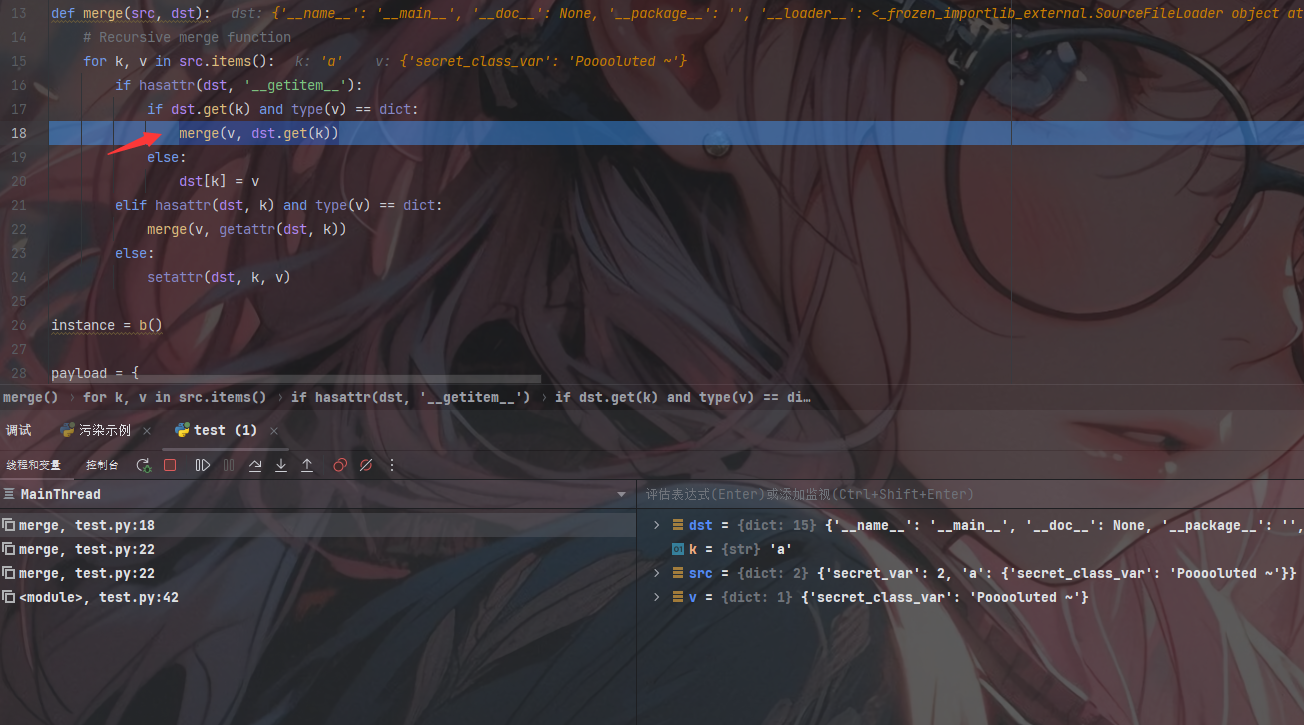
1 | dst = {'__name__': '__main__', '__doc__': None, '__package__': '', '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x0000022C21DC0970>, '__spec__': None, '__file__': 'D:\\pythonProject\\pythonProject2\\python原型链污染\\test.py', '__builtins__': <module 'builtins' (built-in)>, '_pydev_stop_at_break': <function _pydev_stop_at_break at 0x0000022C24A77D30>, 'secret_var': 2, 'test': <function test at 0x0000022C24B063A0>, 'merge': <function merge at 0x0000022C24B068B0>, 'instance': <__main__.b object at 0x0000022C24B00880>, 'payload': {'__init__': {'__globals__': {'secret_var': 2, 'a': {'secret_class_var': 'Pooooluted ~'}}}}} |
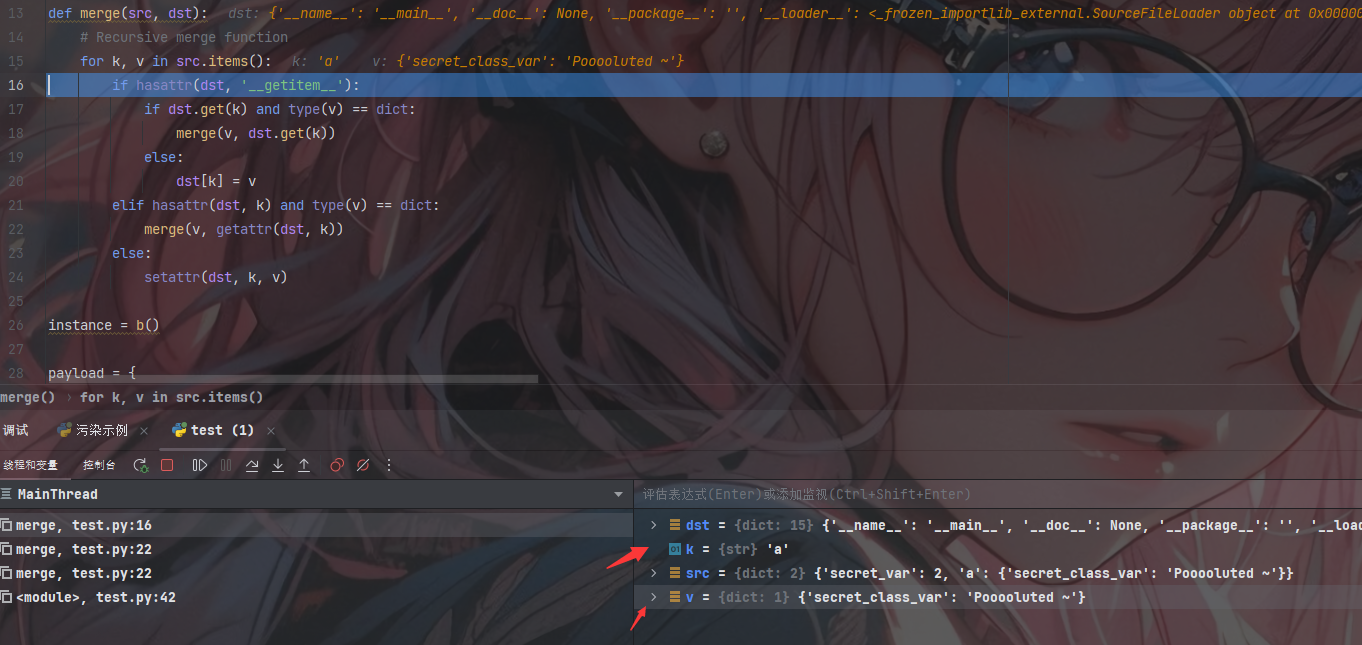
污染
此时对于变量的污染我们可以在第三次递归中看出,此时的第一层判断为True直接进入dst[k] = v进行添加完成第一次的污染
在函数或类方法中,我们经常会看到__init__初始化方法,但是它作为类的一个内置方法,在没有被重写作为函数的时候,其数据类型会被当做装饰器,而装饰器的特点就是都具有一个全局属性__globals__属性,__globals__ 属性是函数对象的一个属性,用于访问该函数所在模块的全局命名空间。具体来说就是,__globals__ 属性返回一个字典,里面包含了函数定义时所在模块的全局变量。
已经加载模块的获取
局限于当前模块的全局变量获取显然不够,很多情况下需要对并不是定义在入口文件中的类对象或者属性,而我们的操作位置又在入口文件中,这个时候就需要对其他加载过的模块来获取了
加载关系简单
在加载关系简单时,我们可以直接从文件的import语法部分找到目标模块,这个时候我们就可以通过获取全局变量来得到目标模块
1 | #test1.py |
demo:
1 | import test1 |
加载关系复杂
如CTF题目等实际环境中往往是多层模块导入,甚至是存在于内置模块或三方模块中导入,这个时候通过直接看代码文件中import语法查找就十分困难,而解决方法则是利用sys模块
sys模块
sys模块的modules属性以字典的形式包含了程序自开始运行时所有已加载过的模块,可以直接从该属性中获取到目标模块
1 | #test1.py |
demo:
1 | import test1 |
当然我们去使用的Payload绝大部分情况下是不会这样的,如上的Payload实际上是在已经import sys的情况下使用的,而大部分情况是没有直接导入的,这样问题就从寻找import特定模块的语句转换为寻找import了sys模块的语句,对问题解决的并不见得有多少优化。
加载关系复杂的实际利用
为了进一步优化,这里采用方式是利用Python中加载器loader,在官方文档中给出的定义是:

简单来说就是为实现模块加载而设计的类,其在importlib这一内置模块中有具体实现。令人庆幸的是importlib模块下所有的py文件中均引入了sys模块
1 | print("sys" in dir(__import__("importlib.__init__"))) |
所以只要我们能过获取到一个loader便能用如loader.__init__.__globals__['sys']的方式拿到sys模块,这样进而获取目标模块。
那loader好获取吗?答案是肯定的。依据官方文档的说明,对于一个模块来说,模块中的一些内置属性会在被加载时自动填充:

__spec__内置属性在Python 3.4版本引入,其包含了关于类加载时的信息,本身是定义在Lib/importlib/_bootstrap.py的类ModuleSpec,显然因为定义在importlib模块下的py文件,所以可以直接采用<模块名>.__spec__.__init__.__globals__['sys']获取到sys模块
由于ModuleSpec的属性值设置,相对于上面的获取方式,还有一种相对长的payload的获取方式,主要是利用ModuleSpec中的loader属性。如属性名所示,该属性的值是模块加载时所用的loader,在源码中如下所示:
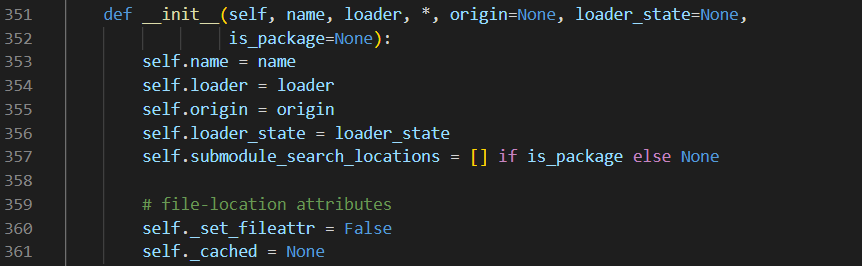
所以有这样的相对长的Payload:<模块名>.__spec__.loader.__init__.__globals__['sys']
实际环境下的合并函数
目前发现了Pydash模块中的set_和set_with函数具有如上实例中merge函数类似的类属性赋值逻辑,能够实现污染攻击。idekctf 2022*中的task manager这题就设计使用该函数提供可以污染的环境。