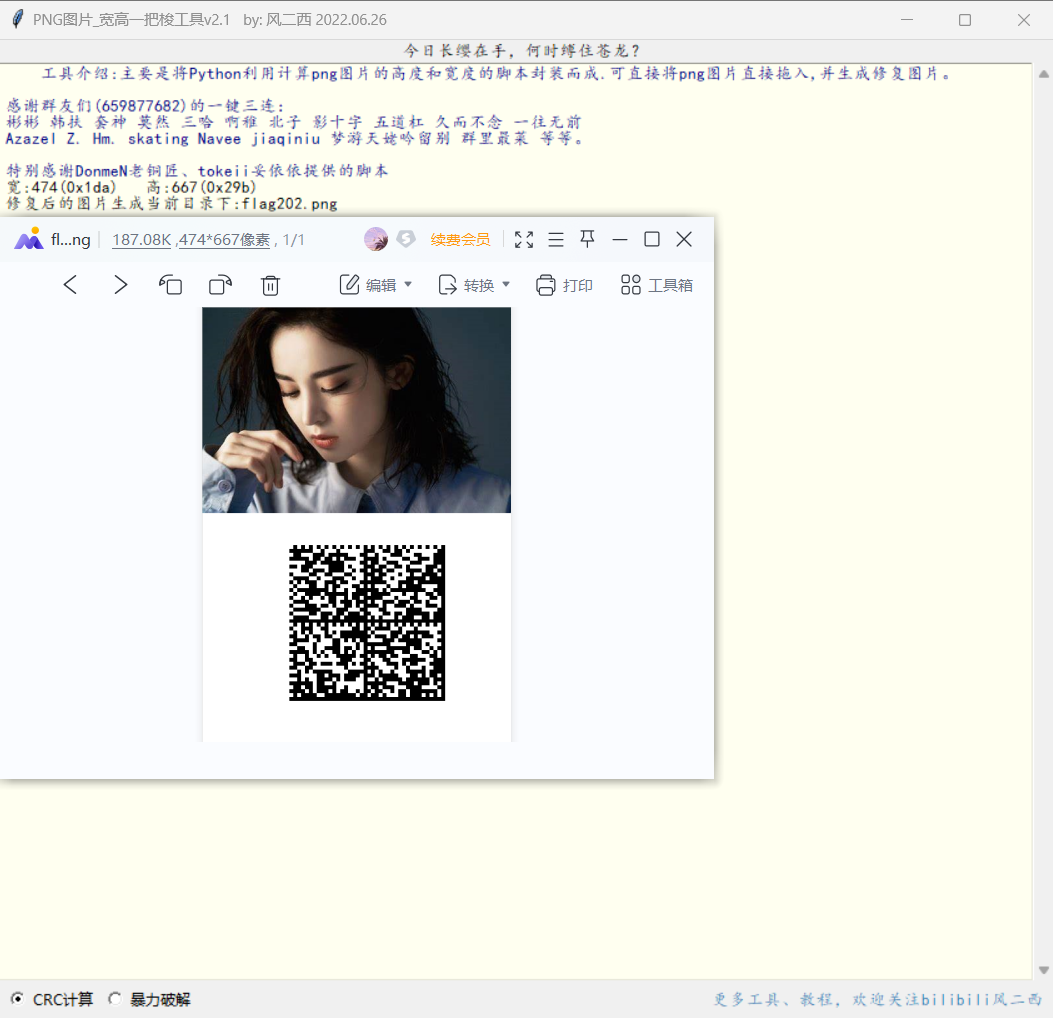
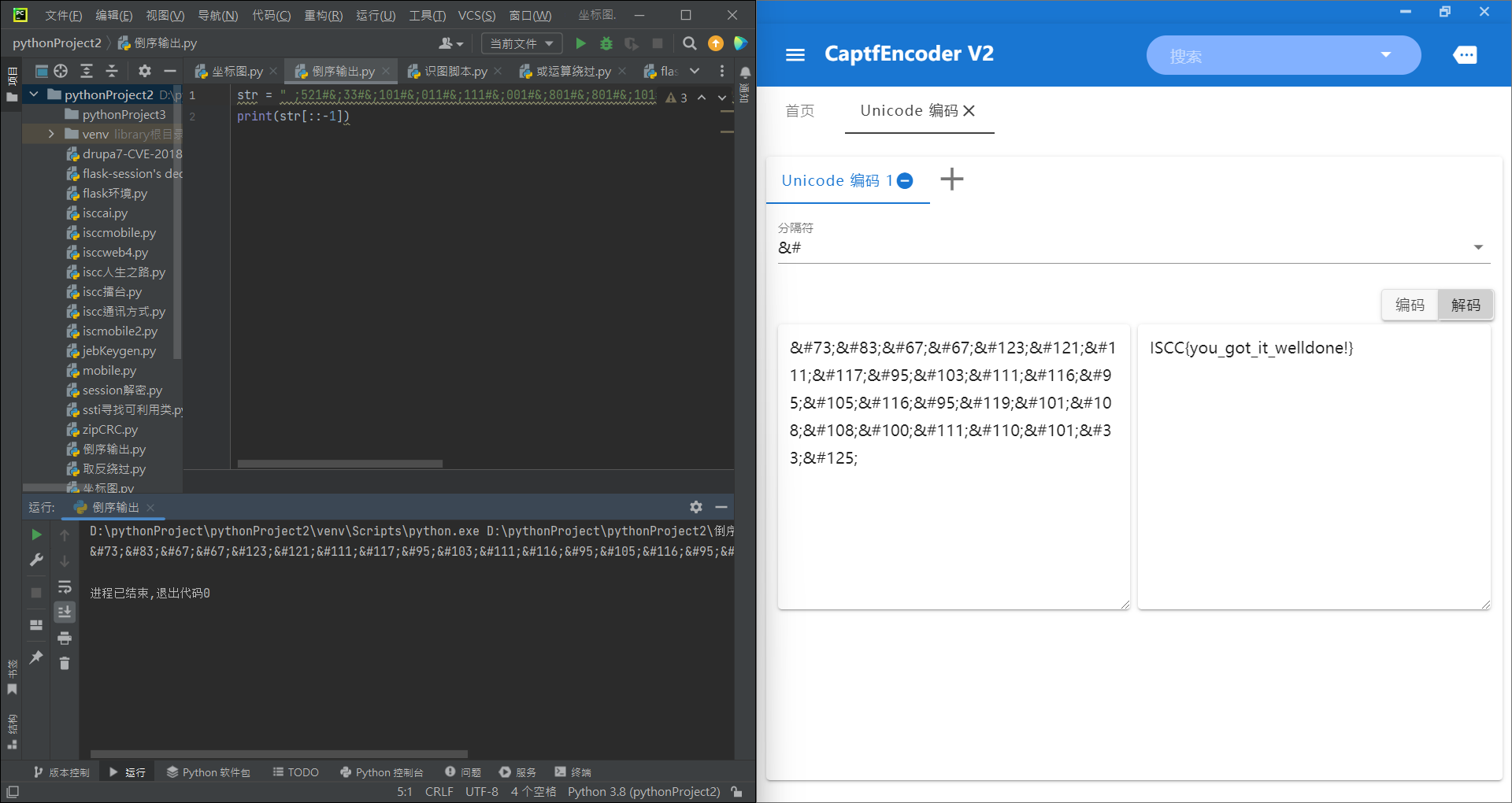
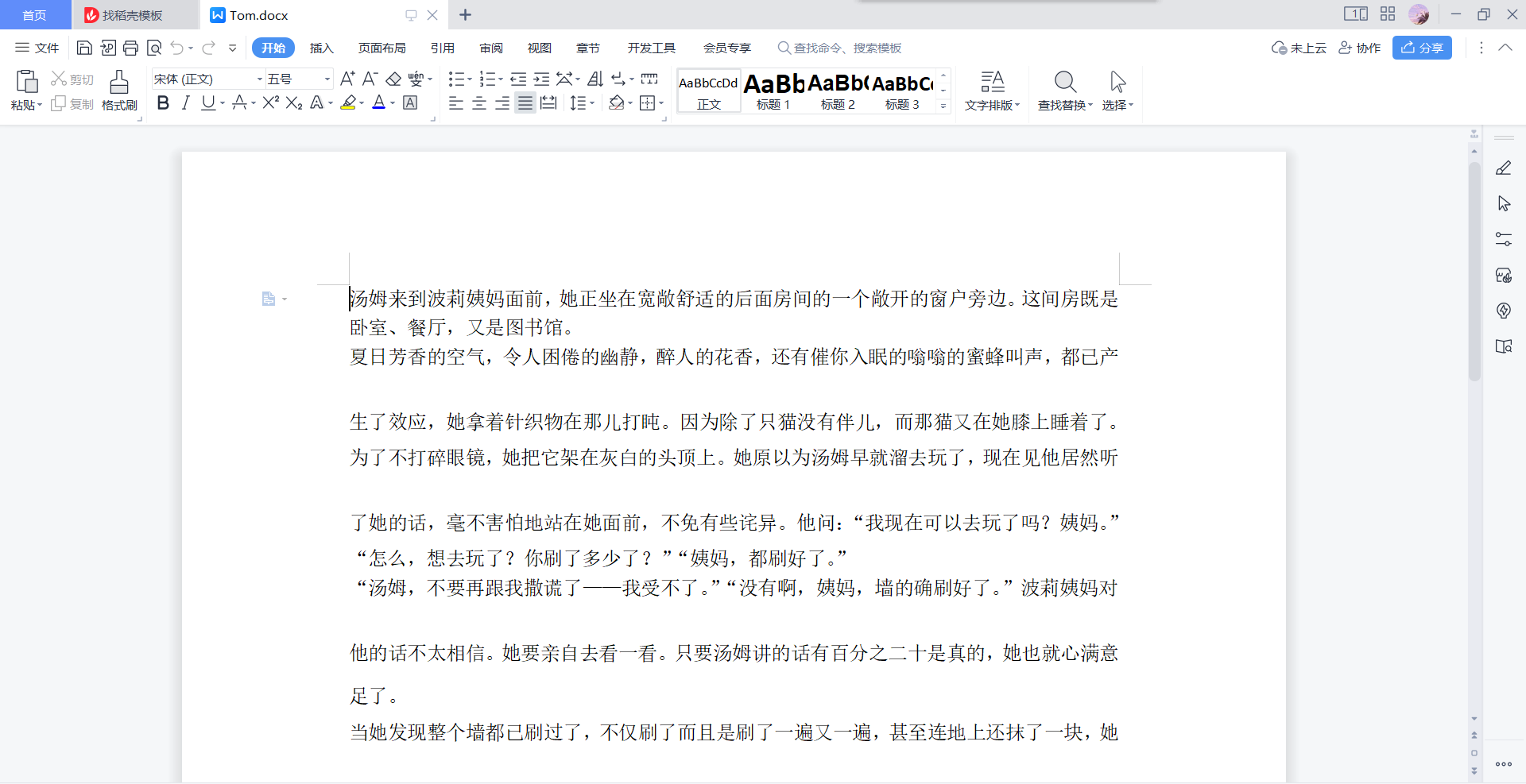
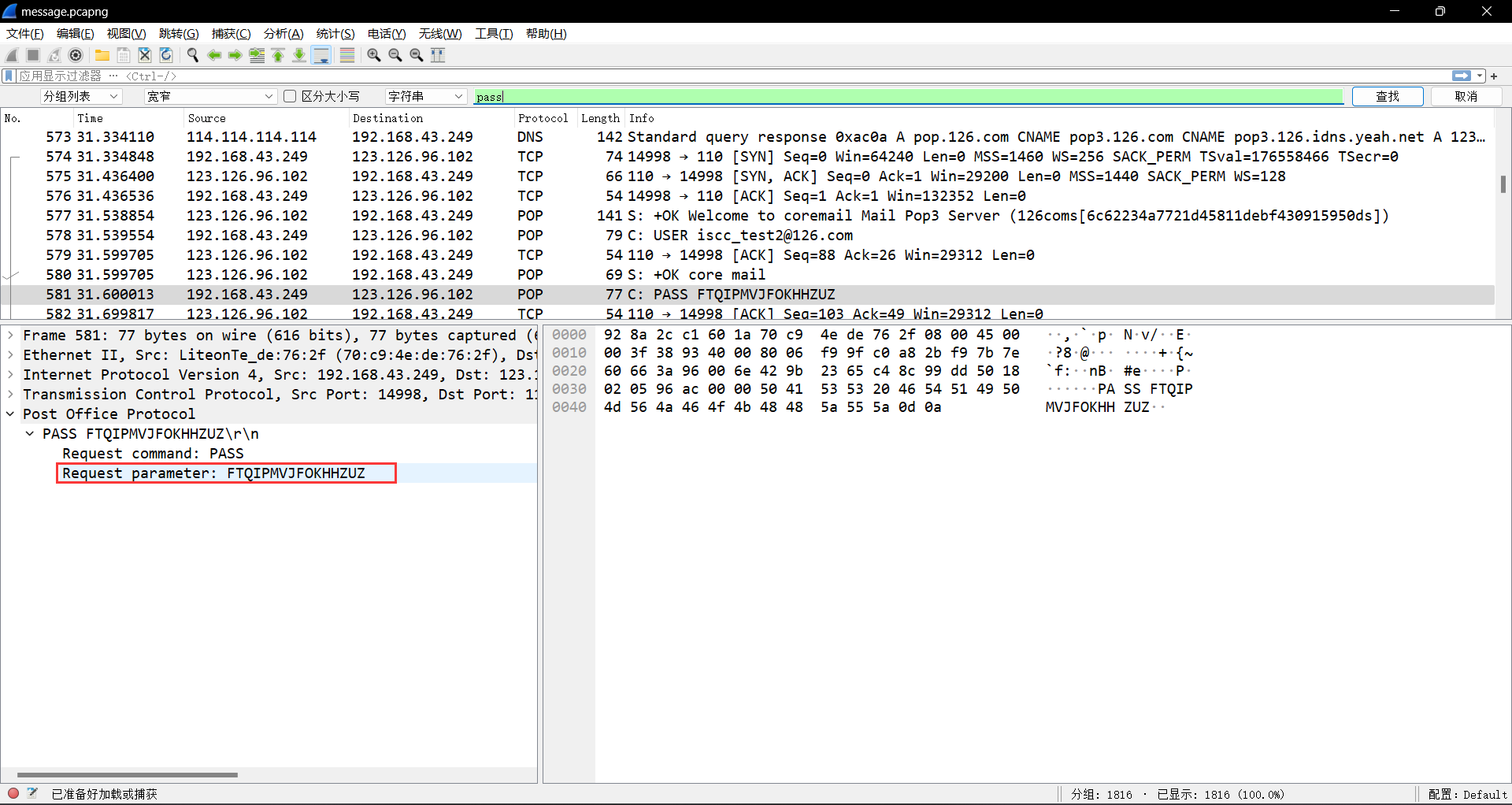
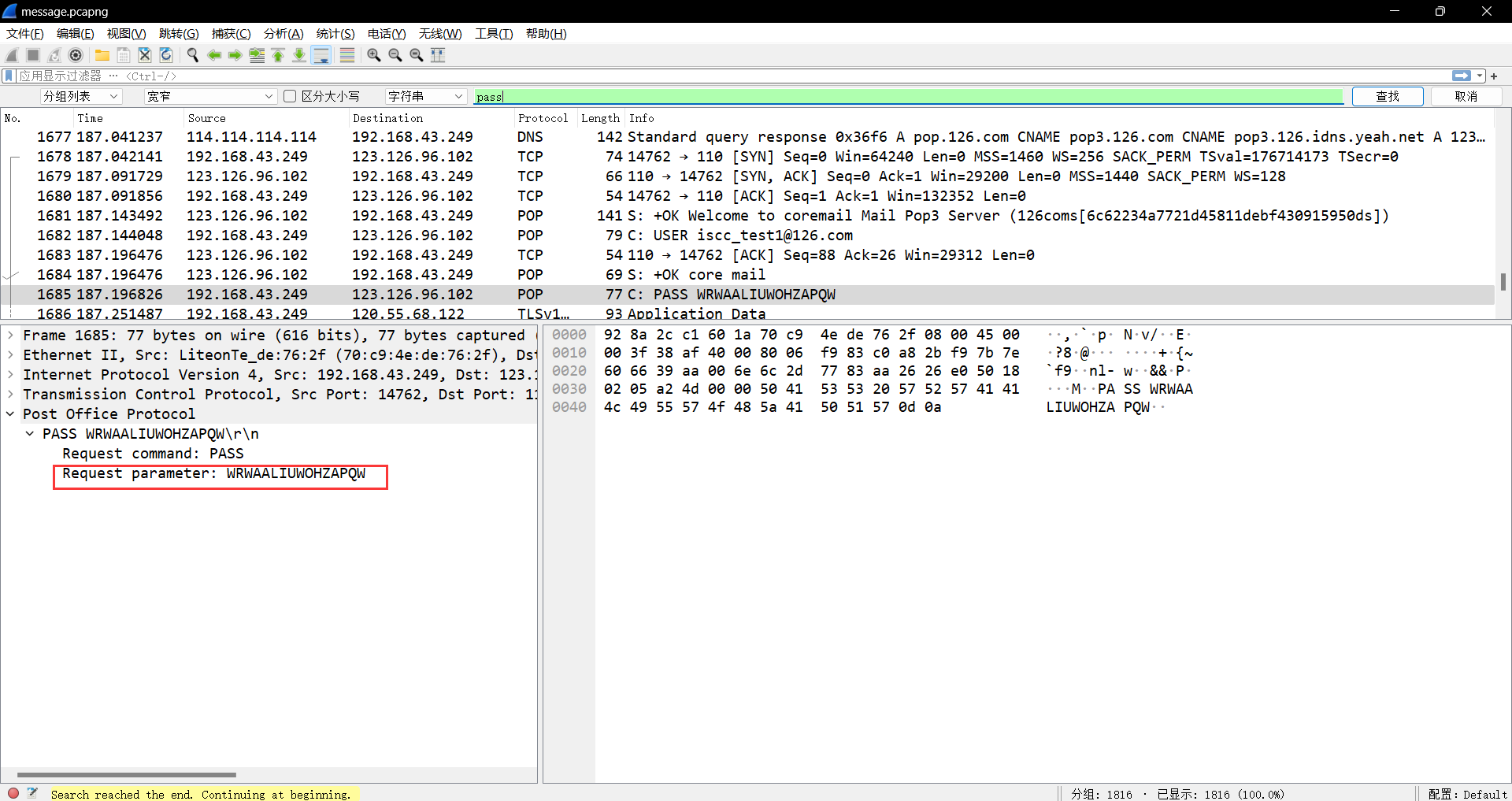
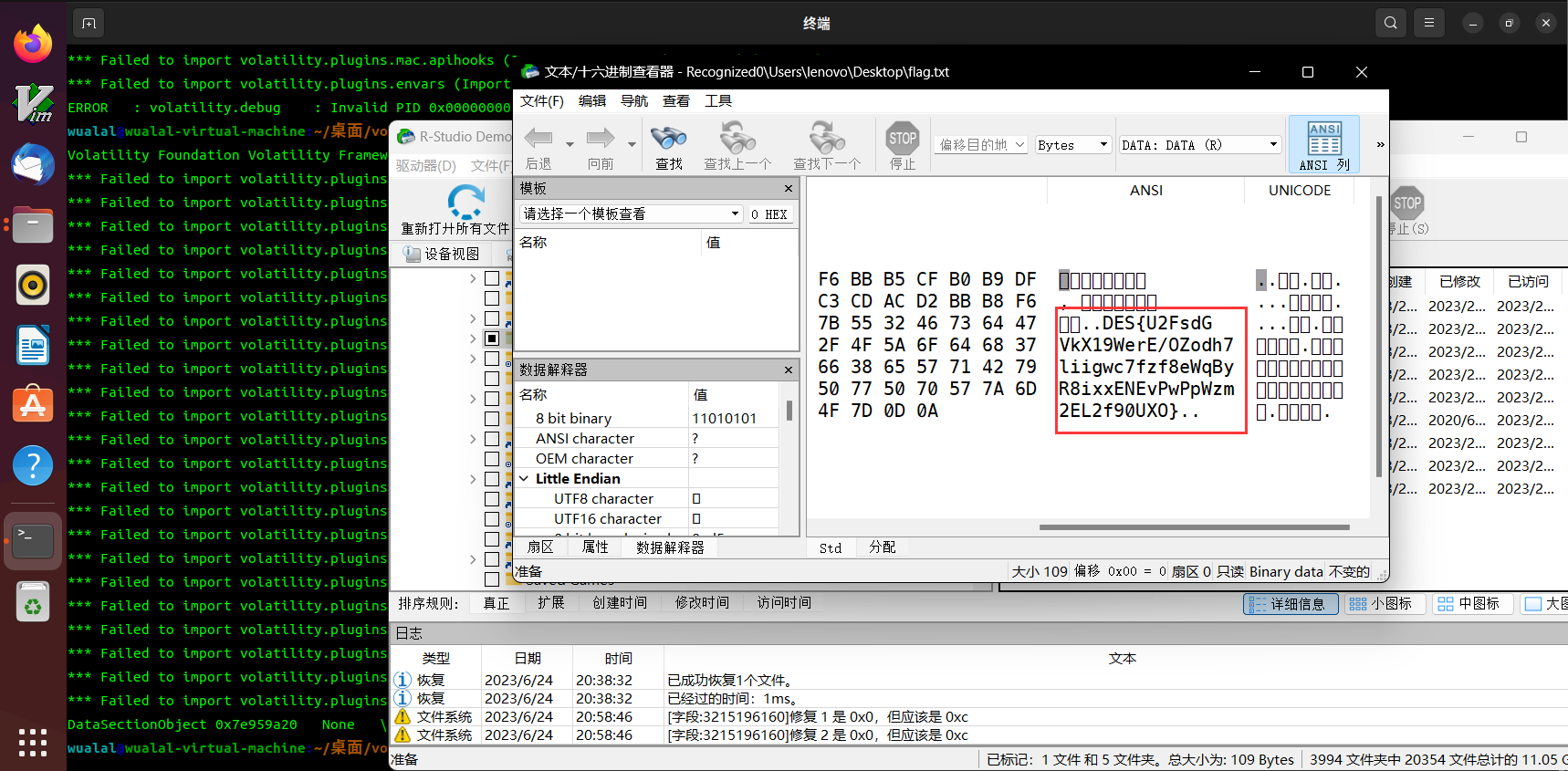
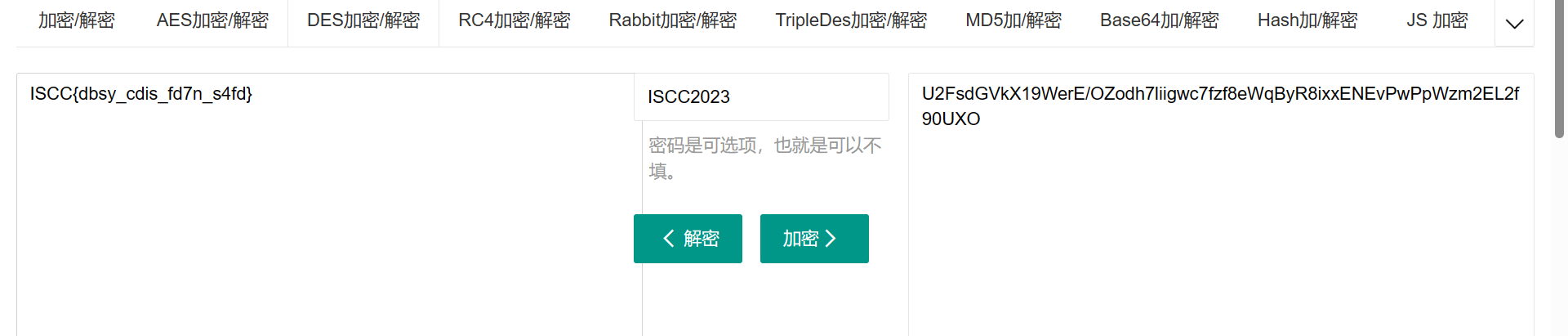
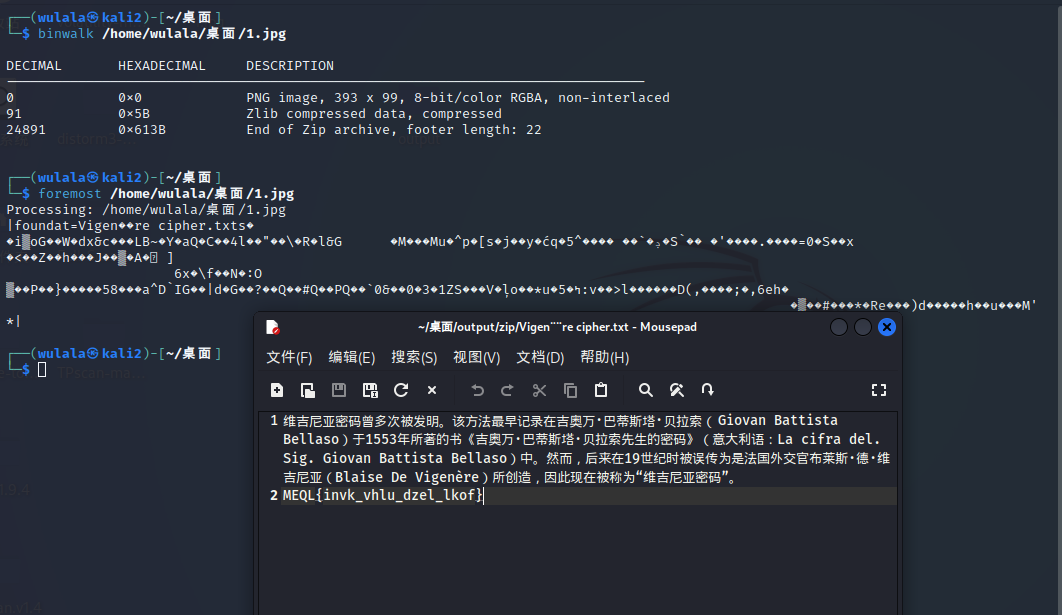
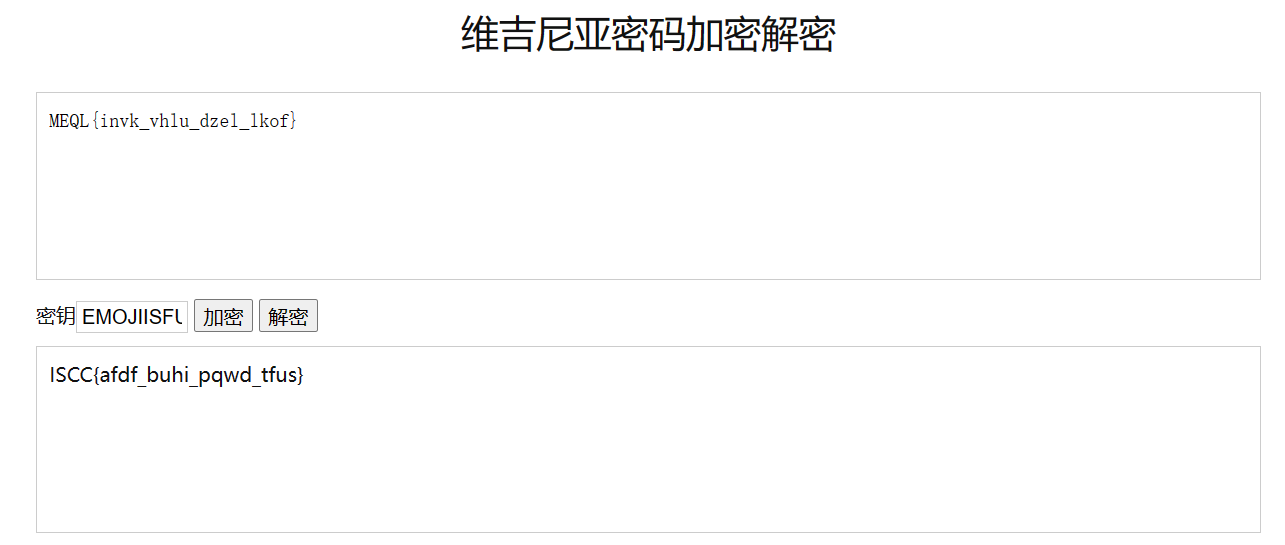
from collections import Counter import os ss="” str1 = ss result = Counter(str1) print("".join([i[0] for i in result.most_common()])) 这段代码的作用是统计字符串 ss 中每个字符出现的次数,并按照出现次数从高到低对这些字符进行排序,最后输出排序后的字符。 它首先导入了 Python 中的 collections 模块,并从中引入了 Counter 类。接着定义了一个字符串变量 ss,并将其赋值给变量 str1。然后使用 Counter 类构造函数 Counter(str1) 统计了字符串 str1 中每个字符出现的次数,并将结果存储在 result 变量中。接下来,使用了列表生成式 [i[0] for i in result.most_common()],获取了 result 中出现次数最多的字符(即出现次数排名前几的字符),并将它们连接成一个新的字符串。最后通过 print() 函数将这个新的字符串输出
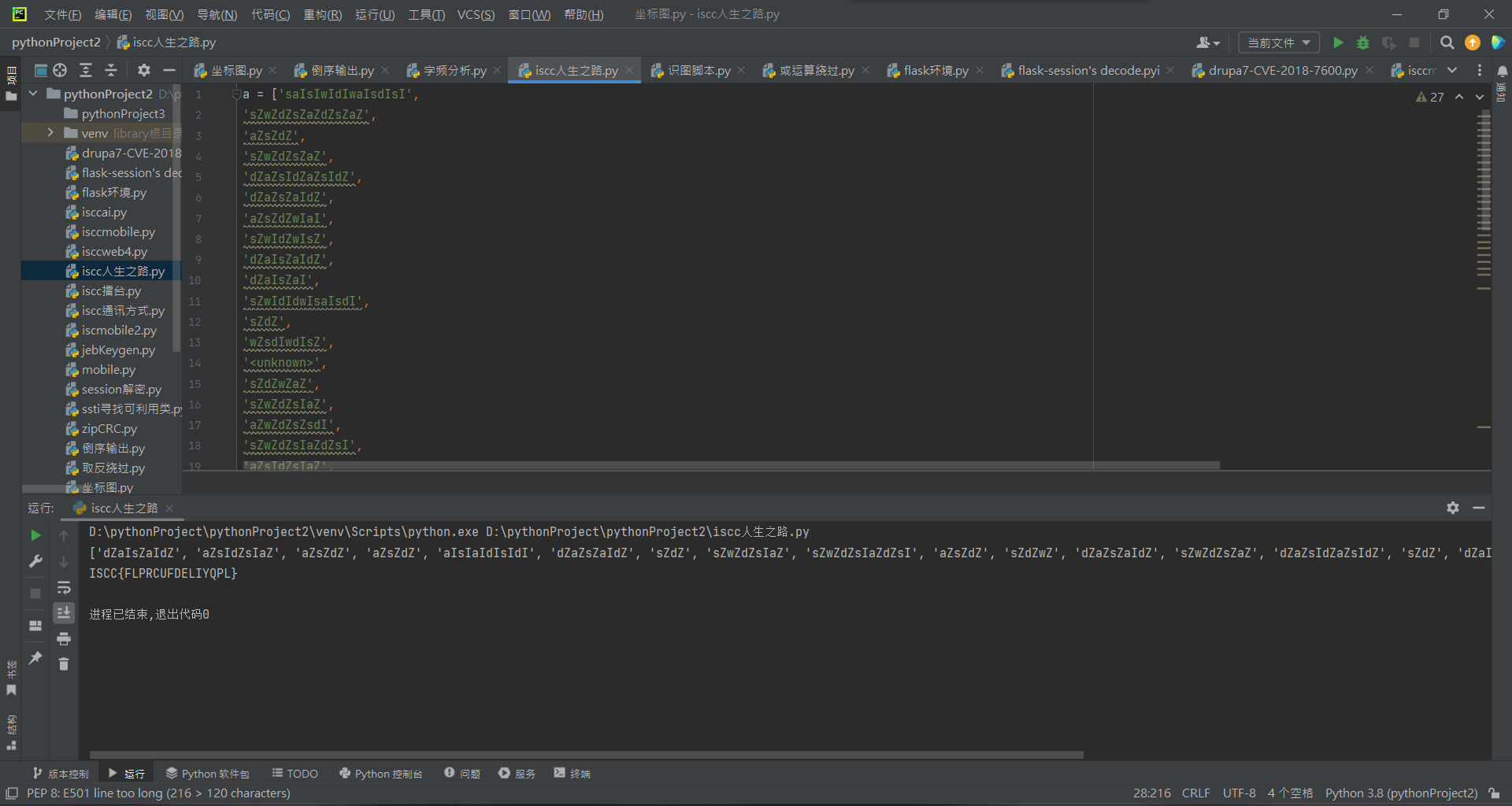
for i in c: for j in range(len(a)): if i == a[j]: flag += chr(j+0x41) break elif i == 'aIsIaIdIsIdI': flag += '{' break elif i == 'dIsIdIaIsIaI': flag += '}' break else: flag += '?'
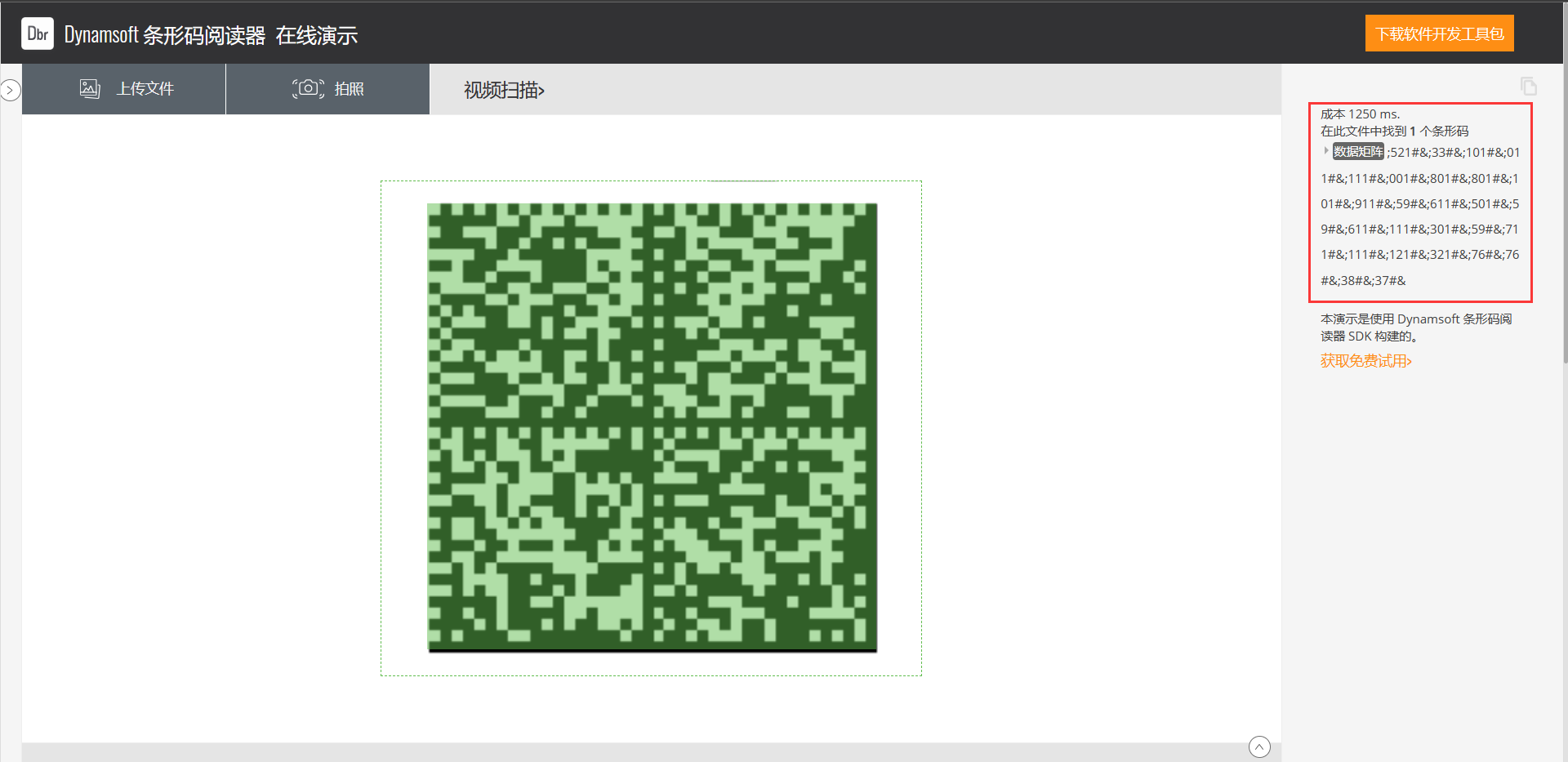
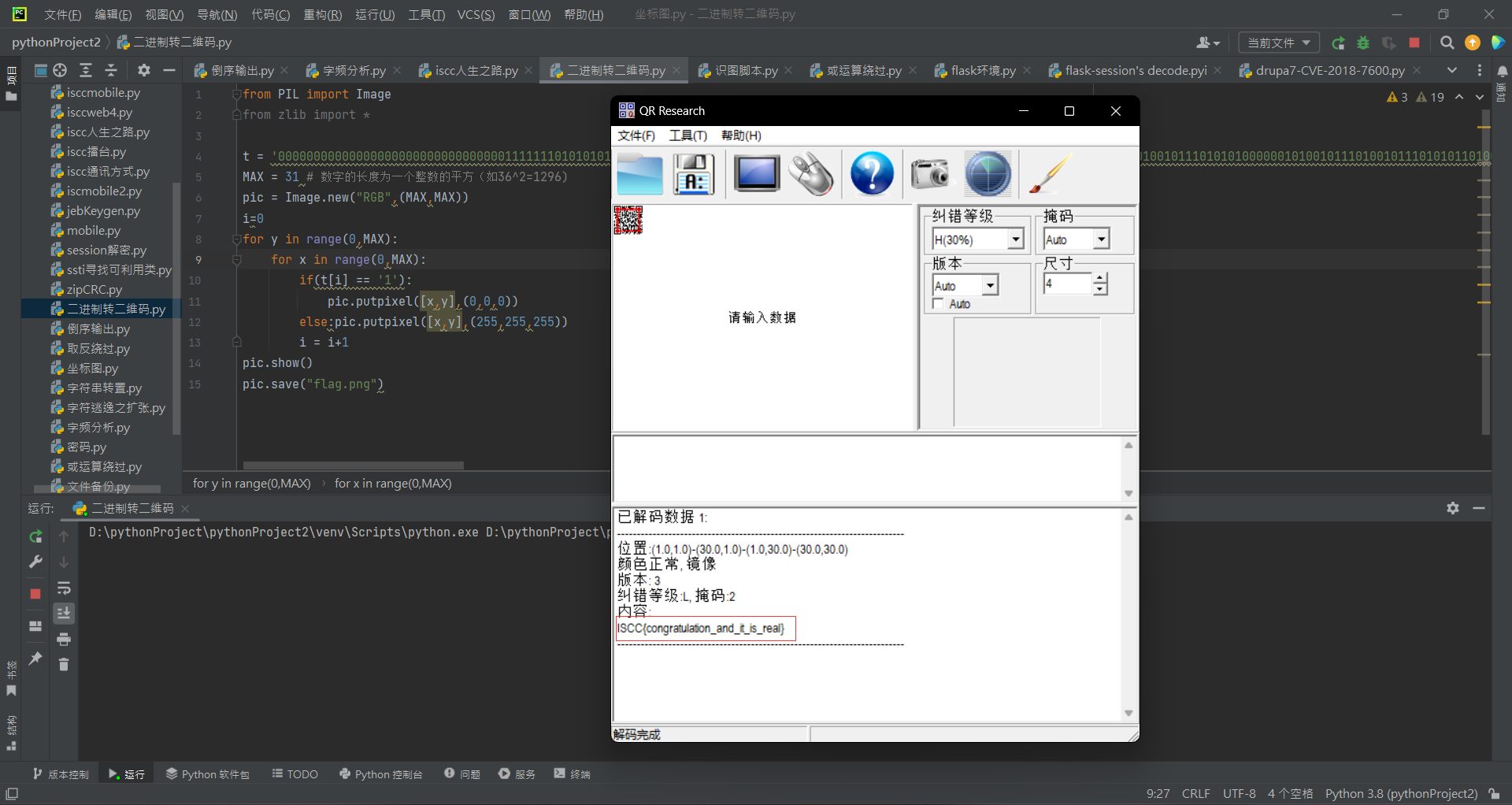
t = '0000000000000000000000000000000011111110101010111111101111111001000001011101011100000100000100101110101111000111110010111010010111010101000000101001011101001011101010110100101000101110100100000100010110000001010000010011111110101010101010101111111000000000010011001101000000000000010101101010101010111110111110011110000111111100010100101110000010111010010110110101101111000011100000011100000111000001110001001011101001011010010110100000000110100000111000001110000000001011101001011010010110100100010001101001100111011101010100001010011111010110011101001111100000011001100100001101100101000010100010011000010000011000100001011100001011001110110110100100101011100111110101111111101100000000000100001010110100010001001111111001000110010010101010000100000101101111001001000111110010111010011101110101111110101001011101010111011001101110101000101110100010111010101110111010010000010110011001000110011110001111111000010001000010010100000000000000000000000000000000000' MAX = 31 # 数字的长度为一个整数的平方(如36^2=1296) pic = Image.new("RGB",(MAX,MAX)) i=0 for y in range(0,MAX): for x in range(0,MAX): if(t[i] == '1'): pic.putpixel([x,y],(0,0,0)) else:pic.putpixel([x,y],(255,255,255)) i = i+1 pic.show() pic.save("flag.png")
通讯方式
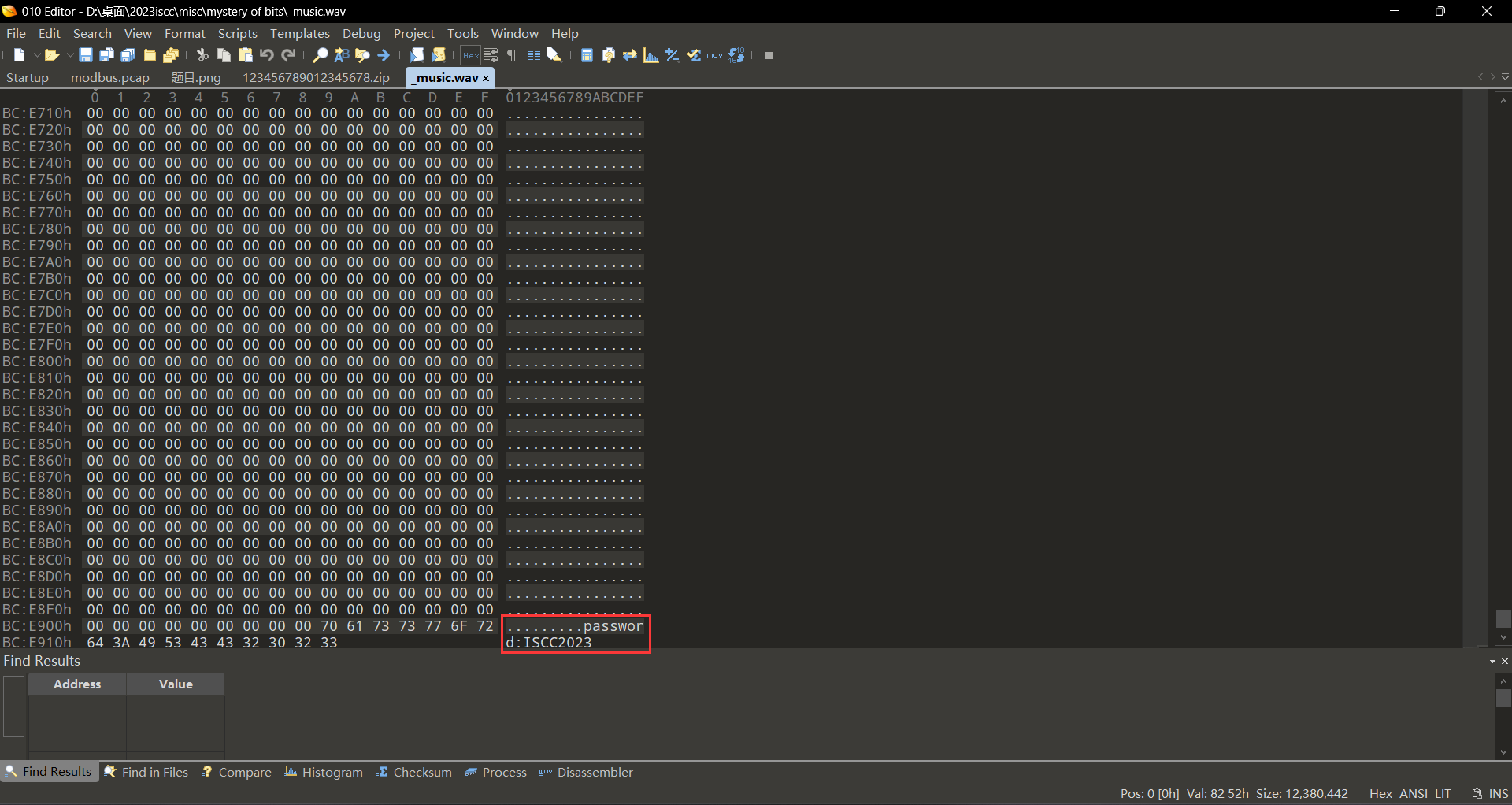
这题的考点在于左右声道差值的提取 exp1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
import scipy.io.wavfile as wavfile //从scipy.io包中导入模块wavfile并将其别名为wavfile。 samplerate, data = wavfile.read('telegram2wechat.wav') //使用wavfile.read()读取WAV文件'telegram2wechat.wav'。该函数返回两个值:音频文件的采样率(samplerate)和音频数据本身(data)。 left = [] right = [] //创建两个空列表来存储左右声道的音频数据。 for item in data: //循环遍历音频数据中的每个项目 left.append(item[0]) right.append(item[1]) //将item的第一个项目(左声道)附加到left列表中,并将item的第二个项目(右声道)附加到right列表中。 diff = [left - right for left, right in zip(left, right)] //使用列表推导式计算每个样本中左右声道之间的差异。 zip(left,right)创建来自left和right的相应项目对,表达式left-right从每个对中减去左声道值的右声道值。 print(diff)
fp = open('通讯.txt').read().split(',') //通过逗号分隔并获取结果列表的长度。 print(len(fp)) from PIL import Image img = Image.new('RGB', (49,49)) //Image.new 和for循环所需要的数字都为平方根得到的数字 i = 0 for x in range(49): for y in range(49): //然后它使用 PIL(Python Imaging Library)创建一个新的 RGB 图像,大小为 45x45,并遍历每个像素。 if fp[i] == ' 1': img.putpixel((x,y), (0,0,0)) else: img.putpixel((x,y), (255,255,255)) i += 1 //对于每个像素,它检查“fp”列表中相应的值是否等于“1”。如果是,则将像素设置为黑色(0,0,0),否则将其设置为白色(255,255,255)。最终生成的图像使用“show”方法显示出来。 img.show()
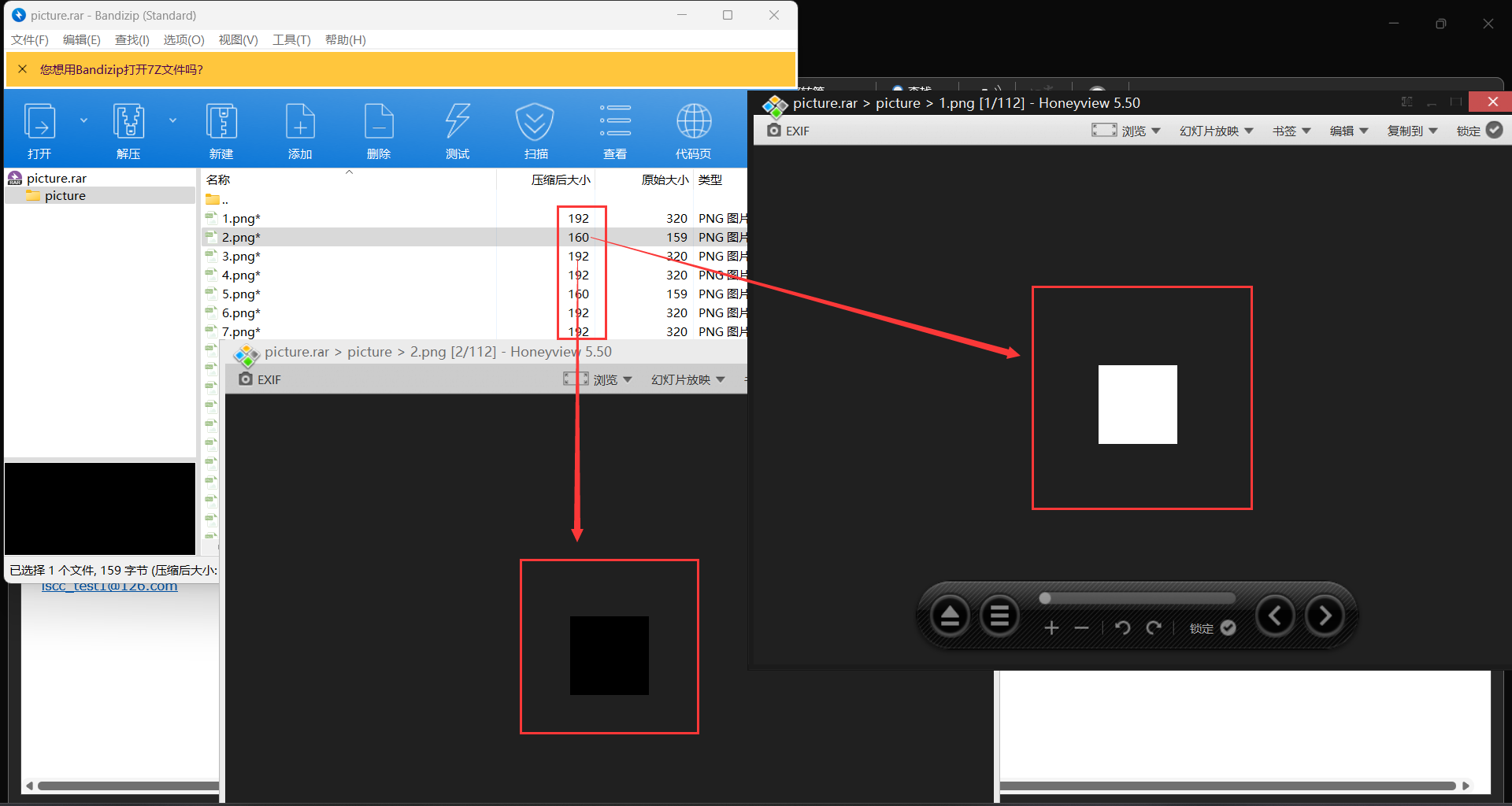
import cv2 t = "" for i in range(1,113): a = cv2.imread(str(i)+".png") a = list(a) if(str(a[0][0])=="[255 255 255]"): t+="0" else: t+="1" print(t) for i in range(0,len(t),8): flag = "" for j in range(8): flag += t[i+j] print(chr(int(flag,2)),end="")