想要构建一个“上帝视野”的时候前期的信息收集是十分重要的;无论是了解一个人、一项业务、还是深入一个系统等,都需要“信息”。在现在的攻防演练中外网已经趋于完善之前满地都是nday和弱口令的情况已经一去不复返。在这种情况下除非能祭出0day的大杀器不然依旧还是依靠自身经验的完善的信息收集。那么此时我们初探者的整体流程就是在拿到靶标之后如何快速的将这个靶标的信息全部了然于胸。下面依据我自身的经验总结了一下之前在攻防演练中的信息收集流程
1 靶标ip --> c、b段资产 and 旁站资产 --> 端口扫描 --> cms识别 --> 批量的poc、exp验证
在攻防演练中我们拿到的靶标信息一般只会有目标系统名称、防御单位、目标系统IP和URL;此时给出的URL一般就是主域名;但是这种主域名一般为门户网站十分的不好下手;我们只能对其进行IPC备案、证书、DNS共享信息、WHOIS、股权信息、IP反查、开放端口等进行收集
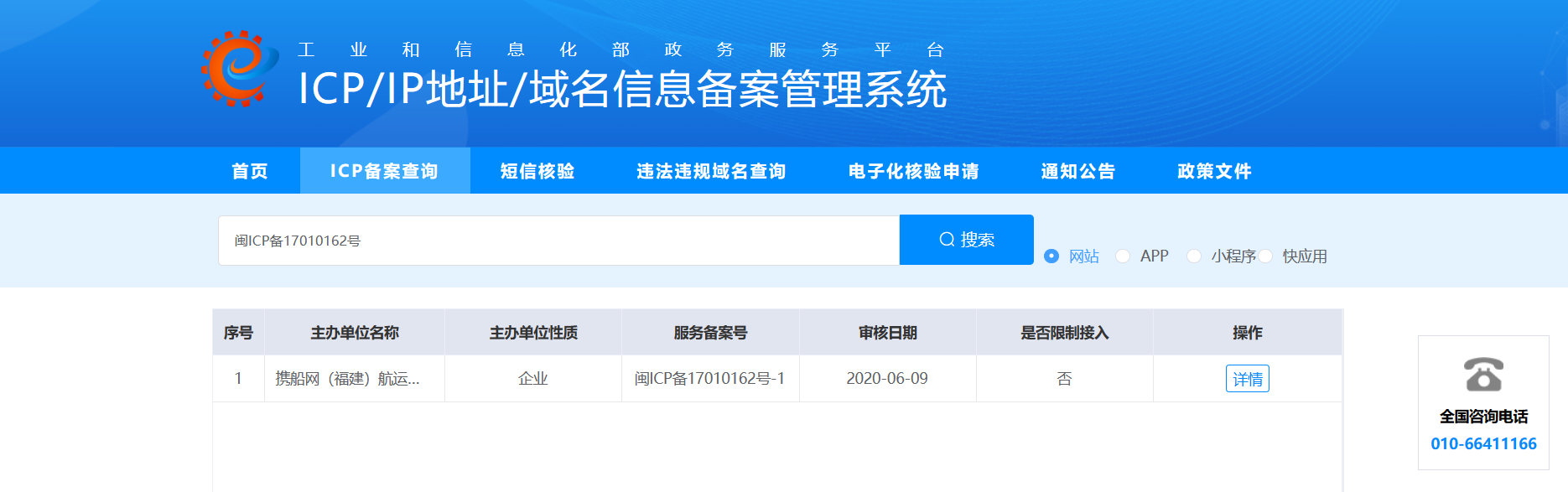
通过查询目标系统的IPC备案可以帮助我们发现该单位还注册了哪些网站,此时不仅可以扩大我们的渗透范围也可以在getshell之后来做一个资产证明(不然辛辛苦苦打下了的靶标,裁判那里不承认就白忙活了)
1 2 https://beian.miit.gov.cn/#/Integrated/index fofa:icp="闽ICP备17010162号"
此时通过公用的SSL证书我们可以查询到相关的其他域名,此时可以使得攻击范围得到扩大
1 https://crt.sh/ --> 输入域名即可查找
1 2 3 4 5 fofa的查询语法: cert="baidu" --> 搜索https或者imaps中带有百度的资产 cert.subject="xxx" --> 搜索证书的持有者为xxx的资产 cert.issuer="xxx" --> 搜索证书的颁发者为xxx的资产 cert.is_valid=true/false --> 验证证书的有效性
通过whois信息可以获取注册人的关键信息。如注册商、联系人、联系邮箱、联系电话,也可以对注册人、邮箱、电话反查域名,也可以通过搜索引擎进一步挖掘域名所有人的信息。深入可社工、可漏洞挖掘利用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 在线网址: 站长之家域名WHOIS信息查询地址 http://whois.chinaz.com/ 爱站网域名WHOIS信息查询地址 https://whois.aizhan.com/ 腾讯云域名WHOIS信息查询地址 https://whois.cloud.tencent.com/ 美橙互联域名WHOIS信息查询地址 https://whois.cndns.com/ 爱名网域名WHOIS信息查询地址 https://www.22.cn/domain/ 易名网域名WHOIS信息查询地址 https://whois.ename.net/ 中国万网域名WHOIS信息查询地址https://whois.aliyun.com/ 西部数码域名WHOIS信息查询地址 https://whois.west.cn/ 新网域名WHOIS信息查询地址 http://whois.xinnet.com/domain/whois/index.jsp 纳网域名WHOIS信息查询地址 http://whois.nawang.cn/ 中资源域名WHOIS信息查询地址 https://www.zzy.cn/domain/whois.html 三五互联域名WHOIS信息查询地址 https://cp.35.com/chinese/whois.php 新网互联域名WHOIS信息查询地址 http://www.dns.com.cn/show/domain/whois/index.do 国外WHOIS信息查询地址 https://who.is/ (可能有些目标做了whois信息保护,导致看不到想要的信息,这时可以选择使用国外的查询网站接口,很有可能就没有做保护!!)
此时目标往往会将多个域名绑定在同一个ip上面,那么此时我们就可以对其进行ip反查,此时可以帮助我们得到更多的目标资产,扩展攻击的范围
1 2 3 4 在线网址: https://stool.chinaz.com/same https://dnslytics.com/ https://x.threatbook.cn/
DNS(Domain Name Server,域名服务器)是进行域名(domain name)和与之相对应的IP地址 (IP address)转换的服务器。DNS中保存了一张域名(domain name)和与之相对应的IP地址 (IP address)的表,以解析消息的域名。 域名是Internet上某一台计算机或计算机组的名称,用于在数据传输时标识计算机的电子方位(有时也指地理位置)。域名是由一串用点分隔的名字组成的,通常包含组织名,而且始终包括两到三个字母的后缀,以指明组织的类型或该域所在的国家或地区。那么此时我们就可以通过DNS的查询来找到相关的域名
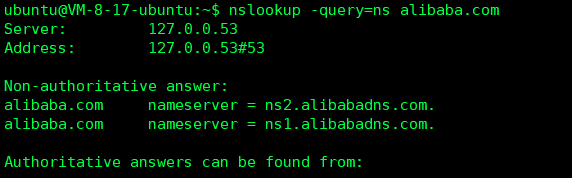
首先查询目标是否存在自建的NS服务器
1 nslookup -query=ns xxx.com
将获取到的NS服务器带入https://hackertarget.com/find-shared-dns-servers/进行查询;此处查询的结果并不全是属于目标范围,需要进一步的确认和观察。
拿到公司名称后,先不用急着查备案、找域名,而是先看看这家公司的股权构成,因为一般一家公司的子公司也是可以作为目标去打的,不过有时是要求 50% 持股或者 100% 持股,这个就要看具体实际情况了。
端口 –> 业务
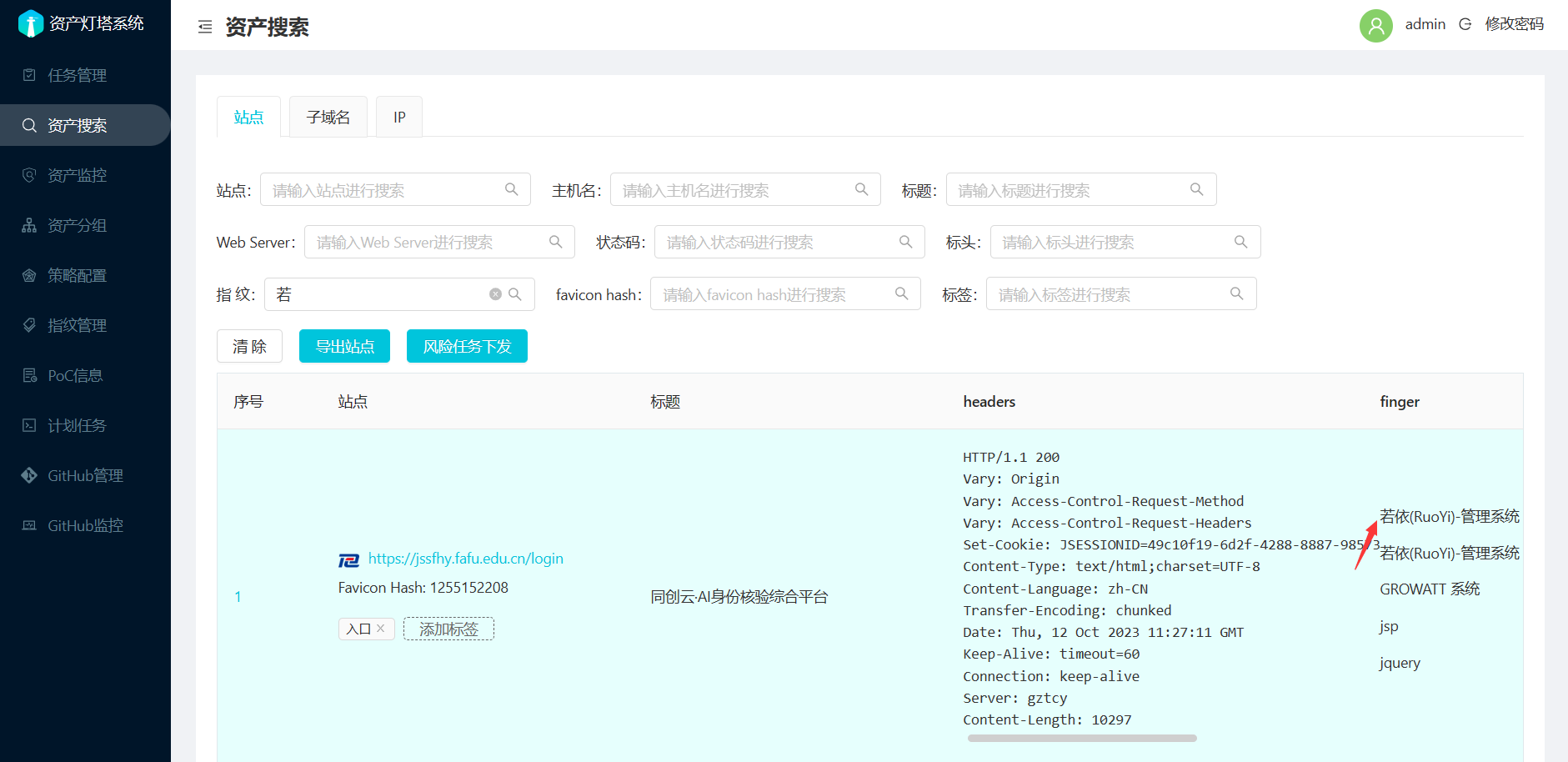
说到资产收集的自动化工具肯定是绕不过ARL(Asset Reconnaissance Lighthouse)资产侦察灯塔系统;ARL可以帮助我们进行资产信息的批量收集,支持自定义poc和cms进行识别;此时我们需要关注的选项在于任务管理和资产搜索这两个功能(注意此时需要在配置文件中将不扫描的三个后缀去掉,然后可以自行导入指纹库和poc库来完善自己的灯塔)
此时的策略配置可以帮助我们针对不同情况下发起的扫描,支持在不同任务下进行扫描来简化扫描任务从而得到我们想要的结果。
此时因为我们往往拿到的靶标都是门户网站入手点较少也较为困难;那么此时我们就可以把目光聚焦在子域名上面,此时子域名因为不像门户网站一样经常暴露在大众视野之下所以他的防护和维修也会较差一点;此时我将子域名收集分成几个途径来收集,分别是脚本工具收集,网络空间测绘引擎语法收集、搜索引擎
1 2 3 4 5 6 7 8 9 10 title="福建农林大学" --> 从标题中搜索"福建农林大学"(此时可以利用title="后台"来查找特定的后台网站) header="fafu" --> 从http头中搜索"fafu"(header="thinkphp") body="福建农林大学" --> 从html正文中搜索"福建农林大学"(此时也可以使用该语法body="账号"/body="管理界面") domain="fafu.edu.cn" --> 搜索根域名带有"fafu.edu.cn"的网站(此语法常用于搜索子域名资产,可配合app="xx"来查找特定资产) icp="京ICP证030173" --> 查找icp备案为"京ICP证030173"的网站 host=".gov.cn" --> 从url中搜索".gov.cn"(此时常用host="login"来搜索域名中带有”login”关键词的网站/host="admin") port="6379" --> 查找对应"6379"端口的资产 ip="1.1.1.1" --> 搜索包含"1.1.1.1"的资产 ip="220.181.111.1/24" 查询ip为"220.181.111.1"的c段资产 app="Microsoft-Exchange" --> 搜索Microsoft-Exchange设备;此时这个语法要是用好的话往往可以更快速的帮助我们发现突破资产
此时相较于基础语句更加高效的语句便是加上逻辑运算符的语句;此时我们可以先来了解一下逻辑运算符
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 && --> 与 || --> 或 != --> 不等 *= --> 模糊匹配 () --> 括号的优先级最高 title="后台登录" && body="默认密码" --> 查找默认密码 (status_code="200" || banner="HTTP/1.1 200 OK") --> 仅需要状态码为200的资产 && country="CN" && region!="HK" && region!="TW" && region!="MO" --> 排除港澳台的资产 app="ThinkPHP" && (status_code="200" || banner="HTTP/1.1 200 OK") && country="CN" && region!="HK" && region!="TW" && region!="MO" && after="2023-10-1" --> 搜索thinkapp并且状态码为"200"且需要中国的,但是要排除掉港澳台地区的最近一个月的资产数据 title="401 Unauthorized" || title="403 Forbidden" || title="404 Not Found" --> 查找未授权漏洞 title="401 Unauthorized" && body="input type=password" && status_code=200 --> 查找弱口令 body="<inputtype=\"password\"" --> 查找弱口令 title="Upload" && body="form enctype=multipart/form-data method=post" --> 查找文件上传 body="<form[^>]*?enctype=\"multipart/form-data\"[^>]*?>" --> 查找文件上传 title="Powered by WordPress" || title="Powered by Joomla" || title="Powered by Drupal" --> 查找CMS title="404 Not Found" || title="403 Forbidden" || title="401 Unauthorized" || title="500 Internal Server Error" || title="502 Bad Gateway" || title="503 Service Unavailable" || title="SQL Error" || title="ASP.NET Error" --> 查找Web漏洞 title="phpMyAdmin" || title="MySQL" || title="phpPgAdmin" || title="PostgreSQL" || title="Microsoft SQL Server" && body="input type=password" --> 查找未加密的数据库 title="404 Not Found" || title="403 Forbidden" || title="401 Unauthorized" || title="500 Internal Server Error" || title="502 Bad Gateway" || title="503 Service Unavailable" || title="SQL Error" || title="ASP.NET Error" || title="404" || title="Login - Powered by Discuz" || title="Login - Powered by UCenter" || title="Powered by DedeCMS" || title="Powered by PHPWind" || title="Powered by discuz" || title="Powered by phpMyAdmin" || title="Powered by phpwind" || title="Powered by vBulletin" || title="Powered by wordpress" || title="phpMyAdmin" || title="phpinfo" || title="Microsoft-IIS" || title="Joomla" || title="Drupal" || title="WordPress" || title="Apache Tomcat" || title="GlassFish Server" || title="nginx" || title="Oracle HTTP Server" --> 查找常见的漏洞指纹 body="<form method=\"post\" enctype=\"multipart/form-data\" action=\"\S*/index.php\" name=\"form\" id=\"form\">" --> 查找远程命令执行漏洞 (header="uc-httpd 1.0.0" && server="JBoss-5.0") || server="Apache" --> 排除一些蜜罐
华顺信安也推出了FOFA-G版本:https://octra.fofa.vip/
Hunter的资产收录是tob的,那么此时如果很多资产企业有备案的话大多数都可以被鹰图收录;此时主要是针对企业资产。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 domain="fafu.edu.cn" --> 搜索域名包含"fafu.edu.cn"的网站 domain.suffix="qianxin.cn" --> 搜索主域为"qianxin.cn"的网站 icp.name="奇安信" --> 搜索icp备案网站中含有"奇安信"的资产(在针对edu的攻防中可以试试) icp.number="京ICP备16020626号-8" --> 搜索通过域名关联的ICP备案号为”京ICP备16020626号-8”的网站资产 web.title="管理后台" --> 从网站标题中搜索含有"管理后台"的资产 web.bode="登入" --> 搜索网站正文中含有"登入"的资产 web.tag="登录页面" --> 搜索包含资产标签"登录页面"的资产(网络摄像设备/OA/CMS/登录页面/防火墙设备/路由器) web.icon="22eeab765346f14faf564a4709f98548" --> 查询网站icon与该icon相同的资产 web.similar="fafu.edu.cn" --> 搜索与"fafu.edu.cn"相似的网站 web.similar_icon=="17262739310191283300" --> 查询网站icon与该icon相似的资产 app.name="小米 Router" --> 搜索标记为"小米 Router"的资产 cert="fafu" --> 搜索证书中带有"fafu"的资产 cert.subject="fafu.edu.cn" --> 搜索证书使用者为"fafu.edu.cn"的资产 cert.subject.suffix="奇安信科技集团股份有限公司" --> 搜索证书使用者组织是奇安信科技集团股份有限公司的资产 web.is_vul=true --> 搜索存在历史漏洞的资产
1 2 3 在刚开始使用Hunter时总是使用domain来收集子域名后面发现不太准确,此时我们可以利用domain.suffix 与domain.suffix的一般组合: icon="xxx"&&domain.suffix="xxx"
1 2 3 4 5 6 7 8 9 10 通过网站标题关键词: domain_suffix="xxx"&&title="登录"&&title="管理"&&title="后台"&&title="中心" 直接输入关键词: admin/login/register 通过c段定义未授权: ip="xx.xx.xx.1/24"&&port="6379" 通过指纹快速查找问题资产:在刷问题资产时,可以通过某款特定的CMS或指定的组件,结合检索来提高准确率。 (body="xxx")&&component_name="Apache Tomcat" 通过指纹扩大疑似存在问题的资产范围:们从疑似存在问题的目标资产中提取相应的指纹。例如js,css,组件关键词等信息进行查询。例如:Shiro的rememberMe字段,输入检索语法app=”shiro” and body=”rememberMe”,即可锁定多个疑似存在相同问题的系统。 app="shiro"&&body="rememberMe"
360quake的资产收录是toc的,此时一些边缘资产比如域名未经过备案的资产我们使用Hunter是查找不到的,但是360quake在这一块的收录是较强的;比如一些oa和一些云主机,此时企业为了自己用根本不会去备案那么此时360quake就有收录
1 2 3 4 5 domain="*.fafu.edu.cn" app="Apache" catalog:"网络安全设备" type="VPN/防火墙" 其他的检索词如body和title、tag、ip、host...都与上面两个网络空间测绘引擎一样;body从html中检索,title从标题中检索,tag从标签中检索,header从请求头中检索
总的来说,信息收集有很多重复性查询筛选,手工相对费时费力,因此可以借助半自动化工具来达到事半功倍的效果。而对于自动化工具的话我们就需要了解其命令参数和组合语法进行深度扫描
1 https://github.com/shmilylty/OneForAll
此时针对该工具我们应该了解一下它的参数和配置(其目录下的setting.py)
此时可以调整配置来达到我们需要的目的
1 2 python3 oneforall.py --target example.com run python3 oneforall.py --targets ./domains.txt run
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 _ __ _____ _ _ _ | |/ / / ____| | | | | (_) | ' / | (___ _ _| |__ __| | ___ _ __ ___ __ _ _ _ __ | < \___ \| | | | '_ \ / _| |/ _ \| '_ _ \ / _ | | '_ \ | . \ ____) | |_| | |_) | (_| | (_) | | | | | | (_| | | | | | |_|\_\ |_____/ \__,_|_.__/ \__,_|\___/|_| |_| |_|\__,_|_|_| |_| [INFO] Current Version: 0.7 Usage of ./cmd: -api 使用网络接口 -b string 宽带的下行速度,可以5M,5K,5G (default "1M") -check-origin 会从返回包检查DNS是否为设定的,防止其他包的干扰 -csv 输出excel文件 -d string 爆破域名 -dl string 从文件中读取爆破域名 -e int 默认网络设备ID,默认-1,如果有多个网络设备会在命令行中选择 (default -1) -f string 字典路径,-d下文件为子域名字典,-verify下文件为需要验证的域名 -filter-wild 自动分析并过滤泛解析,最终输出文件,需要与'-o'搭配 -full 完整模式,使用网络接口和内置字典 -l int 爆破域名层级,默认爆破一级域名 (default 1) -list-network 列出所有网络设备 -o string 输出文件路径 -s string resolvers文件路径,默认使用内置DNS -sf string 三级域名爆破字典文件(默认内置) -silent 使用后屏幕将仅输出域名 -skip-wild 跳过泛解析的域名 -summary 在扫描完毕后整理域名归属asn以及IP段 -test 测试本地最大发包数 -ttl 导出格式中包含TTL选项 -verify 验证模式
1 2 3 4 5 ./subfinder -d baidu.com -silent|./ksubdomain -verify -silent|./httpx -title -content-length -status-code --> 达到收集域名,验证域名,http验证存活 ./ksubdomain -d seebug.org -f subdomains.dict --> 使用自定义字典进行爆破 ./ksubdomain -d seebug.org -l 2 --> 爆破三级域名 ./ksubdomain -d seebug.org -full --> 完整模式 ./ksubdomain -d seebug.org -summary -csv --> 根据域名归属的asn以及IP段自动整理输出为execl格式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 Usage: ./subfinder [flags] Flags: INPUT: -d, -domain string[] domains to find subdomains for -dL, -list string file containing list of domains for subdomain discovery SOURCE: -s, -sources string[] 用于发现特定来源(-s github) -recursive use only sources that can handle subdomains recursively (e.g. subdomain.domain.tld vs domain.tld) -all 使用所有的源 -es, -exclude-sources string[] 排除特定的源 (-es alienvault,zoomeyeapi) FILTER: -m, -match string[] 要匹配的子域或子域列名(使用,进行分隔) -f, -filter string[] 要过滤的子域或子域列名(使用,进行分隔) RATE-LIMIT: -rl, -rate-limit int 最大发包数/s -rls value maximum number of http requests to send per second four providers in key=value format (-rls "hackertarget=10/s,shodan=15/s") -t int number of concurrent goroutines for resolving (-active only) (default 10) UPDATE: -up, -update update subfinder to latest version -duc, -disable-update-check disable automatic subfinder update check OUTPUT: -o, -output string 输出目录 -oJ, -json 以JSON格式输出 -oD, -output-dir string directory to write output (-dL only) -cs, -collect-sources include all sources in the output (-json only) -oI, -ip 输出中包含host的IP(-active only) CONFIGURATION: -config string flag config file (default "$HOME/.config/subfinder/config.yaml") -pc, -provider-config string provider config file (default "$HOME/.config/subfinder/provider-config.yaml") -r string[] comma separated list of resolvers to use -rL, -rlist string file containing list of resolvers to use -nW, -active 只展示存活子域 -proxy string http proxy to use with subfinder -ei, -exclude-ip exclude IPs from the list of domains DEBUG: -silent show only subdomains in output -version show version of subfinder -v show verbose output -nc, -no-color disable color in output -ls, -list-sources list all available sources OPTIMIZATION: -timeout int seconds to wait before timing out (default 30) -max-time int minutes to wait for enumeration results (default 10)
1 python3 jsinfo.py -d jd.com --keyword jd --save jd.api.txt --savedomain jd.domain.txt
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 URLFinder.exe -u http://www.baidu.com -s all -m 3 URLFinder.exe -s all -m 3 -f url.txt -o res.html -a 自定义user-agent请求头 -b 自定义baseurl路径 -c 请求添加cookie -d 指定获取的域名,支持正则表达式 -f 批量url抓取,需指定url文本路径 -ff 与-f区别:全部抓取的数据,视为同一个url的结果来处理(只打印一份结果 | 只会输出一份结果) -h 帮助信息 -i 加载yaml配置文件,可自定义请求头、抓取规则等(不存在时,会在当前目录创建一个默认yaml配置文件) -m 抓取模式: 1 正常抓取(默认) 2 深入抓取 (URL深入一层 JS深入三层 防止抓偏) 3 安全深入抓取(过滤delete,remove等敏感路由) -max 最大抓取数 -o 结果导出到csv、json、html文件,需指定导出文件目录(.代表当前目录) -s 显示指定状态码,all为显示全部 -t 设置线程数(默认50) -time 设置超时时间(默认5,单位秒) -u 目标URL -x 设置代理,格式: http://username:password@127.0.0.1:8877 -z 提取所有目录对404链接进行fuzz(只对主域名下的链接生效,需要与 -s 一起使用) 1 目录递减fuzz 2 2级目录组合fuzz 3 3级目录组合fuzz(适合少量链接使用)
1 2 3 4 dnsub -d example.com -v 2 -o example.csv # -v 2 设置展示等级 # -o 设置扫描结果输出到example.csv文件 dnsub提供-f 和-f2两个参数设置字典, 分别是设置子域名字典和2级以上的子域名字典的,可以使用这两个参数指定字典路径
子域名的收集在攻防演练中往往都是兵家必争之地,此时收集的子域名越多代表突破口越多;此时还是主要依靠网络空间测绘引擎的语法进行收集再者就是利用自动化工具进行辅助(自动化收集过后记得验活)